翻译自:Redis Tutorial: NoSQL key-value store
目录
谢百度翻译,感谢歪果仁Andriy :
Redis是BSD许可的,通常被称为数据结构服务器,因为key可以包含字符串、哈希、列表、集合和排序集合。
这是关于Redis的速成课程。您将学习如何安装Redis和启动服务器。此外,您还将学习redis命令行的基本用法。下面将介绍更高级的主题,如复制、分片和集群,同时还将解释Redis与Spring数据的集成。
在本课中,您将通过在各种平台(包括Linux和Windows)上安装Redis。下一步是验证配置,以确保一切按预期工作。接下来,继续进行服务器配置和微调,以根据您的特殊需要对其进行调整。探索redis的最佳和最简单的方法是通过命令行界面(cli)。ServerCLI是您的朋友,通过使用它,您将了解如何执行服务器管理。总的来说,本课将让您从Redis开始,这样您就可以充分利用这个强大的NoSQL数据库。
一:安装
1. Redis安装基本介绍
Redis可能是近年来从社区中涌现出来的一大堆NoSQL解决方案中最广为人知和最有争议的一个例子。尽管将redis视为一个密钥/值存储,但是redis做的更多,它将复杂数据结构的强大功能交给了开发人员。引用http://redis.io:
更不用说现成的发布/订阅支持、集群(实验)、分片、复制和事务语义。本教程的目的是通过浏览Redis的安装、配置和功能,为Redis的世界提供简要而全面的指导。
redis是内存数据存储。如果您的数据适合存储在内存中,您将适合使用Redis,这就是为什么Redis经常被用作高级缓存解决方案(而不是memcached)。但是,一旦您的数据停止装入内存,您将看到由于交换到磁盘而导致的性能显著下降。在本教程的后面,我们将回到这个主题,看看还有什么其他的选择。
2. 许可证License
Redis是根据三条BSD许可条款发布的开源软件。有关Redis官方网站的更多详细信息。
3. 文档Documentation
Redis团队为您可能需要了解的每个功能或命令维护完整、组织良好和最新的文档。在任何时候,这对每个人都是一个很好的参考,所以如果你有任何问题或事情不太清楚,请毫不犹豫地看一下。一般文档可在http://redis.io/documentation上找到,而命令在http://redis.io/commands上有自己的部分(一旦开始使用redis,我们将经常参考它)。
4. 在linux上安装Redis
在Linux设备上安装Redis的最佳(目前唯一)方法是从源代码构建它。为此,可以从http://redis.io/download(请务必选择稳定发布分支)下载redis的源代码。一旦存档在您的计算机上,通过几个简单而简单的步骤将您与自己的Redis实例分离开来:
下载
wget http://download.redis.io/releases/redis-2.8.4.tar.gz
•解包归档文件
tar xfz redis-2.8.4.tar.gz
CD ReDIS-2.84
•生成二进制文件
make
或者(如果安装了Linux 32位)
Make 32bit
•运行测试(您需要安装TCL 8.5+才能运行测试)
make test
•安装(作为根用户或使用sudo命令)
make install
值得一提的是,redis没有任何特殊的需求或依赖关系,无论是运行时还是编译时,并且与大多数Linux发行版兼容。您唯一需要的预安装包是gcc和make。
默认情况下,redis二进制文件的引用将在/usr/local/bin文件夹中创建。要了解更多信息,自述文件是查找高级详细信息(如更改默认安装文件夹、常见生成错误疑难解答等)的好地方。
5. 在windows上安装
Redis团队不支持官方的Windows发行版。幸运的是,有一个由微软开放技术集团支持的实验性Windows32/64端口,可以在github上免费使用:https://github.com/msopentech/redis。需要考虑的一个重要问题是,Windows端口始终落后于最新的Redis版本,因此,它并不像您需要的那样功能丰富。在撰写本文时,Windows最新版本的Redis是2.6.12。
- 从源代码仓库克隆(如果没有安装Git,请从https://github.com/msoppentech/redis下载为zip存档)
- 为了您的方便,存储库中已经有了预构建的二进制文件。把它们放在方便的地方。
- Windows 32位:bin/release/redisbin.zip
- Windows 64位:bin/release/redisbin64.zip
- 然而,如果你想,你可以建立从源代码构建。这样做,你需要有Microsoft Visual Studio 2010年或其自由可用的版本的Microsoft Visual C++ 2010 Express版可在Microsoft Visual Studio Web站点下载。一旦你拥有它,只需要打开msvs /RedisServer.sln解决方案文件,编译它。二进制可执行文件将生成在msvs/Debug或者msvs/Release取决于你的配置和平台的建立(32位或64位)。

6. 验证安装
安装完成后,Linux设备的可执行文件应位于/usr/local/bin/folder中:
| 可执行文件名 |
描述 |
| redis-benchmark |
Redis Benchmarking工具,非常有用,可以模拟许多客户机并行运行一组命令,以便评估您的Redis实例配置(更多详细信息,请访问http://redis.io/topics/benchedges) |
| redis-check-aof * |
验证并修复redis用于管理持久性的仅附加日志(aof log)是否损坏(更多详细信息,请访问http://redis.io/topics/persistence) |
| redis-check-dump * |
检查redis数据库转储(RDB)文件(更多详细信息,请访问http://redis.io/topics/quickstart) |
| redis-cli |
命令行界面实用程序,用于与redis服务器通信(有关详细信息,请访问http://redis.io/topics/quickstart和First look at Redis CLI 部分) |
| redis-server |
Redis服务器(更多详细信息,请访问http://redis.io/topics/quickstart) |
*如果需要恢复损坏的数据,这些工具非常有用
Windows安装(从零开始构建或从预构建的存档中提取)由以下可执行文件组成,这些可执行文件与Linux可执行文件镜像:
- redis-benchmark.exe
- redis-check-aof.exe
- redis-check-dump.exe
- redis-cli.exe
- redis-server.exe
如果将包含这些可执行文件的文件夹附加到Windows路径环境变量,将节省大量时间。
7. 基本配置
Redis支持非常复杂的配置设置,包括持久性、分片、群集、复制等。有些配置参数需要重新启动服务器,但有些参数可以在运行时使用Redis CLI工具进行调整。
但对于初学者来说,redis配置的好处是根本没有配置!Redis可以在不提供单一设置的情况下启动,并且工作正常。
不过,浏览一些关键选项是非常有用的(详细的配置将在我们讨论更高级的主题时介绍)。例如,我们将从redis发行版中查看redis.conf文件,这是创建自己的文件的一个很好的起点。
daemonize yes | no(default: no)
默认情况下,redis不作为守护进程运行。如果需要,请使用“是”。注意redis在后台监控时会在pid file中写入一个pid文件。
pidfile /var/run/redis.pid (default: /var/run/redis.pid)
当运行daemonized时,redis默认在/var/run/redis.pid中写入一个pid文件。可以在此处指定自定义PID文件位置。
port 6379 (default: 6379)
接受指定端口上的连接,默认值为6379。如果指定了端口0,Redis将不会在TCP Sockt上侦听。
bind 192.168.1.100 10.0.0.1 (default: commented out, all network interfaces)
默认情况下,redis监听服务器上所有可用网络接口的连接。可以使用“bind”配置指令只监听一个或多个接口,后跟一个或多个IP地址。
logfile /var/log/redis.log (default: “”)
指定日志文件名。也可以使用空字符串强制。redis登录标准输出。请注意,如果使用标准输出进行日志记录,但使用后台监视,则日志将发送到/dev/null
databases 16 (default: 16)
设置数据库数。默认数据库为db 0,您可以使用select<dbid>在每个连接基础上选择不同的数据库,其中dbid是介于0和“databases”减 1之间的数字。
timeout 0 (default: 0)
客户端空闲N秒后关闭连接(0禁用)
dbfilename dump.rdb (default: dump.rdb)
转储数据库的文件名
dir /var/redis (default: ./)
工作目录。数据库将使用上面指定的文件名,使用'db filename'配置指令写入此目录。只追加的文件也将在此目录中创建。
总的来说,这些是最有用的配置设置,可以从中开始,不断地调整您的Redis服务器以获得最佳配置。
8. 启动/停止Server
有几种方法可以启动Redis服务器。最简单的方法就是运行redis服务器(或Windows上的redis-server.exe),而不指定任何配置。一旦启动,完整功能的Redis服务器就可以处理请求,监听默认端口6379。
下图显示了Redis服务器成功启动时Linux控制台上的典型输出。第一行警告没有配置文件,因此默认配置为“对话位置”。这也是Redis的另一特色:尽可能简单地让事情变得很容易开始,同时添加更多高级配置选项(当您真正需要时)。

