代码部分
#Python 3.5
#Author: A_lPha
#Blog: http://blog.csdn.net/a_lpha
import json
from urllib.request import urlopen
from urllib.error import HTTPError
print("*" * 8,"网易云音乐下载器", "*" * 8,"\n")
ID = input('请输入歌曲ID:\n>>> ')
url = "http://music.163.com/api/song/detail/?ids=[" + ID + "]"
html = urlopen(url).read().decode("utf-8")
rejson = json.loads(html)
for name in rejson['songs']:
print('歌曲ID: ',name['id'])
print('歌曲名称: ',''.join(name['name']))
print('歌手: ',''.join(names['name'] for names in name['artists']))
print('mp3链接: ',name['mp3Url'])
num = int(input('\n是否下载?(输入1下载该歌曲,输入其他数字关闭程序.)\n'))
if num == 1:
try:
f = open(str(''.join(name['name']) + "-" + ''.join(names['name'] for names in name['artists'])) + ".mp3", "wb")
req = urlopen(name['mp3Url'])
buf = req.read()
f.write(buf)
f.close()
print("已保存")
except HTTPError as e:
print("遇到错误啦! 错误代码是这个: \n",">>>>>>",e,"<<<<<<","\n我猜这是付费歌曲的'ID',可能是网站不让下载吧!")
elif num != 1:
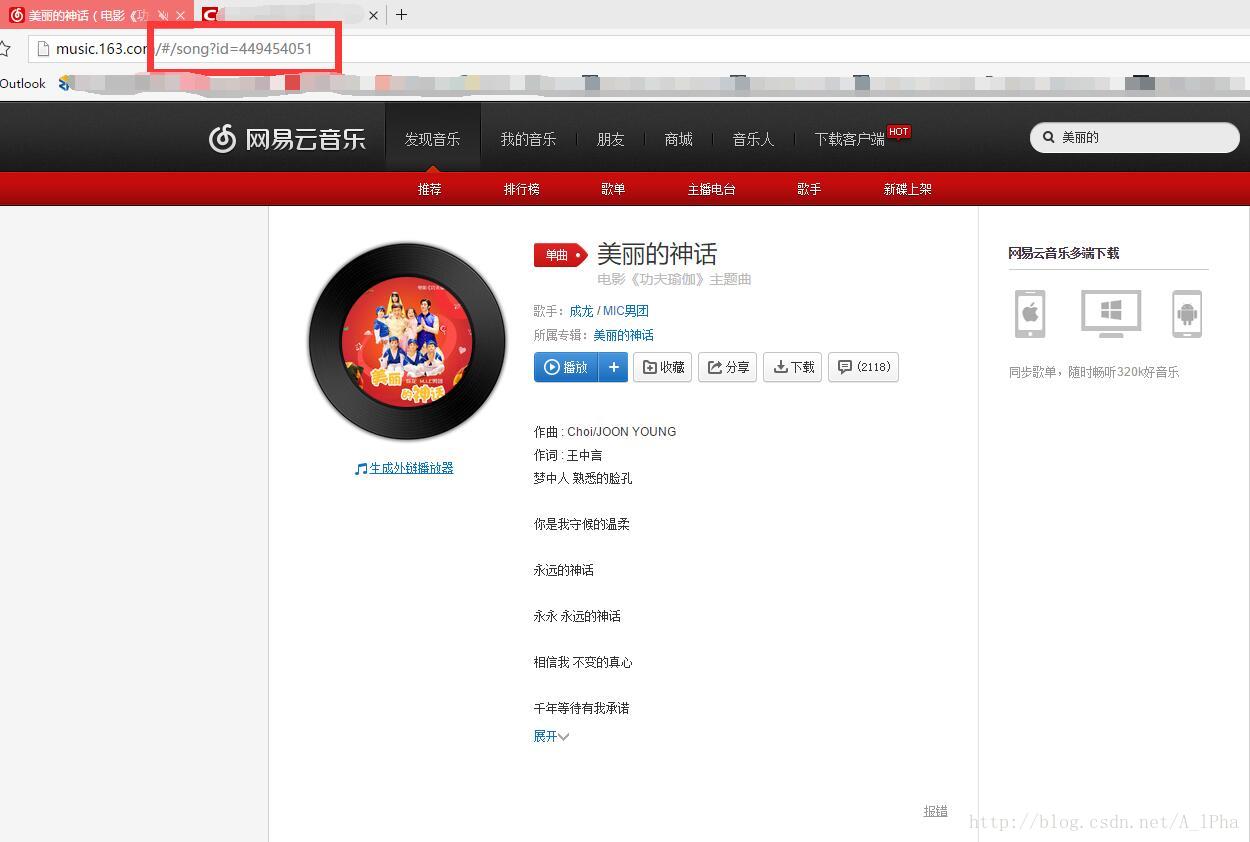
print("已关闭")找网易云音乐歌曲的ID方法,在网易云音乐搜索到该歌曲,打开播放页面,在浏览器地址栏后显示该歌曲ID。
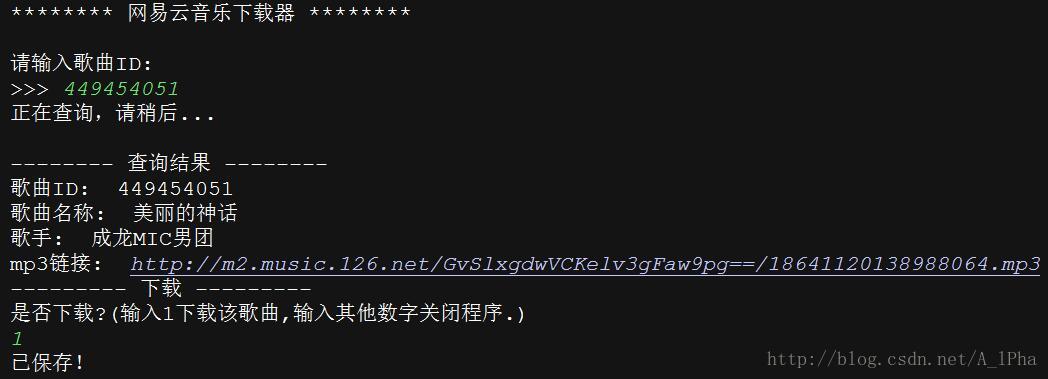
一般情况下可以找到歌曲的链接,付费歌曲也可以找到链接,但是返回404错误。
代码很简单,现在还没发现其他问题。
==================================更新==================================
#Python 3.5
#Author: A_lPha
#Blog: http://blog.csdn.net/a_lpha
import json
import time
from urllib.request import urlopen
from urllib.error import HTTPError
print("*" * 8,"网易云音乐下载器", "*" * 8,"\n")
