Mysql常用的索引:
一、聚集索引(聚簇索引):一般是主键,注意一般是主键,有可能不是主键,主要数据行的物理地址和与列值的逻辑顺序一致,一个表中一般只有一个聚集索引。
二、非聚集(聚簇)索引(又叫辅助索引-->聚集索引以外的任何表中的索引都可以称为辅助索引)
2.1.普通索引:index(加速查找)
2.2 唯一索引 UNIQUE KEY (不能重复)
2.3 联合索引(复合索引、覆盖索引(特殊简称,只要获取联合索引里面的值))
3.1 联合主键索引 (id,name)
3.2 联合唯一索引 (id,name)
3.3 联合普通索引(id,name)
Mysql建立索引的一般原则:
1.最左前缀匹配(非常重要):mysql会一直向右匹配,直到遇到范围查询(<、>、between、like)即停止匹配,比如a=1 and b =2 and c >3 and d = 4,如果建立的索引是(a,b,c,d),那么d是用不到索引的(注意不是说这种情况使用不到索引,而是仅仅是d不能使用索引,因为在c>3查询之后的话就会通过主键索引去查询对应记录了),但是如果建立的是(a,b,d,c)那么是可以使用的,因为mysql会做优化,所以a,b,d的顺序可以随便。
2.= 和in 可以乱序:a = 1 and b = 2 and c = 3mysql的查询优化器会做优化成索引可以识别的形式。
3.尽量选择区分度高的列作为索引:标准是 count(distinct col) / count(*),也就是在(0,1]之间浮动,值越高区分度越大,主键的区分度就是1,。一般需要join的字段最好是在0.1以上(没有明确规定)。
4.索引列不能参与计算
5.尽量扩展索引而不是新建
以上是一些主要原则,还有一些细要原则就不列了,都是一些经验之谈。
Mysql索引的认知:
认知主要的是对于最左原则的理解和测试
假设现在存在联合索引(age,name,address)与表user中,例子来源于上一篇博客3.3处。
以下会走索引:
1.select * from user where age = 7 and name = '刘' and address = '北京';
毫无疑问,这一句就是根据索引写出来的,肯定走索引。
2.select * from user where name = '刘' and address = '北京' and age = 7;
查询优化器会优化成 age = 7 and name = '刘' and address = '北京',所以满足要求,同样走索引。
3.select * from user where age = 7;
索引也是生效的,因为从结构中可以看见索引第一个字段就是年龄,所以能一下子定位到相应数据。
4.select * from user where age = 7 and address='北京';
索引也是生效的,先通过age定位到7的数据,然后查询出全部名字的人,最后查询出地址是北京的。也就是这种情况其实是部分扫描了,姓名并没有执行索引,地址执行了索引。
以下不会走索引:
1.select * from user where name = '刘' and address = '北京';
可以看见这么查询的话,根据结构来看第一字段是年龄,但是查询语句中没有年龄,所以不会走索引。
2.select * from user where address = '北京';
同样的,这一句也是如此。
总结:
可以看见所谓的最左原则的出现就是根据底层B+树的结构出现的,因为在这个B+树中,辅助索引的字段就是年龄,而年龄刚好就是我们定义的联合索引的最左字段(age,name,address),所以就有了为什么要遵循最左原则了。那么通俗的将就是对于索引结构(a,b,c)来说,它的索引应用应该是(a),(a,b)(a,b,c),对于这三种查询都是有效的。
测试用例:
t_user(id,age,name,sid) 113万多数据。
建立普通索引 index (age)
ALTER TABLE t_user ADD INDEX index_age_1 (age);
测试一、
1. 查询条件为 * 号的 范围查询(<,>,!=),搜索结果很多的情况下(1056625[搜索记录]/1135271[总记录])


结果看见当查询条件是 * 时,> 并没有走索引,而是进行的全表扫描。
2.查询条件为 * 号的 范围查询(<,>,!=),搜索结果很少的情况下(3603[搜索记录]/1135271[总记录])


