来自吴恩达-course2 改善神经网络的第一周作业。
第一部分 初始化
plt.rcParams是一个字典。
import numpy as np
import matplotlib.pyplot as plt
import sklearn
import sklearn.datasets
import init_utils #第一部分,初始化
import reg_utils #第二部分,正则化
%matplotlib inline
plt.rcParams['figure.figsize'] = (7.0, 4.0) # set default size of plots
plt.rcParams['image.interpolation'] = 'nearest'
plt.rcParams['image.cmap'] = 'gray'
接下来看看我们的训练集和测试集长什么样。
train_X, train_Y, test_X, test_Y = init_utils.load_dataset(is_plot=True)
现在建立总模型,具体涉及到的各种初始化可以之后再定义。(python中可以先调用再定义函数。)
def model(X,Y,learning_rate=0.01,num_iterations=15000,print_cost=True,initialization="he",is_polt=True):
"""
实现一个三层的神经网络:LINEAR ->RELU -> LINEAR -> RELU -> LINEAR -> SIGMOID
参数:
X - 输入的数据,维度为(2, 要训练/测试的数量)
Y - 标签,【0 | 1】,维度为(1,对应的是输入的数据的标签)
learning_rate - 学习速率
num_iterations - 迭代的次数
print_cost - 是否打印成本值,每迭代1000次打印一次
initialization - 字符串类型,初始化的类型【"zeros" | "random" | "he"】
is_polt - 是否绘制梯度下降的曲线图
返回
parameters - 学习后的参数
"""
costs=[]
layers_dims=[X.shape[0],20,5,1]
if initialization=="zeros":
parameters=initialize_parameters_zeros(layers_dims)
elif initialization=="random":
parameters=initialize_parameters_random(layers_dims)
elif initialization=="he":
parameters=initialize_parameters_he(layers_dims)
else:
print("Wrong initialization!")
for i in range(num_iterations):
A3,cache=init_utils.forward_propagation(X, parameters)
cost=init_utils.compute_loss(A3,Y)
grads=init_utils.backward_propagation(X, Y, cache)
parameters=init_utils.update_parameters(parameters, grads, learning_rate)
if i%1000==0:
costs.append(cost)
if print_cost:
print("当前迭代"+str(i)+"次,成本值为"+str(cost))
if is_polt:
plt.plot(costs)
plt.ylabel('cost')
plt.xlabel('iterations (per hundreds)')
plt.title("Learning rate =" + str(learning_rate))
plt.show()
return parameters
1.1 零初始化
def initialize_parameters_zeros(layers_dims):
"""
将模型的参数全部设置为0
参数:
layers_dims - 列表,模型的层数和对应每一层的节点的数量
返回
parameters - 包含了所有W和b的字典
W1 - 权重矩阵,维度为(layers_dims[1], layers_dims[0])
b1 - 偏置向量,维度为(layers_dims[1],1)
···
WL - 权重矩阵,维度为(layers_dims[L], layers_dims[L -1])
bL - 偏置向量,维度为(layers_dims[L],1)
"""
parameters={}
L=len(layers_dims) #包含输入层
for l in range(1,L):
parameters["W"+str(l)]=np.zeros((layers_dims[l],layers_dims[l-1]))
parameters["b"+str(l)]=np.zeros((layers_dims[l],1))
assert(parameters["W"+str(l)].shape==(layers_dims[l],layers_dims[l-1]))
assert(parameters["b"+str(l)].shape==(layers_dims[l],1))
return parameters
parameters= model(train_X,train_Y,learning_rate=0.01,num_iterations=15000,print_cost=True,initialization="zeros",is_polt=True)
结果如下:
当前迭代0次,成本值为0.6931471805599453
当前迭代1000次,成本值为0.6931471805599453