一个微小变化包括传递配置文件和传入侦听连接所需的端口:
redis-server <conf> --port <port>
在windows上
redis-server.exe <conf> --port <port>
端口参数(如果指定)将覆盖配置文件中的参数。下面的图片演示了在这种情况下redis输出的外观。
通过这些方法启动的redis服务器可以通过按ctrl+c停止。
高级Linux用户熟悉init脚本,一旦系统启动,就让redis服务器自动启动是非常有用的。为此,redis发行版包括utils/redis_init_脚本中的启动脚本模板。这个脚本可以按原样使用,应该复制到标准/etc/init.d文件夹中。请注意,默认情况下,启动脚本将尝试在/etc/redis/6379.conf中查找配置文件(要获得有关这些建议和约定的详细信息,请查看http://redis.io/topics/quickstart)。
如果您想以这种方式启动redis(使用init脚本),那么应该稍微修改/etc/redis/6379.conf文件,以便设置几个重要的配置选项:
- daemonize 应设置为“yes”(默认设置为“no”)。
- pidfile 应设置为 /var/run/redis_6379.pid (对应于redis实例端口号和配置文件名约定)
- logfile 应设置为 /var/log/redis_6379.log (遵循与 pidfile一致)
- dir 应设置为 /var/redis/6379 (遵循与 pidfile and logfile一致)
请参阅基本配置部分,以获得更详细的解释,这些配置选项的含义及其含义。
9. Redis CLI概述
探索redis的最佳和最简单的方法是其命令行界面redis cli(windows上的redis-cli.exe)。它非常容易使用,而且它对每个redis命令都有简短的帮助,并且支持在命令历史上导航(通过使用上下箭头)。
当redis cli启动时,它立即尝试连接到redis实例,猜测它正在本地计算机(127.0.0.1)和默认端口(6379)上运行。如果不是这样,工具会告诉你。
同样,当主机名和端口作为命令行参数提供时,redis cli可用于连接到远程redis实例:
redis-cli -h <hostname> -p <port>
假设我们的redis服务器运行在本地计算机上,那么让我们运行redis cli并发出第一个命令,以确保服务器已准备好为请求提供服务。

ping命令是强制redis服务器发送pong作为响应的最简单、无副作用的方法,确认它正在运行并准备就绪。要了解有关ping命令的更多详细信息,请帮助ping显示一个简短的摘要。