发现此时走了索引,原因很可能是搜索结果很少的缘故。
3. 查询条件缩短到 age字段时 的范围查询 (1098247[搜索记录]/1135271[总记录])


结果看见走了索引查询。它竟然走了索引。
根据用例一的小总结:
1.范围搜索(<,>,!=)受制于搜索结果,如果搜索结果占比很小的话,此时会走索引,如果占比过大,那么会放弃索引,走全表扫描。
2.但是根据1和3的结果,大家的搜索结果占比很大,为什么3走了索引呢,因为3的查询项只有一个age,此时的age又是索引。这就是上一篇博客里说的覆盖索引(很特别),一般的索引结构只是在叶子节点中存放了data域,此时还需要通过主键索引去进行一次定位,但是覆盖索引由于你查询的值刚好就在其中,所以不需要再走一次主键查询,因此会直接执行索引。
关于这个的观点的佐证,来源于Mysql技术内幕(InnoDB存储引擎),截图如下:

测试二、
between and的测试
这里就忽略掉了,因为情况和<,>差不多,查询数据量不大时或者查询项里面存在age子弹还是会使用到索引,但是超过一定的阈值就会全表扫描。
测试三、(最左原则)
建立联合索引(age,name,sid)
ALTER TABLE t_user ADD INDEX index_age_2 (age,name,sid);
3.1正常测试,是走索引的。

3.2 打乱顺序执行,还是会走,所以顺序是浮云
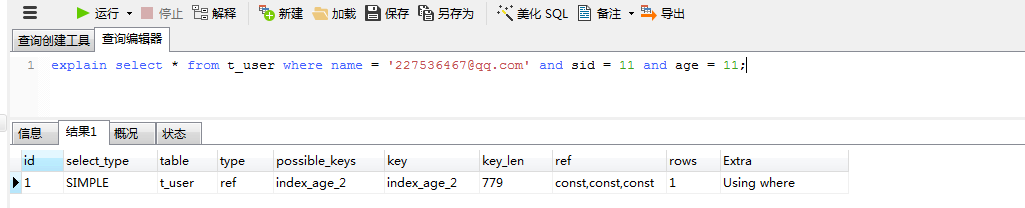
3.3出现非索引字段时,但是最左字段age是存在时,走索引。
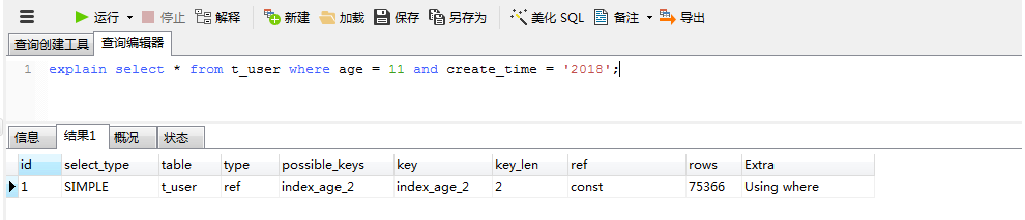
3.4 没有最左字段age时
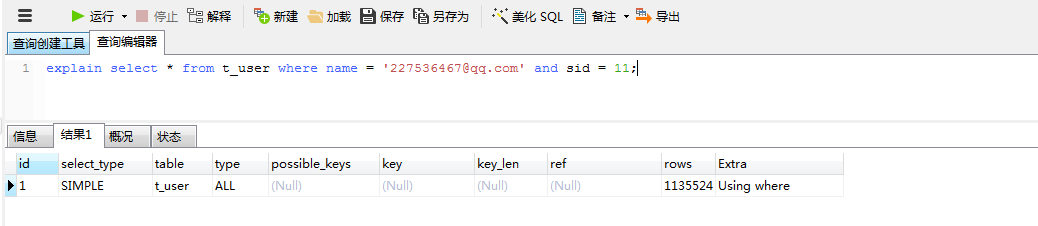
3.5 最左索引时使用order by子句,而排序字段是第二个索引字段时(需要和3.6进行比较)

