神经网络参数的初始化,在网络层数很深的情况下变得尤为重要。如果参数初始化的过小,很可能导致网络每一层的输出为都接近于0,那么可以这样认为每一层的输入都会很接近于0,在进行反向传播的时候,假如我们要更新某一层的参数W,该层的输出是g(WX)暂且先不考虑偏置项,则求W的梯度就会是:上一层的梯度 * 该层对g的梯度 * X,由于每层的输入都很小所以梯度就会很小,从而导致参数更新很慢,随着层数的增加就会产生梯度消失的现象。我们也可把所有的梯度都连起来看,当进行反向传播的时候,计算某一层的参数梯度为:本层的输出对参数求梯度 * 上一层的梯度,而上一层的梯度中会有上层的权重W这一项(可以自己求一下验证),而W初始化的很小,随着层数的加深,每一层的W累乘,就会导致梯度越来越小直至为0。
下面是做的一个演示:
一个10层的神经网络,每一层都使用tanh做为激活函数,数据是1000个从标准正态分布中随机采样得到。
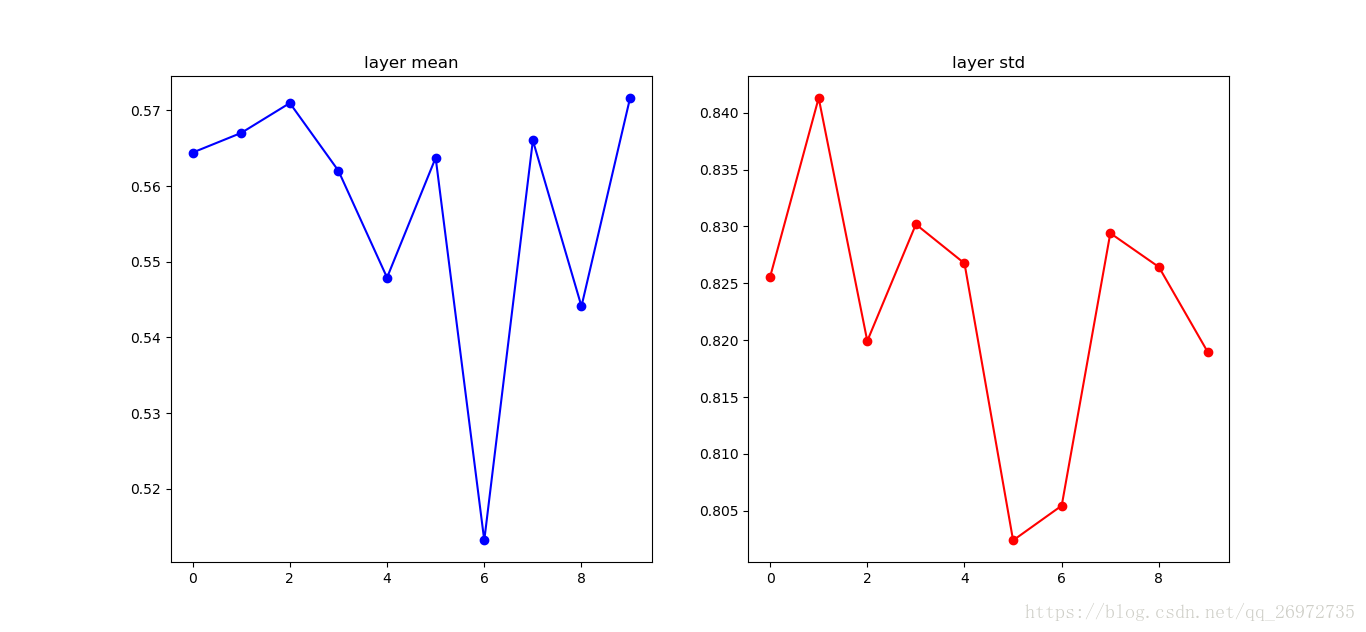
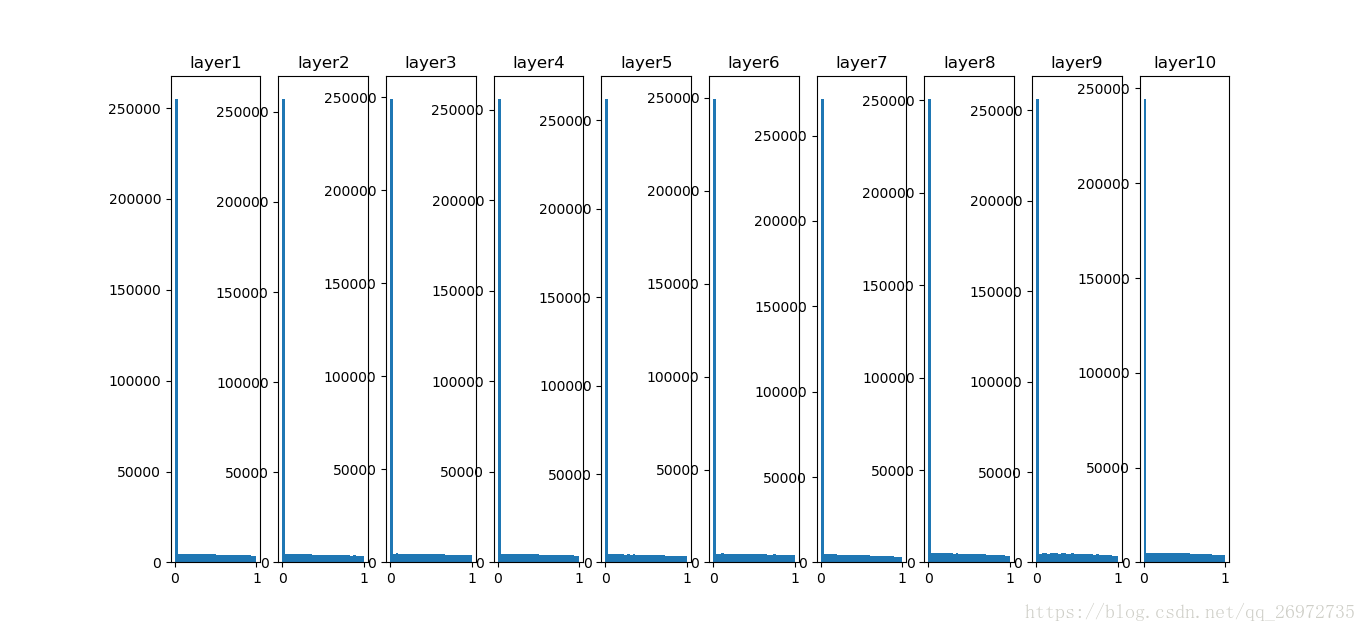
首先如果每一层的参数如果都初始化的很小:
W = np.random.randn(fan_in, fan_out) * 0.01 #layer initialization