def getId():
try:
ID = int(input('请输入歌曲ID:\n>>> '))
print("正在查询,请稍后...\n")
time.sleep(0.9)
return ID
except:
print("请输入正确的ID!\n")
getId()
def getInformations(ID):
print("--"*4,"查询结果","--"*4)
try:
ID = str(ID)
url = "http://music.163.com/api/song/detail/?ids=["+ID+"]"
html = urlopen(url).read().decode("utf-8")
rejson = json.loads(html)
for informations in rejson['songs']:
print('歌曲ID: ', informations['id'])
print('歌曲名称: ', ''.join(informations['name']))
print('歌手: ', ''.join(names['name'] for names in informations['artists']))
print('mp3链接: ', informations['mp3Url'])
song = ''.join(informations['name'])
name = ''.join(names['name'] for names in informations['artists'])
mp3url = informations['mp3Url']
return song,name,mp3url
except:
print("这个可能不是正确的ID哦!重新试试吧。")
id = getId()
song, name, mp3url = getInformations(id)
getUrl(song, name, mp3url)
def getUrl(song,name,mp3url):
print("-"*9, "下载", "-"*9)
num = int(input('是否下载?(输入1下载该歌曲,输入其他数字关闭程序.)\n'))
if num == 1:
try:
filename = str(song + "-" + name)
with open(filename + ".mp3", "wb") as mp:
infor = urlopen(mp3url).read()
mp.write(infor)
print("已保存!")
except HTTPError as e:
print("遇到错误啦! 错误代码是这个: \n", ">>>>>>", e, "<<<<<<", "\n我猜这是付费歌曲的'ID',可能是网站不让下载吧!")
elif num != 1:
print("已关闭。")
id = getId()
song, name, mp3url = getInformations(id)
getUrl(song, name, mp3url)这段代码处理了异常,界面也清晰了许多。不过代码还是有些臃肿。