3.6最左索引时使用order by子句,而排序字段是第三个索引字段时(需要和3.5进行比较)
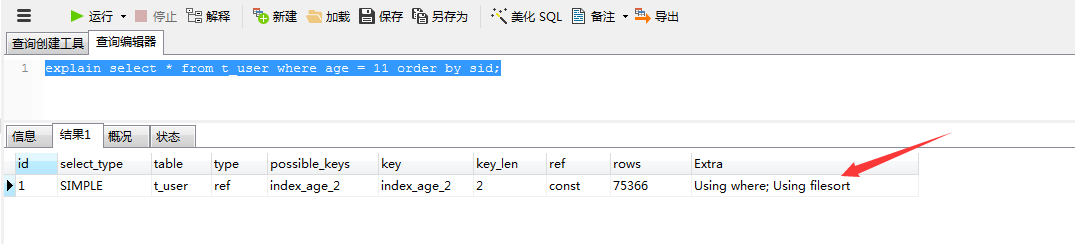
3.5 和3.6 的差别就在最后的filesort操作,这其实是age是排序好的,紧接着的name的值mysql也帮我们排序好了,接着name的sid字段也是排序好的,依次而来是没有问题的,但是如果你跨间距了,就比如说age之后使用sid排序,但是age和sid之间没有顺序的特性,所以要进行filesort操作(出现filesort是比较差的场景)。
测试四、(对于like的索引使用)
建立name的单独索引,其实本例中,name的区分度是1,因为当初建立的时候是循环递增的,但是模拟一下没什么关系。
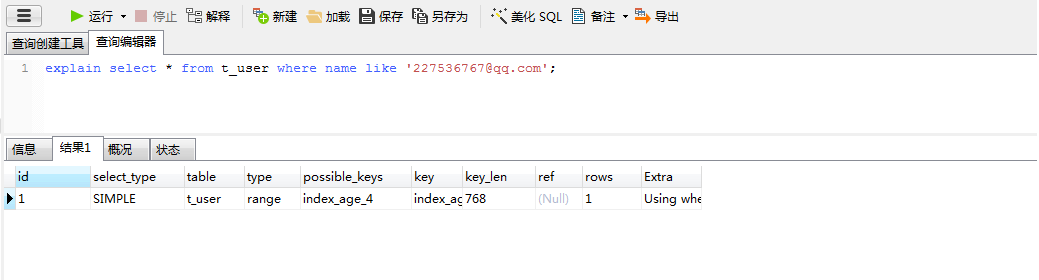
ALTER TABLE t_user ADD INDEX index_age_4 (name);4.1 测试 name 的等于查询,可以看见使用了索引,而且ref指标是常数,性能很不错。