那么每层输出的均值、标准差和分布如下:
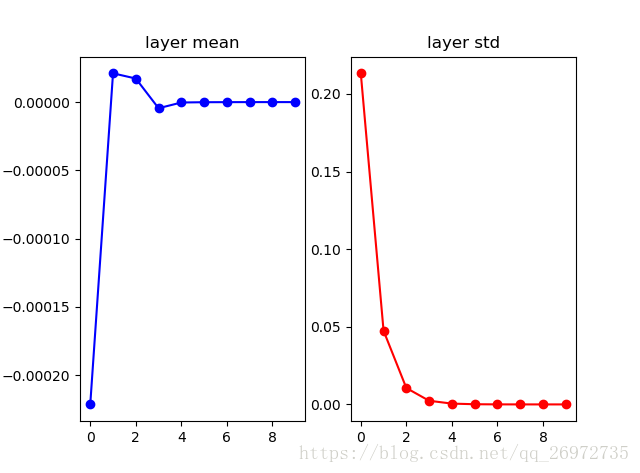
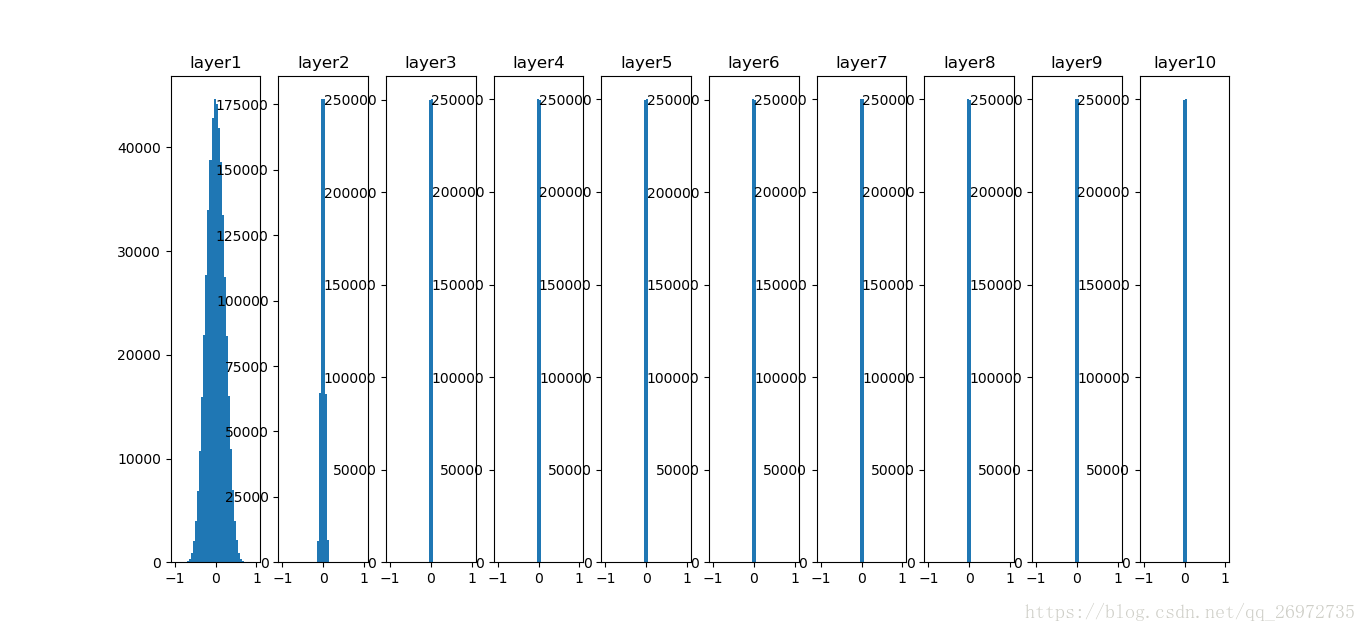
可以看出在第一层的时候还保持着原有数据的分布,但从第二层输出开始数据的分布就逐渐的靠近0,最终均值和标准差都为0。
那么参数的初始化如果大一些会如何?如果参数初始化的过大,则每一层的输出就会很大,也就是每个神经元都很饱和,如果进行反向传播,考虑激活函数的图像,则对激活函数的梯度就会趋近于0,也会造成梯度消失的情况。下面是参数初始化过大的情况。