尽管Redis CLI非常简单,但它非常有用。它不仅允许向Redis服务器发送命令,还允许更改配置、监视当前活动等等。
二:Redis常用命令
1. 基本介绍
命令是redis的基本概念。这是客户端与服务器通信的唯一方式。redis命令集非常丰富,有几种类型。每个类别对应于其操作的数据结构(或功能):
- Keys
- Strings
- Hashes
- Lists
- Sets
- Sorted Sets
- Publish / Subscribe
- Transactions, Scripting
此外,还有几个服务命令来管理服务器配置、连接和检查运行时行为。
- Connection
- Server
在本教程中,我们将继续熟悉redis命令行工具redis cli(windows上的redis-cli.exe),我们在第一个教程中简要讨论过它。在下一节中,我们将介绍所有redis命令,并尝试其中的大部分。前面的快速说明,要查看某些命令的效果,应运行redis cli的两个实例(windows上的redis-cli.exe)。
2. 键Key
尽管Redis功能丰富,但它仍然是一个密钥/价值存储库。存储在redis中的每个值都可以使用相应的键(有时是键)进行检索。本小节概述了键上的一般操作,与键的值无关。
| Command |
DEL key [key …] |
| Description |
删除一个键(或多个键)。命令返回成功删除的键数。 |
| Example |
Assuming the key mykey exists, the command deletes it. |
| Reference |
| Command |
DUMP key |
| Description |
返回存储在指定键上的值的序列化版本。 |
| Example |
Assuming the key mykey exists and is assigned the simple string “value”, the command returns its serialized representation. |
| Reference |
| Command |
EXISTS key |
| Description |
确定键是否存在。如果键存在,则返回1,否则返回0。 |
| Example |
Assuming the key mykey1 exists and mykey2 does not, the command returns 1 and 0 respectively. |
| Reference |
| Command |
EXPIRE key seconds |
| Description |
设置键的生存时间(秒)。一旦该时间间隔到期,密钥将被删除。如果键存在,则命令返回1,否则返回0。 |
| Example |
Assuming the key |
| Reference |
| Command |
EXPIREAT key timestamp |
| Description |
将键的过期时间设置为UNIX时间戳。一旦达到过期时间,密钥将被删除。如果键存在,则命令返回1,否则返回0。 |
| Example |
See |
| Reference |
| Command |
KEYS pattern |
| Description |
查找与给定模式匹配的所有键。此命令在活动服务器上执行非常危险,因为它可以匹配整个密钥集。 |
| Example |
Assuming the keys |
| Reference |
| Command |
MIGRATE host port key destination-db timeout |
| Description |
原子的将键从一个实例转移到另一个。 |
| Example |
Assuming the key |
| Reference |
| Command |
MOVE key db |
| Description |
将键移动到另一个数据库。如果键存在且移动正确,则命令返回1,否则返回0。 |
| Example |
Assuming the key |
| Reference |
| Command |
OBJECT REFCOUNT key |
| Description |
检查与键关联的Redis对象的内部: •refcount返回与指定键关联的值的引用数 •encoding返回用于存储与键关联的值的内部表示形式 •idletime返回存储在指定键上的对象处于空闲状态(读或写操作未请求)后的秒数,单位为秒。 |
| Example |
Assuming the key |
| Reference |
| Command |
PERSIST key |
| Description |
删除键过期。如果键存在并且设置了过期(生存时间)则命令返回1,否则返回0。 |
| Example |
Assuming the key |
| Reference |
| Command |
PEXPIRE key milliseconds |
| Description |
设置键的生存时间(毫秒)。一旦该时间间隔到期,密钥将被删除。如果键存在,则命令返回1,否则返回0。 |
| Example |
See |
| Reference |
| Command |
PEXPIREAT key milliseconds-timestamp |
| Description |
将键的过期时间设置为以毫秒为单位指定的UNIX时间戳。一旦达到过期时间,密钥将被删除。如果键存在,则命令返回1,否则返回0。 |
| Example |
See |
| Reference |
| Command |
PTTL key |
| Description |
获取键的生存时间(毫秒)。如果键不存在,则命令返回-2;如果键存在,则返回-1,但未设置过期(生存时间)。 |
| Example |
Assuming the key |
| Reference |
| Command |
RANDOMKEY |
| Description |
从键空间返回随机键。如果keyspace中没有键,命令将不返回任何内容。 |
| Example |
Assuming the keys |
| Reference |
| Command |
RENAME key newkey |
| Description |
重命名一个键。如果键不存在,则命令返回err no such key。请注意,如果键newkey存在,它的值将替换为键key的值。 |
| Example |
Assuming the key |
| Reference |
| Command |
RESTORE key ttl serialized-value |
| Description |
使用以前使用dump获得的提供的序列化值创建键。如果密钥存在,则命令返回err目键名称正忙。 |
| Example |
Reusing the serialized value from |
| Reference |
| Command |
TTL key |
| Description |
获取键生存的时间。如果键不存在,则命令返回-2;如果键存在,则返回-1,但未设置过期(生存时间)。 |
| Example |
See |
| Reference |
| Command |
TYPE key |
| Description |
确定存储在键处的类型。如果键不存在,该命令将返回none。 |
| Example |
Assuming the key |
| Reference |
| Command |
SCAN cursor [MATCH pattern] [COUNT count] |
| Description |
incrementally迭代空间的键。迭代开始时,光标被设置为0,和终止时,光标由服务器返回的是0。 |
| Example |
Assuming the keys |
| Reference |
3. 字符串Strings
未完待续......
三:Redis分片
1. 基本介绍
我们正在处理的数据量每天呈指数级增长。通常,当必要的数据无法装入内存,甚至物理存储空间不足时,我们会面临单个设备的硬件限制。多年来,这些问题导致业界开发了数据分片(或数据分区)解决方案,以克服这一限制。
在Redis中,数据分片(分区)是一种将所有数据跨多个Redis实例进行拆分的技术,这样每个实例将只包含键的一个子集。这样的过程允许通过添加越来越多的实例并将数据分成更小的部分(碎片或分区)来减少数据增长。不仅如此,它还意味着越来越多的计算能力可用于处理数据,有效地支持水平缩放。
尽管并非每件事都是双赢的解决方案,但需要考虑一些权衡:通过跨多个实例分割数据,查找特定密钥(或密钥)的问题成为一个问题。这就是分片(分治)方案出现的地方:数据应该按照一些一致的或固定的规则进行分片(分治),所以同一个密钥的读写操作应该转到持有(拥有)这个密钥的redis实例。
本教程的材料基于与分片和分区相关的优秀redis文档:http://redis.io/topics/partitioning
2.何时使用分片(分治)
根据Redis文档(http://redis.io/topics/partitioning),以下情况您可以考虑分片:
- 管理超大型数据库,内存过小致大量计算资源消耗在的内存调页上(否则,您将受限于使用一台计算机所能支持的内存量)
- 在多个CPU、多台计算机之间扩展其网络带宽和计算能力
- 如果您认为现在没有数据规模问题,在不久的将来您可能会遇到这样的问题,因此最好做好准备并提前考虑(请参阅计划分割(分区))。但是在这样做之前,请考虑到切分(分区)对表的复杂性和缺点:
- 通常不支持涉及多个键的操作。例如,如果两个集合(sinter)存储在映射到不同redis实例的键中,则不可能直接执行它们之间的交集。
- 涉及多个密钥映射到不同redis实例的事务是不可能的。
- 分区是基于密钥的,因此单个密钥关联的大数据集(非常大的排序集或列表)是不能被分片(分治)的。
- 备份和持久性管理要复杂得多:您必须处理多个RDB/AOF文件,备份涉及多个实例中RDB文件的聚合(合并)。
- 在运行时添加和删除实例可能会导致数据不平衡,除非您已经计划了这一点(请参见规划切分(分区))。
3.分片(分治)方案
根据您的数据模式,有几种经过实践证明的切分(分区)方案可以与Redis一起使用。
范围划分
它是通过将对象范围映射到特定的redis实例来实现的。例如,假设我们正在存储一些用户数据,并且每个用户都有其唯一标识符(ID)。在我们的分区方案中,我们可以定义从0到10000的用户进入实例redis 1,而从10001到20000的用户进入实例redis 2等等。该方案的缺点是,需要维护范围和实例之间的映射,并且在redis中保存的对象种类(用户、产品等)等映射的数量应该是相同的。
哈希划分
此方案适用于任何键,但涉及哈希函数:此函数应将键名映射到某个数字。假设我们有这样一个函数(我们称之为hash_func),这样一个方案的工作原理如下:
获取密钥名并使用hash_func将其映射到一个数字
将生成的数字映射到Redis实例中(例如,使用除以模块操作)
哈希函数的选择非常重要。好的散列函数确保密钥均匀地分布在所有redis实例上,因此不会在任何单个实例上累积太多。
连续哈希
它是散列分区的一种高级形式,被许多数据分片(分区)解决方案广泛使用。
4.切分(分区)实现
从实现的角度来看,根据应用程序的体系结构,有几种可能的数据分片(分区)实现:
客户端分片
客户机直接选择正确的实例来写入或读取给定的密钥。
代理辅助分片
客户端向支持redis协议的代理发送请求,而不是直接向正确的redis实例发送请求。代理将确保转发代理将确保根据配置的分区方案将请求转发到正确的redis实例,并将回复发送回客户端(最著名的实现是twemproxy from twitter,https://github.com/twitter/twemproxy)。
查询路由
客户机将查询发送到一个随机的redis实例,该实例将确保将查询转发到正确的实例。查询路由的混合形式假定客户机被重定向到正确的实例(但查询不会直接从一个redis实例转发到另一个),并将在本教程的第5部分redis clustering中介绍。
5.分片(分区)规划
如前所述,一旦您开始跨多个redis实例使用数据分片(分区),在运行时添加和删除实例可能会很困难。对于redis,您经常使用的一种技术称为预分片(http://redis.io/topics/partitioning)。
预分片处理的思想是从一开始就从很多实例开始(但实际节点/服务器的数量很少或只有一个)。实例的数量可能会有所不同,而且自启动以来可能会很大(对于大多数用例来说,32或64个实例就足够了)。在一台服务器上运行64个redis实例是完全可能的,因为redis非常轻量。
这样,随着数据存储需求的增长,需要更多的redis节点/服务器来处理它,可以简单地将实例从一个服务器移动到另一个服务器。例如,如果您只有一台服务器,并且添加了一台服务器,那么第一台服务器上的一半redis实例应该移动到第二台服务器上。这种技巧可能会一直持续下去,直到每个服务器/节点都有一个redis实例时。
不过要记住的一点是:如果您将redis用作数据的内存缓存(而不是持久数据存储),则可能不需要使用预分片。连续的哈希实现通常能够在运行时新增或删除实例。例如,如果给定键不能被一个实例处理,则该键将被其他实例处理。或者,如果添加一个新实例,新增的部分键将转移到新实例上。
6.分片(分区)和热备份
跨多个实例分割(分区)数据并不能解决数据安全和冗余问题。如果其中一个碎片(分区)由于硬件故障而死亡,而您没有备份来恢复数据,这意味着您将永远丢失数据。
这就是为什么分片(分区)与备份并排进行的原因。如果将redis用作持久性数据存储,最好为不同服务器/节点上的每个shard(分区)至少配置一个副本。它可能会使您的容量需求翻倍,但是让您的数据安全更为重要。
热备份的配置与本教程第3部分redis replication中介绍的没有任何不同。
7.使用Twemproxy分片
twemproxy(又称坚果钳),由twitter开发并开源(https://github.com/twitter/twemproxy),被广泛使用,非常快速和轻量级的redis代理。虽然它有许多特性,但我们主要介绍它向redis添加分片(分区)的能力:
跨多个服务器自动共享数据
支持多种哈希模式,包括连续的哈希和分发请求
Twemproxy(坚果钳)非常容易安装和配置。本教程的最新版本是0.3.0,可以从http://code.google.com/p/twemproxy/downloads/list下载。安装非常简单。
下载
wget http://twemproxy.googlecode.com/files/nutcracker-0.3.0.tar.gz
解压
tar xfz nutcracker-0.3.0.tar.gz
构建(您需要的唯一预安装包是gcc和make)。
cd nutcracker-0.3.0
./configure
make
安装
sudo make install
Twemproxy(坚果钳)默认位于/usr/local/sbin/nupcracker。安装后,最重要(不过,相当简单)的部分是其配置。
Twemproxy(坚果钳)使用yaml作为配置文件格式(http://www.yaml.org/)。在twemproxy(坚果钳)支持的许多设置中,我们将选择与分片(分区)相关的设置。
| Setting |
listen: name:port | ip:port |
| Description |
此服务链接池的侦听地址和端口(名称:端口或IP:端口)。 |
| Example |
listen: 127.0.0.1:22121 |
| Setting |
hash: <function> |
| Description |
哈希函数的名称。可能的值是:– one_at_a_time – md5 (http://en.wikipedia.org/wiki/MD5) – crc16 (http://en.wikipedia.org/wiki/Cyclic_redundancy_check) – crc32 (与libmemcached兼容的crc32实现) – crc32a (根据规范正确执行CRC32) – fnv1_64 (http://en.wikipedia.org/wiki/Fowler–Noll–Vo_hash_function) – fnv1a_64 (http://en.wikipedia.org/wiki/Fowler–Noll–Vo_hash_function) – fnv1_32 (http://en.wikipedia.org/wiki/Fowler–Noll–Vo_hash_function) – fnv1a_32 (http://en.wikipedia.org/wiki/Fowler–Noll–Vo_hash_function) – hsieh (http://www.azillionmonkeys.com/qed/hash.html) – murmur (http://en.wikipedia.org/wiki/MurmurHash) – Jenkins (http://en.wikipedia.org/wiki/Jenkins_hash_function) |
| Example |
hash: fnv1a_64 |
| Setting |
distribution: <mode> |
| Description |
键的分发模式 (see please http://en.wikipedia.org/wiki/Consistent_hashing). 可能的值: – ketama – modula – random |
| Example |
distribution: ketama |
| Setting |
redis: true |false |
| Description |
一个布尔值,用于控制服务器池是否使用redis或memcached协议。因为我们将只使用redis,所以此设置应设置为true。默认为false。 |
| Example |
redis: true |
| Setting |
auto_eject_hosts: true | false |
| Description |
一个布尔值,用于控制当服务器宕机server_failure_limit后是否应弹出服务器故障。默认为false。 |
| Example |
auto_eject_hosts: false |
| Setting |
server_retry_timeout: <milliseconds> |
| Description |
当宕机提示设置为真时,重连间隔(毫秒)。默认为30000毫秒。 |
| Example |
server_retry_timeout: 30000 |
| Setting |
server_failure_limit: <number> |
| Description |
The number of consecutive failures on a server that would lead to it being temporarily ejected when auto_eject_host is set to true. Defaults to 2. |
| Example |
server_failure_limit: 2 |
| Setting |
servers: – name:port:weight | ip:port:weight – name:port:weight | ip:port:weight |
| Description |
特定服务池的服务器地址、端口和重量(名称/IP:端口:重量)列表。 |
| Example |
servers: – 127.0.0.1:6379:1 – 127.0.0.1:6380:1 |
我们将构建一个包含三个Redis实例(服务池)的简单拓扑,并在它们前面配置twemproxy (nutcracker) ,如下图所示:
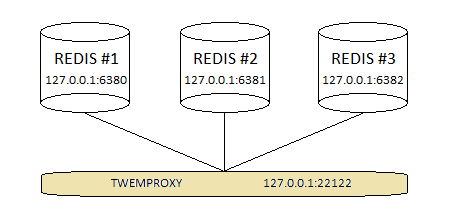
Twemproxy发行版的的配置文件conf/nutcracker.yml 是做为配置示例的良好开端。至于演示,我们将从下面的分片的服务池开始,反映上面所示的拓扑结构。
文件Nutcher-Sharded.yml:
sharded:
listen: 127.0.0.1:22122
hash: fnv1a_64
distribution: ketama
auto_eject_hosts: true
redis: true
server_retry_timeout: 2000
server_failure_limit: 2
servers:
- 127.0.0.1:6380:1
- 127.0.0.1:6381:1
- 127.0.0.1:6382:1
分片服务池使用ketama连续进行密钥分发,密钥散列器设置为fnv1a_64。
在启动Twemproxy(胡桃钳)之前,我们应该在端口6380、6381和6382上启动并运行所有三个Redis实例。
redis-server --port 6380
redis-server --port 6381
redis-server --port 6382
之后,可以使用以下命令启动具有示例配置的Twemproxy(坚果钳)实例:
nutcracker -c nutcracker-sharded.yml