当前迭代2000次,成本值为0.6931471805599453
当前迭代3000次,成本值为0.6931471805599453
当前迭代4000次,成本值为0.6931471805599453
当前迭代5000次,成本值为0.6931471805599453
当前迭代6000次,成本值为0.6931471805599453
当前迭代7000次,成本值为0.6931471805599453
当前迭代8000次,成本值为0.6931471805599453
当前迭代9000次,成本值为0.6931471805599453
当前迭代10000次,成本值为0.6931471805599455
当前迭代11000次,成本值为0.6931471805599453
当前迭代12000次,成本值为0.6931471805599453
当前迭代13000次,成本值为0.6931471805599453
当前迭代14000次,成本值为0.6931471805599453

1.2 随机初始化
w[l]乘10之后进一步放大了随机初始化的弊端。
def initialize_parameters_random(layers_dims):
"""
参数:
layers_dims - 列表,模型的层数和对应每一层的节点的数量
返回
parameters - 包含了所有W和b的字典
W1 - 权重矩阵,维度为(layers_dims[1], layers_dims[0])
b1 - 偏置向量,维度为(layers_dims[1],1)
···
WL - 权重矩阵,维度为(layers_dims[L], layers_dims[L -1])
b1 - 偏置向量,维度为(layers_dims[L],1)
"""
np.random.seed(3) # 指定随机种子
parameters = {}
L = len(layers_dims)
for l in range(1,L):
parameters["W"+str(l)]=np.random.randn(layers_dims[l],layers_dims[l-1])*10
parameters["b"+str(l)]=np.zeros((layers_dims[l],1))
assert(parameters["W"+str(l)].shape==(layers_dims[l],layers_dims[l-1]))
assert(parameters["b"+str(l)].shape==(layers_dims[l],1))
return parameters
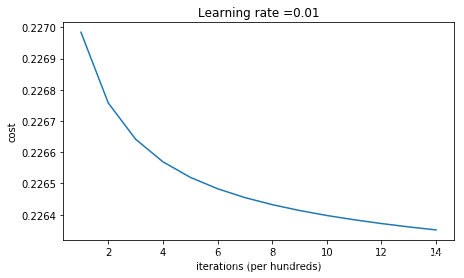
parameters = model(train_X, train_Y, initialization = "random",is_polt=True)
print("训练集:")
predictions_train = init_utils.predict(train_X, train_Y, parameters)
print("测试集:")
predictions_test = init_utils.predict(test_X, test_Y, parameters)
print(predictions_train)
print(predictions_test)
当前迭代1000次,成本值为0.2269842220163766
当前迭代2000次,成本值为0.22675774800041695
当前迭代3000次,成本值为0.22664179436419726
当前迭代4000次,成本值为0.22656944396406933
当前迭代5000次,成本值为0.22651974550065535
当前迭代6000次,成本值为0.22648318559683067
当前迭代7000次,成本值为0.2264548017574637
当前迭代8000次,成本值为0.2264322978084449
当前迭代9000次,成本值为0.22641344492852125
当前迭代10000次,成本值为0.2263974907297374
当前迭代11000次,成本值为0.2263837215869015
当前迭代12000次,成本值为0.22637164354385497
当前迭代13000次,成本值为0.22636090346787713
当前迭代14000次,成本值为0.22635124196239997
训练集:
Accuracy: 0.8433333333333334
测试集:
Accuracy: 0.81
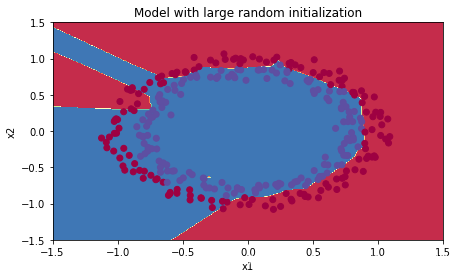
plt.title("Model with large random initialization")
axes = plt.gca()
axes.set_xlim([-1.5, 1.5])
axes.set_ylim([-1.5, 1.5])
init_utils.plot_decision_boundary(lambda x: init_utils.predict_dec(parameters, x.T), train_X, train_Y)
1.3 抑梯度异常初始化
def initialize_parameters_he(layers_dims):
"""
参数:
layers_dims - 列表,模型的层数和对应每一层的节点的数量
返回
parameters - 包含了所有W和b的字典
W1 - 权重矩阵,维度为(layers_dims[1], layers_dims[0])
b1 - 偏置向量,维度为(layers_dims[1],1)
···
WL - 权重矩阵,维度为(layers_dims[L], layers_dims[L -1])
b1 - 偏置向量,维度为(layers_dims[L],1)
"""
np.random.seed(3) # 指定随机种子
parameters = {}