W = np.random.randn(fan_in, fan_out) * 1.0 #layer initialization
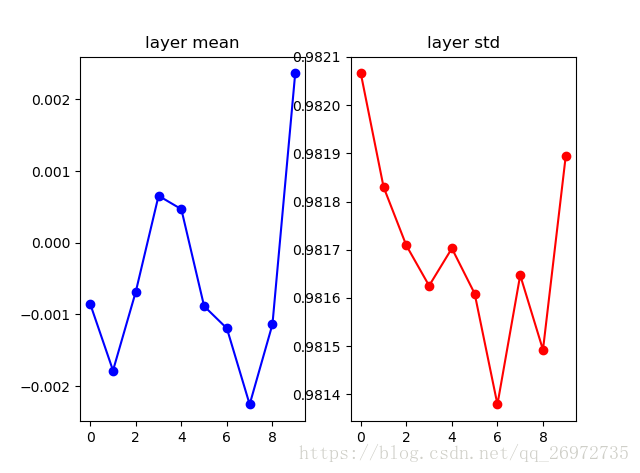
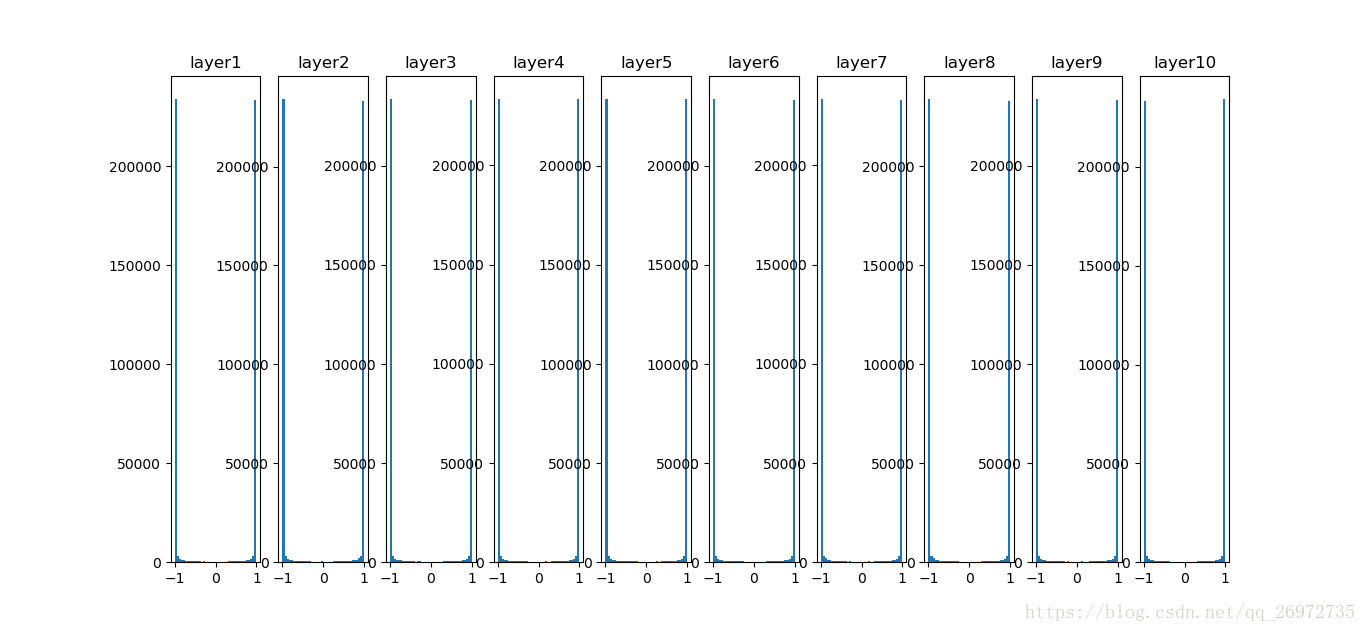
一个很好的初始化参数的方法就是使用Xavier initialization,这个方法是Glorot在2010年发表的论文中提出的,该方法初始化的公式为:W = np.random.randn(fan_in, fan_out) / np.sqrt(fan_in)
这个公式的目的就是令输出和输入的方差保持一致。具体推导可以在网上有很多,也可以去看论文。