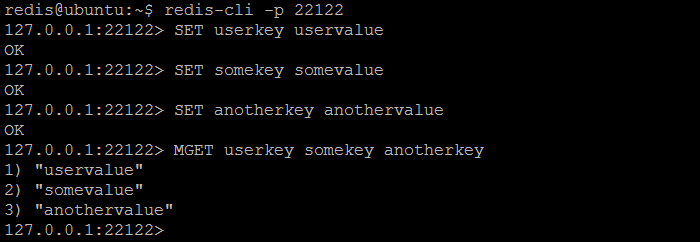
实时验证切片(分区)的最简单方法是连接到Twemproxy,存储两个键/值对,然后尝试从每个redis实例中获取所有存储的键:每个键只能由一个实例返回,其他的应该返回(nil)。尽管如此,从Twemproxy查询相同的键将始终导致先前存储的值。根据我们的示例配置,Twemproxy正在监听端口22122,可以使用常规的redis cli工具进行连接。三个键userkey、somekey和anotherkey将被设置为一些值。
现在,如果我们从Twemproxy服务池中查询每个redis实例,其中一些键(userkey、somekey、anotherkey)将由某些实例解析,但不同时被其他实例解析。
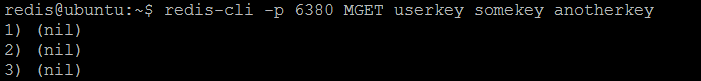

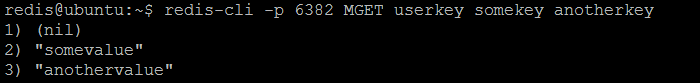
有一个有趣的问题可以问:为什么key是这样存储的?答案是配置的散列函数:这些键在服务器池中的所有redis实例中均匀地分布。但是为了实现均衡(偶数或随机)分布,根据应用程序使用的密钥命名模式,应该非常仔细地选择配置的哈希函数。如我们的示例所示,键并不是均匀分布在所有实例中(第一个实例没有任何键,第二个实例有一个键,第三个实例有两个键)。
最后一点要注意的是:尽管Twemproxy不支持Redis协议,正如在何时使用分片(分区)部分中讨论的限制,并不是所有命令都受支持。
有关Twemproxy(胡桃钳)的更多详细信息,请参阅https://github.com/twitter/twemproxy,它提供了非常好的最新文档。
四:Redis热备份
1. 基本介绍
热备份是任何面向数据的解决方案的一个非常重要的特性:复杂的关系数据库或简单的键/值存储。热备份允许跨多个节点(服务器)、数据中心和/或地理区域分发多个数据副本。
热备份是可靠的、水平可扩展和容错系统的基础:一旦一个数据节点(服务器)失败,另一个具有失败节点的(大多数)最新数据的节点将接手查询或请求。更不用说能够在主节点和从节点(只读副本)之间有效地读写分离。一些有趣的软件系统模式基于这样的策略,例如CQR(命令查询责任分离)和热备的缓存解决方案。
热备主要有两类:
主–主热备(或active–active)
主-从热备(或主动-被动)。
尽管master–master是自动故障转移的最佳选择,但它非常复杂,只有很少的数据解决方案拥有它。在此文章被编写时,redis 2.8.4只支持主从热备。
2.Reids热备
本节基于优秀的Redis文档。如前所述,Redis支持主-从复制,允许系统的精确副本。
有关Redis热备一些要点:
- Redis使用异步热备
- redis master可以有多个slave
- Redis slave可以接受来自其他slave的连接(级联热备)
- Redis热备在master端是非阻塞的:当一个或多个slave执行初始同步时,master将继续处理查询。
- Redis热备可以配置为Slave无阻塞:当Slave执行初始同步时,它可以使用旧版本的数据集处理查询(请参见高级热备配置,Slave服务过时数据设置 Advanced Replication Configuration,)
- redis热备非常方便,有几个推荐的用例。首先,它可以用于拥有多个从机进行只读查询或简单地进行数据冗余。其次,还可以使用热备来避免主数据集将整个数据集写入磁盘写入:可以让Slave定期持久化。
此外,Redis 2.8中最近的一个非常重要的增强功能:主设备和从设备通常能够在备份链路断开恢复后继续之前的备份,而不需要完全重新同步。实际上,如果主从之间发生网络故障,从机以后可以增量提取(而不是整个数据集)来赶上主机。
3.基本热备
Slave(或副本)配置非常简单,基本配置只需要在redis.conf文件中设置一参数slaveof:主IP地址和端口。值得一提的是,redis从系统默认以只读模式运行。此行为由配置文件redis.conf中的slave read only选项管理,并且可以在slave使用config set命令运行时进行更改(请参阅本教程的第2部分:redis命令-使用redis命令行)。只读从系统将拒绝所有写入命令。
反过来,非只读从系统将接受写命令。请注意,以这种方式写入从系统的数据是短暂的,当从系统和主系统重新同步或从系统重新启动时,数据将消失。
为了在实践中了解redis复制配置有多简单,我们将配置一个主服务器和两个从服务器(副本)。一个从(副本)将具有默认的只读模式(在下面的图片上用绿色标记),另一个将被配置为支持写操作,让我们实际操作一下。
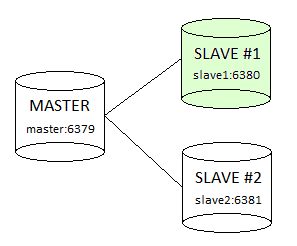
对于master和slaves,我们将使用redis发行版中的配置模板redis.conf(请参见本教程第1部分,redis安装)。
- “master,只需要复制redis.conf到redis-master.conf
cp redis.conf redis-master.conf
- 使用以下命令启动
redis-server redis-master.conf
- 对于slave1只需要复制redis.conf到redis-master.conf
cp redis.conf redis-slave1.conf
- 并在redis-slave1.conf中添加以下配置设置(我们假设redis master的主机名为master):
slaveof master 6379
- 然后使用此配置启动Redis服务器,将默认端口修改为6380:
- redis-server redis-slave1.conf --port 6380
- 启动后,从机(副本)立即与主机同步(如下图所示)。
- 对于slave2只需要复制redis.conf到redis-master.conf
cp redis.conf redis-slave2.conf
- 并在redis-slave1.conf中添加以下配置设置(我们假设redis master的主机名为master):
slaveof master 6379
- 然后使用此配置启动Redis服务器,将默认端口修改为6380:
- redis-server redis-slave1.conf --port 6381
- 启动后,从机(副本)立即与主机同步(如下图所示)。
此时,我们有一个拓扑结构,其中一个Redis主服务器和两个Redis从服务器(副本)连接到它。
4.验证热备是否有效
有一些简单的技术可以验证redis热备按预期工作。最简单的方法是在主服务器上设置一些键,然后在每个从服务器上为这个键发出get命令,以查看它是否被备份。


