1、领域名词解释
稳定性(Reliability)、可用性(Availability)、可维护性(Maintainability),是三个有关联的概念、合称RAM,较为容易混淆,因此本需要特别说明一下。依据《ISO IEC 25010-2011 SQuaRE》标准,可将稳定性理解为”应对故障(faults)的能力、对用户而言是可用的,被性能、可用性、可维护性等因素影响。“ 稳定性并不纯粹、搞混淆RAM是很正常的,但治理故障这一点很清淅。
本文对高可用的定义是:能应对大流量的稳定性。因此实施方案当中也涉及SLA等指标的运营。
2、稳定性治理的三种思想
什么是交易长期坚持的高可用方向?故障涉及方方面面,高可用的方法也是种类繁多,我们需要几条基本方法去指导高可用长期的治理方向,我们有三种视角去看待高可用这件事:可用性计算公式、复杂系统理论、交易技术事故定级规范。从不同的视角看待事情,会导致不同的分析路径。
1.可用性计算公式—亚马逊
第一种理解可以从可用性计算公式(Availability Estimate)入手,涉及两个变量:故障概率、故障时长,增大MTBF、减小MTTR。主要包含减少故障发生概率、减少故障恢复时间、制造故障发生概率(可控的)三个方法。为什么会需要人为制造故障发生概率?因为故障发生相应频次较低,没有办法很好地提前发现故障,而制造故障本质则能帮助解决。减少故障发生概率是know unnkown的做事, 制造故障发生概率是unkown unkown的做事。
AvailabilityEstimate=MTBF/(MTBF+MTTR)。MTBF:theMeanTimeBetweenFailure,MTTR:MeanTimetoRecover
从这三个策略推导的一些主要方法如下图示,参考了亚马逊《AWS Reliability Pillar 2019》。

可用性公式拆解的稳定性原则(灰色部分源自《AWS Reliability Pillar 2019》)
2.复杂系统理论—Netflix
分布式系统具备复杂系统的一般特征,可以复杂系统理论来研究与指导分布式系统,该想法来自Netflix《Mastering Chaos—A Netflix Guide to Microservices》的启发。Netflix在业内有一系列产生重大影响的稳定性开源产品,包含Hystrix、Chaos Monkey、Zuul、aws-autoscaling等。
依据《What is a Complex System(James Ladyman etc.)》论文对复杂系统定义的研究,复杂系统的特征之一是系统主要维护 “无序性(disorder) vs. 鲁棒性(robust order)”这对矛盾的平衡稳定。当系统突破临界值、就会产生更大的disorder。从这对矛盾出发、有两个思路:既可以通过模拟环境增加无序性、激化矛盾,也可以增加稳定性能力鲁棒性、减少矛盾。
复杂理论的原则可概括为:随机、依赖和规模是影响系统稳定性的三大因素,分治、自治、反馈是守正之法,无序是出奇之法。从该原则推导的主要方法如下图所示。

复杂系统理论拆解的稳定性方法(灰色部分源自《Mastering Chaos—A Netflix Guide to Microservices》)
3.交易技术事故障驱动—蚂蚁金服
影响事故定级的因素主要是两大类:资金损失、体验损失。

从避免资金损失、体验损失这两个策略归纳的一些主要方法,如下图所示。鉴于蚂蚁金服在金融领域的行业影响力,主要参考了蚂蚁金服TRaaS技术风险防控平台、将高可用与资金安全相结合。资金安全也是影响系统稳定性的一个重要因素。
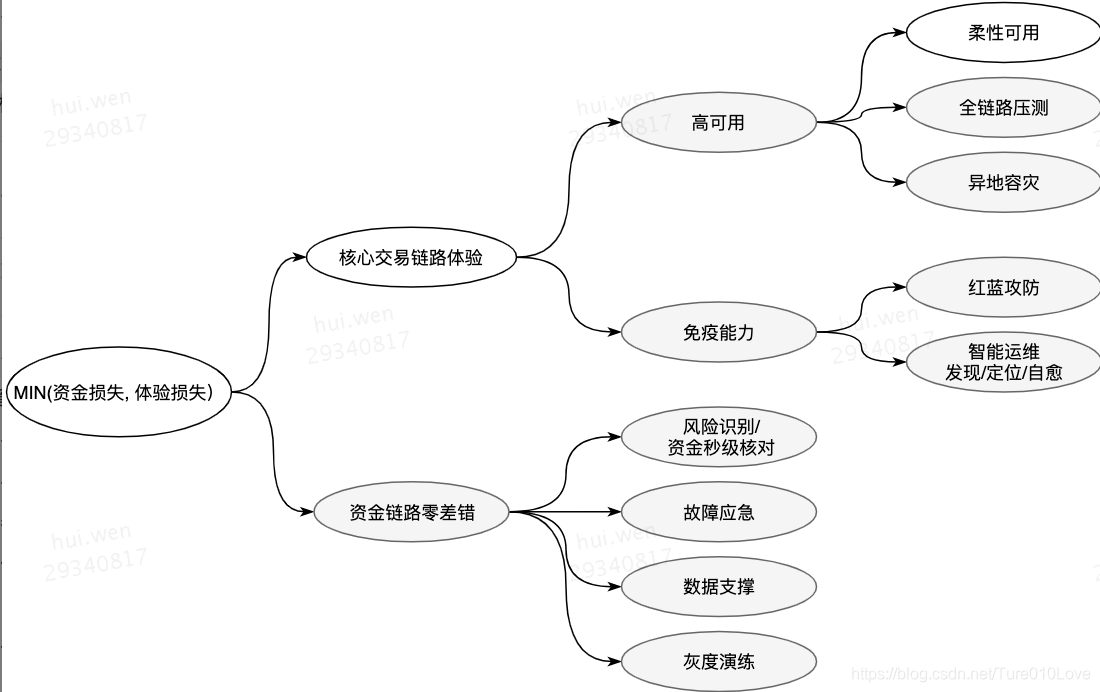
交易事故拆解的稳定性方法(灰色部分源自《蚂蚁金服 TRaaS 技术风险防控平台》)
3、稳定性的方法设计
3.1、设计挑战
什么构成了交易可用性的挑战?归纳成四点:故障的随机性(软硬件、网络故障等),系统规模(交易链路长、外部依赖关系多),系统变化(节假日流量、功能迭代发布),以及交易故障产生的重大影响。前三点是引发系统故障的重要因素,如下图所示。