在使用了Xavier方法初始化后每一层的输出分布如下:
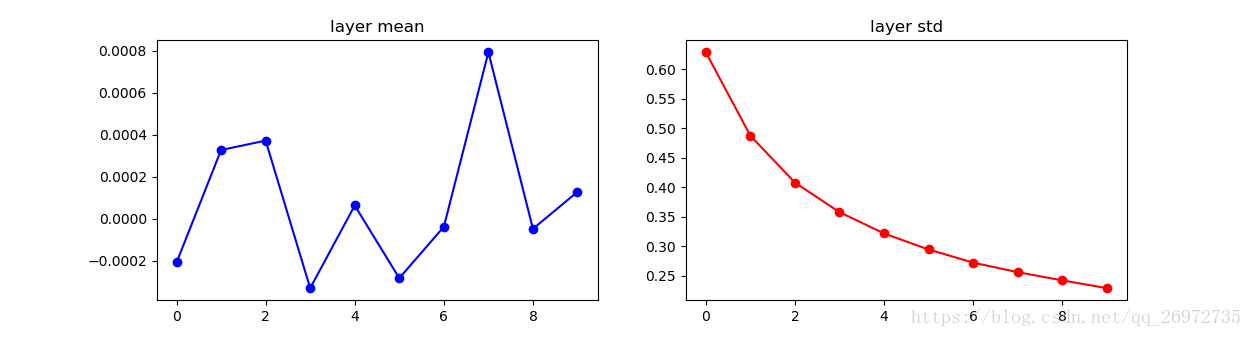
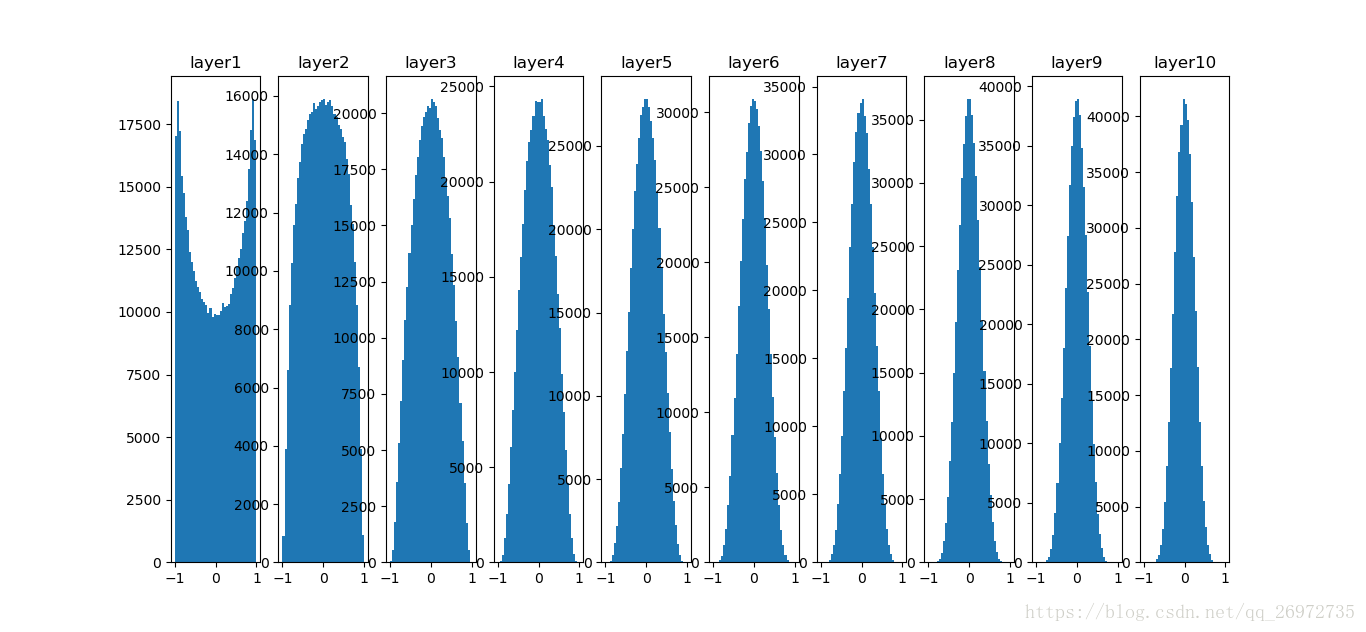
可以看出每一层输出都有较好的分布。
对于使用relu激活函数,则使用上面的Xavier方法进行初始化效果就不好,这是因为relu激活函数只会激活大约一半的神经元,其他神经元的输出为则为0,那么使用原始的Xavier的公式就会改变原来的方差。每层输出分布如下:
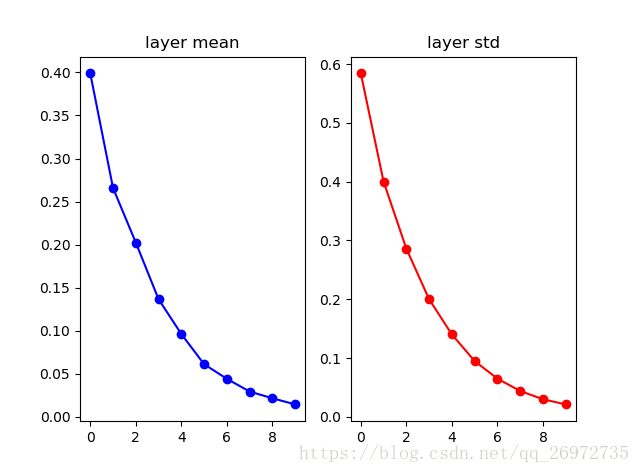