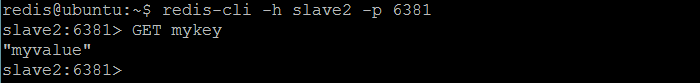
尝试在从机1上发出任何写入命令都会导致错误,因为它是在只读模式下配置的(如下图所示)。

因此,在从系统2上发出任何写入命令都是合法的,但是一旦从系统与主系统重新同步,所有这些短暂的数据就消失了。

5.在运行时配置热备
如果您已经运行了多个独立的Redis服务器,则可以在不重新启动其中一个的情况下配置主从热备,这要归功于Redis运行时配置功能。为了演示这一点,我们将在端口6390上运行一个常规的redis实例,然后使其成为另一个redis实例(master)的从机。那么让我们来看看独立实例:
redis-server --port 6390
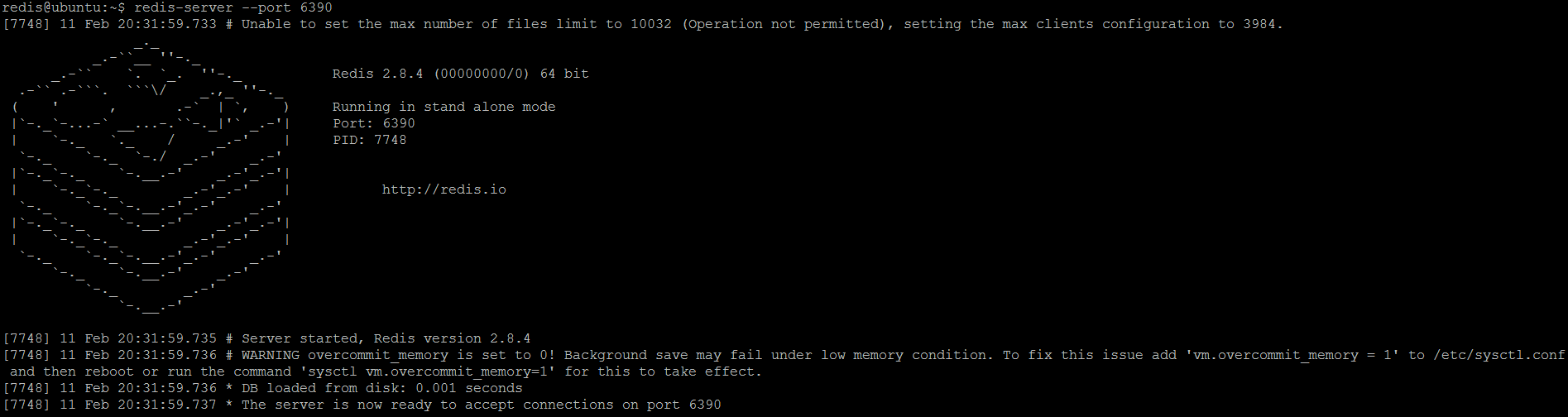
现在,让我们使用redis cli和slave of命令连接到此实例,我们将使此实例成为运行主实例的从(副本)。