L = len(layers_dims)
for l in range(1,L):
parameters["W"+str(l)]=np.random.randn(layers_dims[l],layers_dims[l-1])*np.sqrt(2/layers_dims[l-1])
parameters["b"+str(l)]=np.zeros((layers_dims[l],1))
assert(parameters["W"+str(l)].shape==(layers_dims[l],layers_dims[l-1]))
assert(parameters["b"+str(l)].shape==(layers_dims[l],1))
return parameters
parameters = model(train_X, train_Y, initialization = "he",is_polt=True)
print("训练集:")
predictions_train = init_utils.predict(train_X, train_Y, parameters)
print("测试集:")
init_utils.predictions_test = init_utils.predict(test_X, test_Y, parameters)
当前迭代0次,成本值为0.7319554375028876
当前迭代1000次,成本值为0.6747281064402342
当前迭代2000次,成本值为0.6375001490558371
当前迭代3000次,成本值为0.5716245654498704
当前迭代4000次,成本值为0.45195099494827806
当前迭代5000次,成本值为0.3132397519838676
当前迭代6000次,成本值为0.21211829629292167
当前迭代7000次,成本值为0.15334402667544578
当前迭代8000次,成本值为0.11667245628511977
当前迭代9000次,成本值为0.09440875802120806
当前迭代10000次,成本值为0.08024950701438607
当前迭代11000次,成本值为0.07000908218591473
当前迭代12000次,成本值为0.06095001136673652
当前迭代13000次,成本值为0.05485280988658827
当前迭代14000次,成本值为0.050193637786923886
训练集:
Accuracy: 0.99
测试集:
Accuracy: 0.94
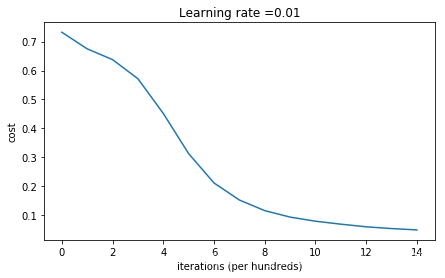
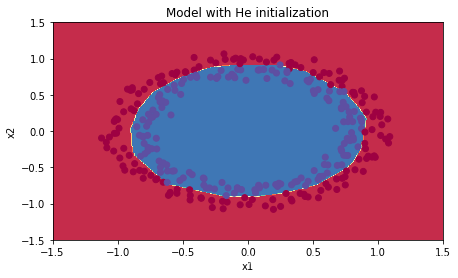
plt.title("Model with He initialization")
axes = plt.gca()
axes.set_xlim([-1.5, 1.5])
axes.set_ylim([-1.5, 1.5])
init_utils.plot_decision_boundary(lambda x: init_utils.predict_dec(parameters, x.T), train_X, train_Y)
第二部分 正则化
对于一个模型而言,如果训练集表现不佳,则为高偏差,可以用更大的神经网络或者更长的训练时间;如果测试集表现不佳,则为高方差,可以用更多的数据或者正则化。这个实验中尝试了L2正则化和dropout正则化。
同样地,先写总模型。这个模型是三层网络,激活函数分别为relu,relu和sigmoid,两个隐藏层和一个输出层的节点数都已经确定。
从model中也可以看出,L2和dropout正则化是由参数lambd和keep_prob决定的。L2正则化影响cost的计算和后向传播;dropout正则化影响前向传播和后向传播。
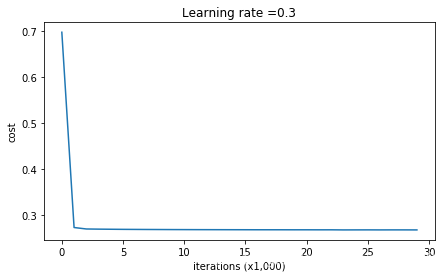
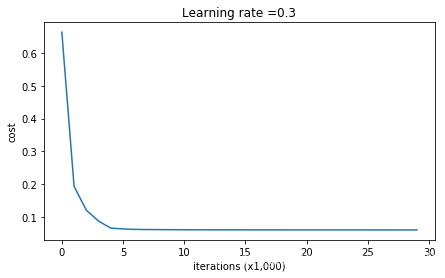
def model(X,Y,learning_rate=0.3,num_iterations=30000,print_cost=True,is_plot=True,lambd=0,keep_prob=1):
"""
实现一个三层的神经网络:LINEAR ->RELU -> LINEAR -> RELU -> LINEAR -> SIGMOID
参数:
X - 输入的数据,维度为(2, 要训练/测试的数量)
Y - 标签,【0(蓝色) | 1(红色)】,维度为(1,对应的是输入的数据的标签)
learning_rate - 学习速率
num_iterations - 迭代的次数
print_cost - 是否打印成本值,每迭代10000次打印一次,但是每1000次记录一个成本值
is_polt - 是否绘制梯度下降的曲线图
lambd - 正则化的超参数,实数
keep_prob - 随机删除节点的概率
返回
parameters - 学习后的参数
"""
costs=[]
grads={}
layer_dims=[X.shape[0],20,3,1]
parameters=reg_utils.initialize_parameters(layer_dims)
assert(lambd!=0 and keep_prob!=1)==False
for i in range(num_iterations):
if keep_prob<1:
a3,cache=forward_propagation_with_dropout(X,parameters,keep_prob)
elif keep_prob==1:
a3,cache=reg_utils.forward_propagation(X,parameters)
else:
print("keep_prob参数输入错误!")