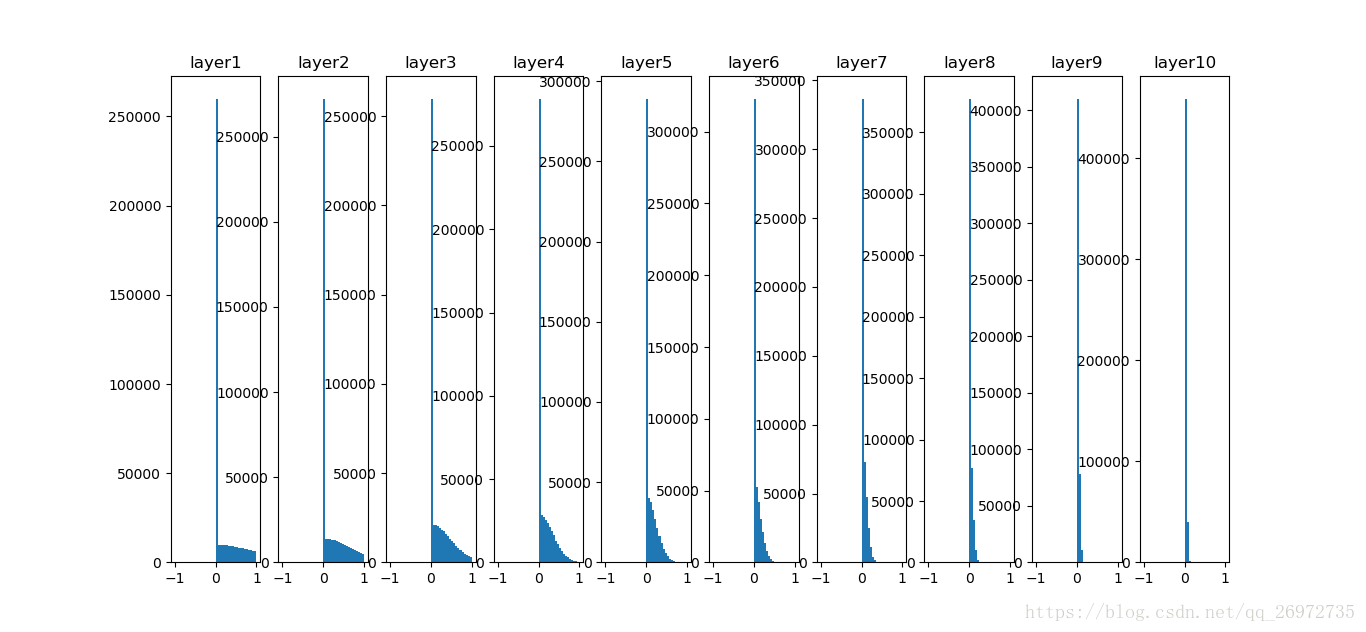
可以看到,随着层数的加深,每一层的分布越来越向0进行收缩。解决这个问题可以使用如下的式子(He et al.,2015):
W = np.random.randn(fan_in, fan_out) / np.sqrt(fan_in / 2)
由与每次实际上只有大约一半的神经元被激活,相当于只有一半的输入有效,所以在进行参数缩放的时候除以2。
总之在深度神经网络的实现中,参数的初始化尤为重要。如果要想网络表现的好,训练的快,合适的参数初始化势必不可少的。
参考资料:cs231n课程