实例立即与master执行完全同步。

也可以同时使用config set命令将slave的默认只读模式更改为读写模式。

可以随时使用config get命令查询当前的配置设置。以下示例检索从属只读设置,以确保其值更改为“是”。

6.高级热备配置
有相当多的设置在实际场景中非常有用,这些场景超出了我们的基本示例。在本节中,我们将介绍其中的大部分内容,以便指出如何使热备更加健壮。
redis master可以配置为在指定秒数时间内仅当至少有n个从服务器当前连接到它时才接受写命令(但不可能确保从服务器实际接收到给定的写操作,仅在没有足够的SLAV的情况下,才限制写入)。
配置设置支持延迟不超过最大秒数(从系统最大延迟)的最小从系统数(要写入的最小从系统数)。如果不满足这些条件,主机将以错误的方式回复,而不会接受写入。
| Setting |
min-slaves-to-write <number of slaves> |
| Description |
设置<number of slaves>以便继续执行写入命令。<number of slaves>slaves需要处于“在线”状态。将值设置为0将禁用此功能。 |
| Defaults |
By default min-slaves-to-write is set to 0 (feature disabled) |
| Example |
min-slaves-to-write 3 |
| Setting |
min-slaves-max-lag <number of seconds> |
| Description |
以秒为单位设置必须小于或等于指定值的滞后。它是从从系统接收到的最后一个ping计算出来的(通常是每秒发送一次)。将值设置为0将禁用该功能。 |
| Defaults |
By default min-slaves-max-lag is set to 10 |
| Example |
min-slaves-max-lag 10 |
如果主服务器受密码保护(使用RequirePass配置指令),则可以在启动复制同步过程之前通知从服务器进行身份验证,否则主服务器将拒绝从服务器请求。
| Setting |
masterauth |
| Description |
配置用于与master进行身份验证的密码 |
| Defaults |
Commented out (no authentication ) |
| Example |
masterauth mysectetpassword |
当从属服务器与主服务器失去连接,或者热备仍在进行中时,从属服务器可以以两种不同的方式进行操作:
- 如果slave-serve-stale数据设置为“是”(默认值),slave仍将回复客户机请求,可能数据已过期,或者如果这是第一次同步,则数据集可能为空。
- 如果slave-serve-stale数据设置为“否”,则slave将对除info([4])和slave of([2])之外的所有类型的命令回复错误“与正在进行的主服务器同步”。
| Setting |
slave-serve-stale-data yes | no |
| Description |
配置从设备与主设备失去连接时的行为 |
| Defaults |
By default slave-serve-stale-data is set to yes |
| Example |
slave-serve-stale-data yes |
从服务器以预先定义的间隔向服务器发送ping。允许使用repl-ping-u slave-period选项更改此间隔。
| Setting |
repl-ping-slave-period <number of seconds> |
| Description |
配置从服务器向服务器发送ping的频率 |
| Defaults |
By default repl-ping-slave-period is set to 10 |
| Example |
repl-ping-slave-period 10 |
可以为主服务器和从服务器配置热备超时(从从服务器的角度来看,当从服务器决定主服务器不可用时,超时;从主机的角度来看,当主服务器决定从服务器不可用时,超时):
- 从从从机的角度看,同步期间的批量传输I/O
- 从从从系统的角度看主机超时
- 从master的角度看slaves超时
| Setting |
repl-timeout <number of seconds> |
| Description |
配置备份超时。必须确保该值大于为repl ping slave period指定的值,否则每次主设备和从设备之间的通信量低时都会检测到超时。 |
| Defaults |
By default repl-timeout is set to 60 |
| Example |
repl-timeout 60 |
为了备份的目的,Redis使用repl disable tcp nodelay选项支持一些低级的tcp协议调优。如果设置为“是”,Redis服务器将使用较少的TCP数据包和较少的带宽向从属服务器发送数据。但这可能会增加数据出现在从系统端的延迟(使用默认配置的Linux内核时,最长为40毫秒)。激活此设置可以被视为在非常高的流量条件下或在主设备和从设备距离很多跃点时有用。默认情况下,它被设置为“否”,这意味着数据出现在从机端的延迟将减少,但更多的带宽将用于备份。
| Setting |
repl-disable-tcp-nodelay yes | no |
| Description |
同步后 禁用/启用从属套接字上的TCP节点 |
| Defaults |
By default repl-disable-tcp-nodelay is set to “no” (optimized for low latency) |
| Example |
repl-disable-tcp-nodelay no |
有两个配置参数可以帮助master管理从机断开连接和部分备份:备份backlog大小和backlog缓冲区生存时间。backlog是一个缓冲区,当从机断开一段时间后,它会累积从机数据,因此当从机想要再次重新连接时,通常不需要完全重新同步,部分重新同步就足够了(只传递断开连接时从机丢失的数据部分)。复制积压量越大,从机断开连接的时间越长,以后将能够执行部分重新同步。只有在至少连接了一个从机之后,才会分配积压工作。
| Setting |
repl-backlog-size |
| Description |
设置备份积压量大小 |
| Defaults |
By default repl-backlog-size is set to “1mb” |
| Example |
repl-backlog-size 1mb |
在主服务器一段时间内不再连接从服务器之后,积压的工作将被释放。repl backlog ttl选项配置要释放backlog缓冲区所需的时间(从最后一个从机断开时开始)。
| Setting |
repl-backlog-ttl <number of seconds> |
| Description |
将backlog缓冲区时间设置为释放前的生存时间。值为0表示永不释放积压工作。 |
| Defaults |
By default repl-backlog-ttl is set to “3600” |
| Example |
repl-backlog-ttl 3600 |
最后一个非常有趣的设置是,为Redis Sentinel(哨兵)使用的从设备(副本)分配优先级,以便在主设备无法正常工作时选择要升级为主设备的从设备。优先级低的slave被认为更适合提升,例如,如果有三个优先级为10、100、25的slave,redis sentinel将选择优先级为10的slave(最低)。但是一个特殊的0优先级标志着从系统不能执行master的角色,所以redis sentinel永远不会选择优先级为0的从系统进行提升。
| Setting |
slave-priority <number> |
| Description |
从属优先级是redis在Info中输出的整数。 |
| Defaults |
By default slave-priority is set 100 |
| Example |
slave-priority 100 |
Redis Sentinel将在本教程稍后讨论。
五:Redis群集
1. 基本介绍
本教程的最后一部分专门介绍Redis集群的最新、最酷但仍处于实验阶段(还没有准备好生产)的功能。本部分的材料主要基于Redis文档部分http://redis.io/topics/cluster-tutorial和http://redis.io/topics/cluster-spec。Redis群集是一种分布式Redis部署,旨在解决以下主要目标:
- 能够在多个节点之间自动分区数据集
- 提供高性能和线性可扩展性的能力
- 能够保留来自与大多数节点连接的客户端的所有写入(写入安全性/一致性)
- 每个不再可访问的主节点至少有一个可访问的从属节点(可用性),能够在网络分区中生存下来,其中大多数主节点都是可访问的,
redis cluster是数据分片(分区)的替代(但更高级)解决方案,我们在本教程的第4部分Redis sharding中已经看到了这一点(但不是使用第三方工具,所有功能都是由redis本身提供的,并带有额外的配置)。为了实现高可用性,Redis集群还严重依赖于主从热备,我们在本教程的第3部分Redis复制中已经看到了这一点。
2.Redis群集的限制
首先,所有与redis集群相关的功能都处于实验模式,还没有准备好投入生产使用。
构建任何高可用性的分布式系统都非常困难,但Redis正在努力使之成为可能。我们需要注意一些限制,并且要做一些权衡,其中一些我们已经提到过了,但是这里也值得重复。
首先,redis集群(sinter、sunion等)不支持处理多个密钥的命令。这种功能需要在redis节点之间移动数据,这将使redis集群无法在负载下提供可接受的性能和可预测的行为。通常,命令的涉及到当前redis节点中没有的键的所有操作都不会实现。
其次,redis集群不支持多个数据库,比如独立版本的redis。只有一个数据库0,不允许SELECT。
第三,redis集群中的节点不会将命令通过代理转到存储给定Key的正确节点,而是将client重定向到为持有指定范围的key的节点(所谓的查询路由的混合形式)。最终,客户机获得集群拓扑的最新表示,并且知道哪个节点为哪个键子集服务,可以直接联系正确的节点,以便发送给定的命令(实际上返回到客户机端分区)。
3.分片(分区)方案
正如我们在第4部分Redis Sharding中所知道的,有两种数据分片(分区)方案用于分割数据,连续散列是最先进和应用最广泛的。redis集群不使用连续的散列,而是使用不同形式的数据拆分,每个键都属于所谓哈希空间。