exit
if lambd==0:
cost=reg_utils.compute_cost(a3,Y)
else:
cost=compute_cost_with_regularization(a3,Y,parameters,lambd)
if lambd!=0:
grads = backward_propagation_with_regularization(X, Y, cache, lambd)
elif keep_prob<1:
grads = backward_propagation_with_dropout(X, Y, cache, keep_prob)
else:
grads=reg_utils.backward_propagation(X, Y, cache)
parameters=reg_utils.update_parameters(parameters, grads, learning_rate)
if i % 1000 == 0:
costs.append(cost)
if (print_cost and i % 10000 == 0):
print("第" + str(i) + "次迭代,成本值为:" + str(cost))
if is_plot:
plt.plot(costs)
plt.ylabel('cost')
plt.xlabel('iterations (x1,000)')
plt.title("Learning rate =" + str(learning_rate))
plt.show()
return parameters
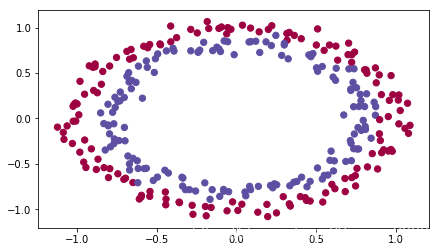
再看看我们的数据集。
train_X, train_Y, test_X, test_Y = reg_utils.load_2D_dataset(is_plot=True)
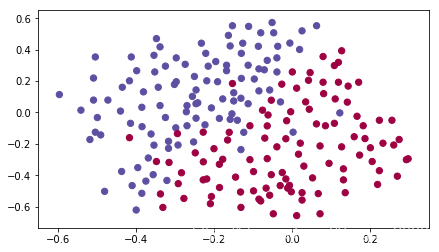
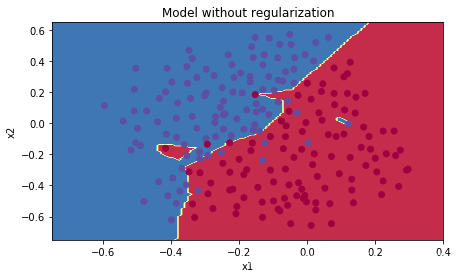
2.1 不正则化
parameters = model(tr
ain_X, train_Y,is_plot=True)
print("训练集:")
predictions_train = reg_utils.predict(train_X, train_Y, parameters)
print("测试集:")
predictions_test = reg_utils.predict(test_X, test_Y, parameters)
第0次迭代,成本值为:0.6557412523481002
第10000次迭代,成本值为:0.16329987525724196
第20000次迭代,成本值为:0.13851642423253843
训练集:
Accuracy: 0.9478672985781991
测试集:
Accuracy: 0.915
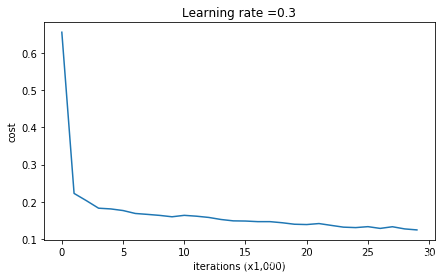
plt.title("Model without regularization")
axes = plt.gca()
axes.set_xlim([-0.75,0.40])
axes.set_ylim([-0.75,0.65])
reg_utils.plot_decision_boundary(lambda x: reg_utils.predict_dec(parameters, x.T), train_X, train_Y)
2.2 L2正则化
2.2.1 损失函数
def compute_cost_with_regularization(A3,Y,parameters,lambd):
"""
实现公式2的L2正则化计算成本
参数:
A3 - 正向传播的输出结果,维度为(输出节点数量,训练/测试的数量)
Y - 标签向量,与数据一一对应,维度为(输出节点数量,训练/测试的数量)
parameters - 包含模型学习后的参数的字典
返回:
cost - 使用公式2计算出来的正则化损失的值
"""
m=Y.shape[1]
L=len(parameters)//2 #不包括输入层
cross_entropy_cost=reg_utils.compute_cost(A3,Y)
L2_regular_cost=0
for l in range(L):
L2_regular_cost+=np.sum(np.square(parameters["W"+str(l+1)]))*lambd/(2*m)
cost=cross_entropy_cost+L2_regular_cost
return cost
看一下用来计算交叉熵损失的reg_util.compute_cost:
def compute_cost(a3, Y):
"""