影响稳定性的三个因素(依据复杂系统理论)
这三个因素也决定了稳定性需要长期运营、没办法一劳永逸(更本质的说法是系统的熵增所决定)。这意味着像Amazon、阿里等这样的大公司,即使有了专业的SRE团队、稳定的技术产品体系,体系化地做稳定性这件事,也无法说 "it's enough!" 只要有业务需求迭代、只要有变化、只要系统存在,就需长期去做运营。
3.2、系统全景图
交易可用性方向如下图,主要思路如下:

1)用分治与隔离的思路、将复杂系统变成N个相对简单的子系统,简化系统的规模、降低模块间的依赖关系、降低长链条比例。这点在系统架构阶段要重点关注。
2)每个子系统,需要具备健康反馈能力、能够时实感知故障,并且实现对故障的自愈,以应对故障的随机性。
3)为了减轻故障频次低难以验证稳定性的问题,也为了防止系统处于临界状态(一个小问题,引发大故障),需要随时的随机的在生产环境做故障演习,以及压测。对于故障演习,以前大家不够重视,这是一个很强的演进驱动力,在系统越早期做、成本及风险越低。
4)不同故障对业务的影响不一样,我们可以通过柔性可用等方式减少影响、保障用户核心体验。针对交易业务重点关注全域的资金链条。
5)我们不仅需要构建系统的稳定性能力,同时也要把控好整个研发流程,包括成本收益、架构设计、持续交付、组织保障、故障处理机制等。有一个源自阿里运维的数据,有60%~80%的故障源自发布变更。
4、稳定性子项交付成熟度—衡量标准。
对交易高可用结果的定量,以各团队对技术故障数量为考核标准。对交易高可用建设过程的定量,主要涉及两方面:具体要做什么事、这些事又怎么定量。本文参考阿里运维参考汽车自动化的分类方法,从功能完善度、自动化程度两个维度定义了交易高可用成熟度等级,见下表。本文的自适应容量、自适应故障参考自《企业级 AIOps 实施建议》,混沌工程参考自《AWS混沌工程成熟度分级标准》,监控告警参考自《stack state监控成熟度模型》。
2019年Q3Q4主要实现绿色表示的目标,2020年实现全覆盖。
| 分类 |
工作内容 |
L0(无自动驾驶) |
L1(具有特定功能的自动驾驶) |
L2(具有复合功能的自动驾驶) |
L3(具有限制条件的无人驾驶) |
L4(全工况无人驾驶) |
|---|---|---|---|---|---|---|
| 健康反馈 |
监控告警 |
全人工 |
独立组件监控 |
分层监控 |
全链路监控 |
智能分析、预测、自愈 |
| 分治单元 |
业务隔离 |
无隔离 |
独立组件隔离 |
基础设施隔离(网络、机房、容器、组件、数据库等)。含:Set化、泳道等。 |
业务隔离 |
环境隔离 |
| 单元自愈 |
自适应容量 |
数据收集和分析工具 |
流量调度平台、扩缩容平台。 含:限流、扩缩容等。 |
基于规则的自动调度和扩缩容 |
可自主规划成本和容量方案的智能调度&伸缩 |
支持服务完整生命周期的全部基础运维工作,由智能系统接管,统自主做到可用性、成本、效率撮优化 |
| 自适应故障 |
按需开发的追查、处理脚本 |
预案平台 |
基于预案的自动止损;自适应可测; 例:依赖关系、核心链路等。 |
可自动规划止损方案的智能故障ONCALL;自适应可测; |
支持服务完整生命周期的全部基础运维工作,由智能系统接管,统自主做到可用性、成本、效率撮优化 |
|
| 攻防演练 |
全链路压测 |
全人工 |
单机压测 |
交易全链路压测 |
交易全链路压测;自动生成报告;周期自动执行 |
交易全链路压测;自动生成报告;周期自动执行;智能设置阈值 |
| 混沌工程 |
全人工 |
在预生产环境中运行实验;有工具 |
生产环境运行;周期人工;手动监控和停止实验;若干故障场景(应用容器) |
生产环境运行;周期人工;自动分析;自动终止实验;丰富故障场景(应用容器/网络环境/数据库等) |
生产环境运行;周期自动化;丰富故障场景 |
|
| 研发工程 |
发布变更 |