redis集群中有16384个散列槽,为了计算给定Key的散列槽是什么,计算该Key的crc16函数(http://en.wikipedia.org/wiki/cyclic_redundancy_check),然后将16384的模应用到其结果中。
redis集群中的每个节点都负责散列槽的一个子集。例如,让我们考虑一个具有四个redis节点的集群1、2、3和4。这可能会给我们提供以下散列槽分布:
- redis节点1包含从0到4096的哈希空间
- redis节点2包含4097到8192之间的哈希空间
- redis节点3包含从8193到12288的哈希空间
- redis节点4包含从12289到16383的哈希空间
这种分片(分区)方案允许轻松更改集群的拓扑结构(添加和删除节点)。例如,如果需要添加一个新的节点5,那么应该将节点1、2、3和4的一些散列槽移动到节点5。同样,如果需要从集群中删除节点3,则节点3提供的散列槽应移动到节点1和2。当节点3变为空时,它可以从集群中永久删除。
现在最好的部分是:由于将哈希槽从一个节点移动到另一个节点不需要停止正在进行的操作,因此添加和删除节点(或更改节点所占哈希槽的百分比)不需要任何停机时间。
在本教程的后面,我们将回到这个例子,并用三个redis主节点(每个节点由一个从节点支持)构建实际的集群。当redis集群运行时,我们将添加和删除一些节点,以了解如何实时重新分配散列槽。
3. 1 Key的哈希标记
redis分片(分区)方案支持的非常有趣的特性称为Key散列标签。散列标记是一种确保在同一散列槽中分配两个(或多个)键的技术。
为了支持散列标记,散列槽的计算方式不同。如果键包含一个“{…}”模式,那么只有“{”和“}”之间的子字符串被散列,以便获得散列槽(如果键名中多次出现“{”或“}”,则会发生一些规则,在http://redis.io/topics/cluster spec中进行相关描述)。
Twemproxy(坚果钳),我们在第4部分,redis sharding中使用过,它还允许按照相同的规则配置用于密钥散列的散列标签。
4.Redis集群概述
在redis集群中,所有节点都持有全局Key集(shard或partition)的一部分。此外,每个节点都保持集群的状态,包括散列槽映射,以便将客户机重定向到给定密钥的正确节点。redis集群中的所有节点都能够自动发现其他节点,检测到无法访问或不能按预期工作的节点,并在需要时执行从节点到主选择。
关于在http://redis.io/topics/cluster-spec中描述的实现细节,集群中的所有节点都使用带有二进制协议(集群总线)的TCP进行连接,以便每个节点都使用集群总线连接到集群中的每个其他节点(这意味着在n个节点的redis集群中,每个节点都有n–1个传出的TCP连接以及n–1个传入TCP连接)。这些TCP连接一直保持活动状态。节点使用Gossip协议(http://en.wikipedia.org/wiki/Gossip_protocol)来传播集群状态,发现新节点,确保所有节点都正常工作,并在集群中传播发布/订阅消息。
redis集群中的每个节点都有一个唯一的ID(名称)。节点ID(名称)是160位随机数的十六进制表示,在第一次启动节点时获得。节点将其ID(名称)保存在节点配置文件中(默认情况下,nodes.conf),并将永远使用相同的ID(名称)(或者至少只要节点配置文件未被删除)。
节点ID(名称)用于标识整个redis集群中的每个节点。给定节点可以更改其IP地址,而无需更改其ID(名称)。集群还能够检测IP或/和端口的变化,并使用集群总线上运行的Gossip协议广播这些信息。此外,每个节点都有一些与它相关的其他信息,redis集群中的所有其他节点都应该知道:
- 节点所在的IP地址和TCP端口
- 一组标志(主、从……)
- 由节点提供服务的一组散列槽(请参阅切分(分区)方案)
- 上次使用群集总线发送ping数据包时
- 上次收到响应的pong包时间
- 节点标记为失败的时间
- 此节点的从服务器数量
- 主节点ID(名称),如果该节点是从节点(如果是主节点,则为零)
- 使用cluster nodes命令可以获得其中一些信息(请参阅redis cluster命令一节)。
5.集群的一致性、可用性和可扩展性
Redis集群是一个分布式系统。良好的分布式系统具有可扩展性,能够在规模上提供更好的性能。但是,在任何分布式系统中,任何组件都可能在任何时候发生故障,并且系统应该在发生此类故障时(尤其是在它是数据存储的情况下)提供一些保证。在本节中,我们将简要介绍Redis在一致性、可用性和可扩展性方面所做的一些高级权衡。在http://redis.io/topics/cluster-spec和http://redis.io/topics/cluster-tutorial上可以找到更深入的见解和细节。请注意,redis集群的发展非常迅速,本节讨论的一些保证可能不再适用。
5.1一致性
redis集群不能保证强一致性,但是它能尽量保留客户端执行的所有写入操作。不幸的是,这并不总是可能的。因为redis集群在主节点和从节点之间使用异步复制,所以在网络传输期间,总是有可能丢失写操作的传输期间。如果主节点死了而没有写入到从节点,则写入将永远丢失(如果长时间无法访问主节点,并且其中一个从节点被提升为主节点)。
5.2可用性
Redis群集在网络故障的情况可用性不高。在大多数网络故障的情况,假设每个不可到达的主机至少一个从机,redis集群仍然具备高可用性。这意味着redis集群可以在集群中的几个节点的故障中生存下来,但不能在大的网络故障中生存。例如,让我们考虑具有n个主节点(m1、m2、m3)和n个从节点(s1、s2、s3,每个主节点只有一个从节点)的redis集群。如果由于网络分区而无法访问任何一个主节点(假设它是m2),那么大多数集群仍然可用(并且s2将升级为主节点)。稍后,如果任何其他主节点或从节点变得不可访问(s2除外),那么集群仍然可用。但是请注意,如果节点s2由于某种原因出现故障,redis集群将无法继续运行(因为主m2和从s2都不可用)。
5.3可伸缩性
我们已经从部分切分(分区)方案中知道,redis集群节点不会将命令直接转发给给定密钥的正确节点,而是重定向客户机。客户机最终会获得一个完整的映射,其中节点为键的哪个子集提供服务,并且可以直接与正确的节点联系。因此,Redis集群能够线性扩展(添加更多节点会带来更好的性能),因为所有支持的操作都是以与单个Redis实例完全相同的方式处理的,没有额外的开销。
6.安装带有群集支持的Redis
Redis群集目前仅在不稳定的版本中可用。目前最新的不稳定版本是3.0.0-beta1,可以从http://redis.io/download下载。请注意,仅提供Linux发行版,Windows端口尚不可用。
使用集群安装Redis分发版与本教程第1部分“Redis安装”中描述的常规Redis安装没有区别,并遵循相同的步骤:
wget https://github.com/antirez/redis/archive/3.0.0-beta1.tar.gz
tar xf 3.0.0-beta1.tar.gz
cd redis-3.0.0-beta1/
make
make test
sudo make install
在最后一步之后,通常可执行文件将被安装在/USR/local/bin 文件夹。
7.配置Redis群集
无法使用普通redis实例和常规配置创建redis群集。相反,一些空的redis实例应该在特殊的集群模式下运行。为此,应使用群集的特殊配置运行实例(配置文件中的cluster enabled指令应设置为“yes”),以便启用特定于群集的功能和命令。
运行具有群集模式支持的Redis实例所需的最小设置集包括以下设置。
cluster-enabled yes (default: no)
为此实例启用Redis群集模式
cluster config file nodes.conf(默认值:nodes.conf)
存储此实例配置的文件的路径。这个文件不应该被访问,它只是由redis集群实例在启动时生成的,每次需要时都会更新(请参见Redis集群一节)。
cluster-node-timeout5000
超时(以毫秒为单位),在此时间之后,故障检测算法将认为非响应实例失败。正如我们在部分分片(分区)方案中提到的,我们将配置并运行一个实时的redis集群,其中有三个redis主节点(master1、master2、master3),每个主节点都由redis从节点(slave1、slave2、slave3)支持,如下图所示。
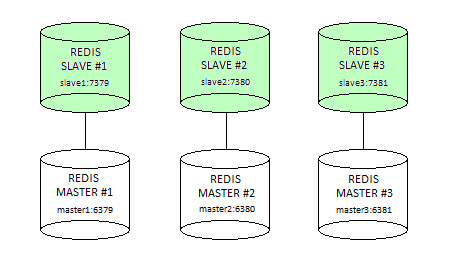
在这一过程中,我们将探讨大多数redis集群功能,但在此之前,让我们从主服务器和从服务器的配置开始。为了使配置足够简单,我们将从集群正常运行所需的最小设置开始。
7.1配置redis集群主节点
redis主节点的最小配置如下:
redis节点master1(redis-master1.conf)
port 6379
cluster-enabled yes
cluster-config-file nodes.conf
cluster-node-timeout 5000
appendonly yes
redis节点master2(redis-master2.conf)
port 6380
cluster-enabled yes
cluster-config-file nodes.conf
cluster-node-timeout 5000
appendonly yes
redis节点master3(redis-master3.conf)
port 6381
cluster-enabled yes
cluster-config-file nodes.conf
cluster-node-timeout 5000
appendonly yes
配置文件准备好后,我们可以逐个启动redis主节点,将配置作为命令行参数提供。
redis服务器redis-master1.conf
redis服务器redis-master2.conf
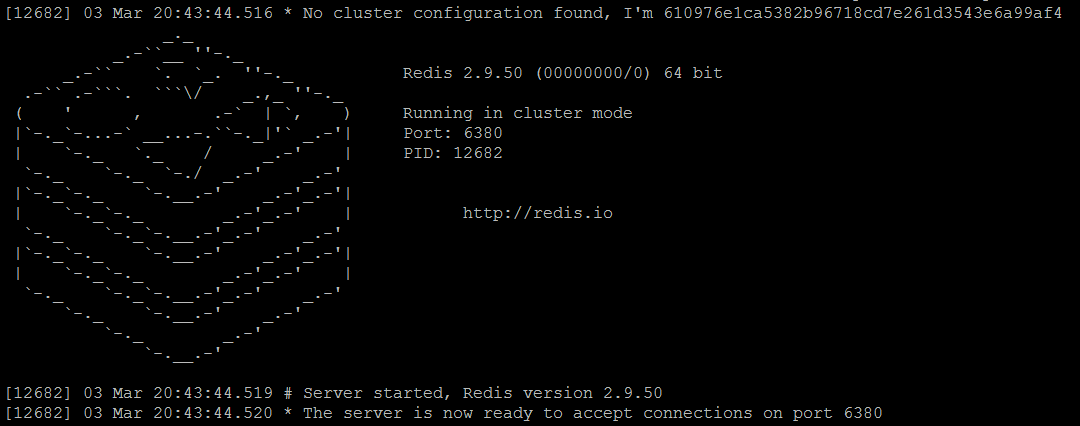
redis服务器redis-master3.conf
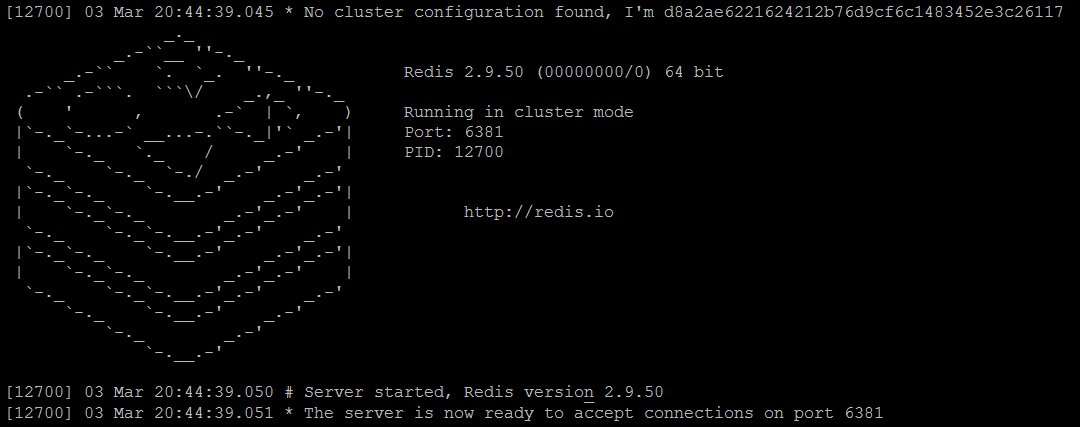
与独立Redis实例的控制台输出相比,有两个明显的区别:
- 开始时,每个节点都会生成其唯一的ID(名称),正如我们在Redis集群中所讨论的那样,请注意,这个值只在第一次运行时生成,然后重用。
- 每个实例都在群集模式下运行
- 此外,对于每个正在运行的实例,都有一个使用当前节点ID(名称)和一些附加信息创建的文件nodes.conf
此时,我们有三个redis主节点以集群模式运行,但实际上还没有形成集群(每个redis主节点只看到自己,而不看到其他节点)。为了验证这一点,我们可以分别在每个实例上运行cluster nodes命令(请参阅please redis cluster commands部分),并观察实际情况。