Implement the cost function
Arguments:
a3 -- post-activation, output of forward propagation
Y -- "true" labels vector, same shape as a3
Returns:
cost - value of the cost function
"""
m = Y.shape[1]
logprobs = np.multiply(-np.log(a3),Y) + np.multiply(-np.log(1 - a3), 1 - Y)
cost = 1./m * np.nansum(logprobs)
return cost
可见损失函数天然就是一个小于零的实数,加上每一层的F范数后,绝对值变小了。
2.2.2 后向传播
def backward_propagation_with_regularization(X, Y, cache, lambd):
"""
实现我们添加了L2正则化的模型的后向传播。
参数:
X - 输入数据集,维度为(输入节点数量,数据集里面的数量)
Y - 标签,维度为(输出节点数量,数据集里面的数量)
cache - 来自forward_propagation()的cache输出
lambda - regularization超参数,实数
返回:
gradients - 一个包含了每个参数、激活值和预激活值变量的梯度的字典
"""
(z1, a1, W1, b1, z2, a2, W2, b2, z3, a3, W3, b3)=cache
L=len(parameters)//2
m=Y.shape[1]
assert(X.shape[1]==Y.shape[1])
gradients=reg_utils.backward_propagation(X, Y, cache)
assert(gradients["dW1"].shape==W1.shape)
assert(gradients["dW2"].shape==W2.shape)
assert(gradients["dW3"].shape==W3.shape)
gradients["dW1"]+=lambd/m*W1
gradients["dW2"]+=lambd/m*W2
gradients["dW3"]+=lambd/m*W3
return gradients
L2正则化使梯度变了,所以在更新W[l]时,原W[l]的系数更小了。W[l]的系数变小意味着函数更加简单,也就减少了过度拟合。以tanh(Z)为例,W越小,Z越小,函数就越接近于线性。
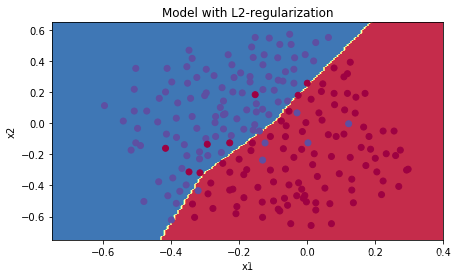
2.2.3 结果
parameters = model(train_X, train_Y, lambd=0.7,is_plot=True)
print("使用正则化,训练集:")
predictions_train = reg_utils.predict(train_X, train_Y, parameters)
print("使用正则化,测试集:")
predictions_test = reg_utils.predict(test_X, test_Y, parameters)
第0次迭代,成本值为:0.6974484493131264
第10000次迭代,成本值为:0.2684918873282239
第20000次迭代,成本值为:0.2680916337127301
使用正则化,训练集:
Accuracy: 0.9383886255924171
使用正则化,测试集:
Accuracy: 0.93
plt.title("Model with L2-regularization")
axes = plt.gca()
axes.set_xlim([-0.75,0.40])
axes.set_ylim([-0.75,0.65])
reg_utils.plot_decision_boundary(lambda x: reg_utils.predict_dec(parameters, x.T), train_X, train_Y)
2.2 dropout正则化
2.2.1 前向传播
每个隐藏层对应的A[l]都有了一个同样大小的D[l],它们也会保存在cache中,在后向传播中用得到。D[l]的元素先是0-1的随机数,然后是按照概率的0/1,然后用A和D逐元素相乘来随机去掉A的一些元素。
def forward_propagation_with_dropout(X,parameters,keep_prob=0.5):
"""
实现具有随机舍弃节点的前向传播。
LINEAR -> RELU + DROPOUT -> LINEAR -> RELU + DROPOUT -> LINEAR -> SIGMOID.