4.2 测试name 的like查询,给定一个指定值,type是range,性能也不错。
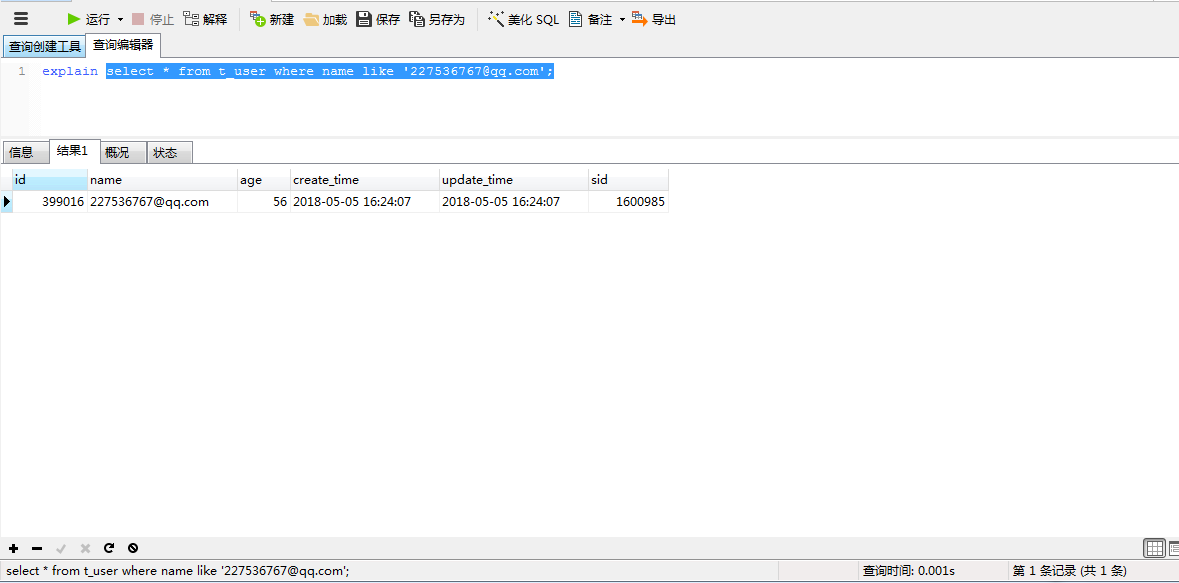
4.3测试name的like 左边匹配。可以看见性能很差,没有走索引,估计是被优化了,存储引擎认为走全盘扫描更合适。

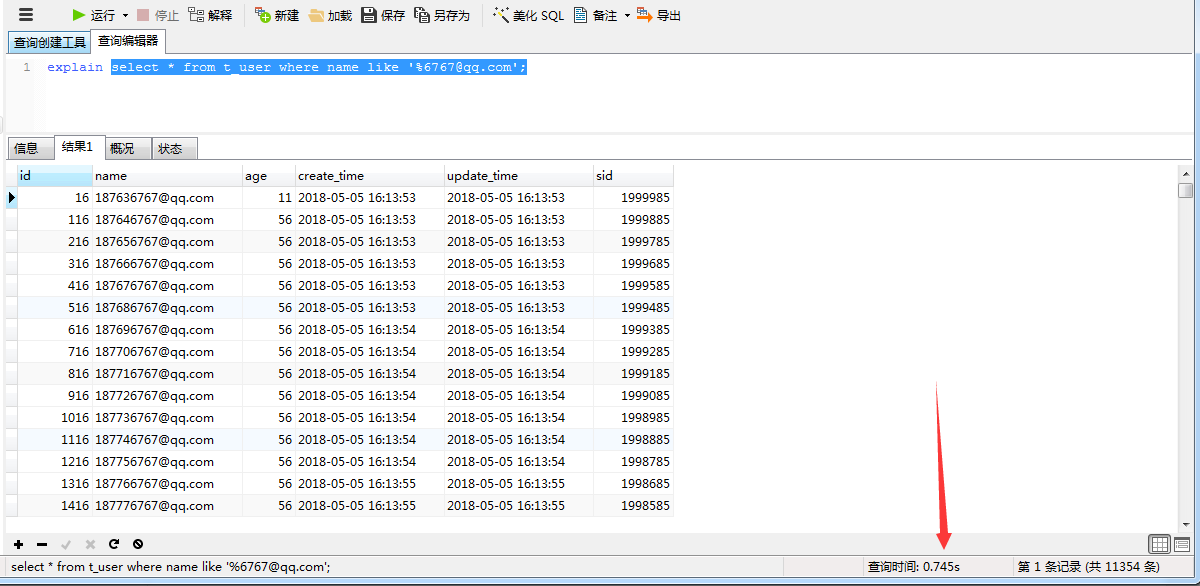
4.4 测试name的like,右边匹配。此时走了索引,其实也可以根据B+树结构来分析,前面的值其实是B+树内的索引结构,所以引擎认为此时走比较合适。更快一些。