参数:
X - 输入数据集,维度为(2,示例数)
parameters - 包含参数“W1”,“b1”,“W2”,“b2”,“W3”,“b3”的python字典:
W1 - 权重矩阵,维度为(20,2)
b1 - 偏向量,维度为(20,1)
W2 - 权重矩阵,维度为(3,20)
b2 - 偏向量,维度为(3,1)
W3 - 权重矩阵,维度为(1,3)
b3 - 偏向量,维度为(1,1)
keep_prob - 随机删除的概率,实数
返回:
A3 - 最后的激活值,维度为(1,1),正向传播的输出
cache - 存储了一些用于计算反向传播的数值的元组
"""
np.random.seed(1)
W1=parameters["W1"]
W2=parameters["W2"]
W3=parameters["W3"]
b1=parameters["b1"]
b2=parameters["b2"]
b3=parameters["b3"]
Z1=np.dot(W1,X)+b1
A1=reg_utils.relu(Z1)
D1=np.random.rand(A1.shape[0],A1.shape[1])
D1=D1<keep_prob
A1=A1*D1
Z2=np.dot(W2,A1)+b2
A2=reg_utils.relu(Z2)
D2=np.random.rand(A2.shape[0],A2.shape[1])
D2=D2<keep_prob
A2=A2*D2
Z3=np.dot(W3,A2)+b3
A3=reg_utils.sigmoid(Z3)
cache = (Z1, D1, A1, W1, b1, Z2, D2, A2, W2, b2, Z3, A3, W3, b3)
return A3,cache
2.2.2 后向传播
np.int64(A2>0)算的是第二层激活函数的导数,也就是g2’(Z2),不过第二层激活函数是relu,A2的元素大于零处导数为1,等于零处导数为0。
def backward_propagation_with_dropout(X,Y,cache,keep_prob):
"""
实现我们随机删除的模型的后向传播。
参数:
X - 输入数据集,维度为(2,示例数)
Y - 标签,维度为(输出节点数量,示例数量)
cache - 来自forward_propagation_with_dropout()的cache输出
keep_prob - 随机删除的概率,实数
返回:
gradients - 一个关于每个参数、激活值和预激活变量的梯度值的字典
"""
m=X.shape[1]
(Z1, D1, A1, W1, b1, Z2, D2, A2, W2, b2, Z3, A3, W3, b3)=cache
dZ3=A3-Y
dW3=(1/m)*np.dot(dZ3,A2.T)
db3=(1/m)*np.sum(dZ3,axis=1,keepdims=True)
dA2=np.dot(W3.T,dZ3)
dA2=dA2*D2
dA2/=keep_prob
dZ2=np.multiply(dA2,np.int64(A2>0))
dW2=(1/m)*np.dot(dZ2,A1.T)
db2=(1/m)*np.sum(dZ2,axis=1,keepdims=True)
dA1=np.dot(W2.T,dZ2)
dA1=dA1*D1
dA1/=keep_prob
dZ1=np.multiply(dA1,np.int64(A1>0))
dW1=(1/m)*np.dot(dZ1,X.T)
db1=(1/m)*np.sum(dZ1,axis=1,keepdims=True)
gradients={"dW1":dW1,"dW2":dW2,"dW3":dW3,"db1":db1,"db2":db2,"db3":db3,"dZ1":dZ1,"dZ2":dZ2,"dZ3":dZ3}
return gradients
2.2.3 结果
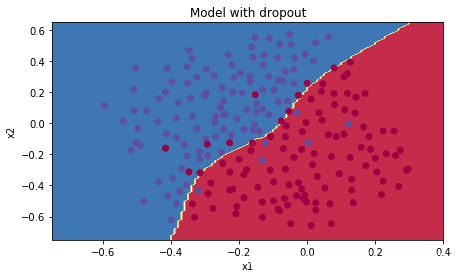
parameters = model(train_X, train_Y, keep_prob=0.86, learning_rate=0.3,is_plot=True)
print("使用随机删除节点,训练集:")
predictions_train = reg_utils.predict(train_X, train_Y, parameters)
print("使用随机删除节点,测试集:")
reg_utils.predictions_test = reg_utils.predict(test_X, test_Y, parameters)
第0次迭代,成本值为:0.6634619861891965
第10000次迭代,成本值为:0.06099512309997576
第20000次迭代,成本值为:0.06055252059686293
使用随机删除节点,训练集:
Accuracy: 0.9289099526066351
使用随机删除节点,测试集:
Accuracy: 0.955
plt.title("Model with dropout")
axes = plt.gca()
axes.set_xlim([-0.75, 0.40])
axes.set_ylim([-0.75, 0.65])
reg_utils.plot_decision_boundary(lambda x: reg_utils.predict_dec(parameters, x.T), train_X, train_Y)