为了形成集群,redis节点(以集群模式运行)应该通过cluster meet命令连接在一起(请参见redis cluster commands部分)。不幸的是,该命令只接受IP地址,而不接受主机名。在我们的拓扑结构中,master1的IP地址为192.168.1.105,master2的IP地址为192.168.2.105,master3的IP地址为192.168.3.105。有了IP地址,让我们针对master1节点发出命令。

现在,如果我们重新运行cluster nodes命令,结果应该是完全不同的。



cluster nodes命令的输出看起来有点神秘,需要对每列的含义进行一些解释。
| Column 1 |
|
| Column 2 |
|
| Column 3 |
Flags: master, slave, myself, fail, … |
| Column 4 |
If it is a slave, the |
| Column 5 |
Time of the last pending PING still waiting for a reply |
| Column 6 |
Time of the last PONG received |
| Column 7 |
Configuration epoch for this node (see the please http://redis.io/topics/cluster-spec) |
| Column 8 |
Status of the link to this node |
| Column 9 |
|
最后一列,hash slots servied,没有在输出中设置,这是一个原因:我们还没有将hash slots分配给主节点,这就是我们现在要做的。散列槽可以通过在特定群集节点上使用cluster addslots(请参见redis cluster commands)命令(并分别使用cluster delslots取消分配)分配给节点。不幸的是,无法分配散列槽范围(如0-5400),但应单独分配每个散列槽(总共16384个)。克服这一限制的最简单方法之一是使用一些shell脚本。由于集群中只有三个redis主节点,16384个散列槽的范围可以这样分割:
redis节点master1包含哈希槽0–5400
for slot in {0..5400}; do redis-cli -h master1 -p 6379 CLUSTER ADDSLOTS $slot; done;
redis节点master2包含哈希槽5401 – 10800
for slot in {5400..10800}; do redis-cli -h master2 -p 6380 CLUSTER ADDSLOTS $slot; done;
redis节点master3包含哈希槽10801 – 16383
for slot in {10801..16383}; do redis-cli -h master3 -p 6381 CLUSTER ADDSLOTS $slot; done;
如果我们再次运行cluster nodes命令,最后一列将填充每个主节点提供的适当散列槽(与我们以前分配给节点的散列槽范围完全匹配)。

7.2配置redis集群从节点和备份
为了完成我们的redis集群,我们需要向每个运行的redis主节点添加一个从节点。尽管本教程的第3部分redis replication已经足够好地涵盖了备份配置,但是redis集群的做法不同。从一开始,运行和配置从系统的过程与主系统的过程没有区别(唯一的区别是端口号)。
redis节点slave1(redis-slave1.conf)
port 7379
cluster-enabled yes
cluster-config-file nodes.conf
cluster-node-timeout 5000
appendonly yes
redis节点slave2(redis-slave2.conf)
port 7380
cluster-enabled yes
cluster-config-file nodes.conf
cluster-node-timeout 5000
appendonly yes
redis节点slave3(redis-slave3.conf)
port 7381
cluster-enabled yes
cluster-config-file nodes.conf
cluster-node-timeout 5000
appendonly yes
让我们启动所有三个从属实例,然后启动cluster meet命令,这样每个节点都将加入正在运行的redis集群。
redis-server redis-slave1.conf
redis-server redis-slave2.conf
redis-server redis-slave3.conf
由于集群会议需要IP地址,我们的slave1的IP地址是192.168.4.105,slave2的IP地址是192.168.5.105,slave3的IP地址是192.168.6.105。
redis-cli -h master1 -p 6379 CLUSTER MEET 192.168.4.105 7379
redis-cli -h master1 -p 6379 CLUSTER MEET 192.168.5.105 7380
redis-cli -h master1 -p 6379 CLUSTER MEET 192.168.6.105 7381
和往常一样,使用cluster nodes命令,我们可以看到redis集群中的当前节点(总共6个)。输出将所有节点显示为主节点。

要配置备份,应通过提供主节点ID(名称),在每个redis slave上执行新的cluster replicate命令。下表汇总了备份所需的所有部分(通过查询cluster nodes命令输出的结果)。
| Master Host |
master1 |
| Master Node ID |
3508ffe11ba5fbfbb93db5b21a413799272f5d0f |
| Slave Node |
slave1 |
| redis-cli -h slave1 -p 7379 CLUSTER REPLICATE 3508ffe11ba5fbfbb93db5b21a413799272f5d0f |
|
| Master Host |
master2 |
| Master Node ID |
610976e1ca5382b96718cd7e261d3543e6a99af4 |
| Slave Node |
slave2 |
| redis-cli -h slave2 -p 7380 CLUSTER REPLICATE 610976e1ca5382b96718cd7e261d3543e6a99af4 |
|
| Master Host |
master3 |
| Master Node ID |
d8a2ae6221624212b76d9cf6c1483452e3c26117 |
| Slave Node |
slave3 |
| redis-cli -h slave3 -p 7381 CLUSTER REPLICATE d8a2ae6221624212b76d9cf6c1483452e3c26117 |
|
此时,我们的redis集群配置正确,具有我们打算创建的拓扑结构。cluster nodes命令显示连接到主服务器的所有从服务器。

如我们所见,所有节点都是健康的、连接的,并且分配了正确的角色(主节点和从节点)。
7.3验证Redis群集是否正常工作
和往常一样,对于redis,确保redis集群按预期工作的最好方法是使用redis cli发出一些命令。请注意,由于集群中的节点不代理命令,而是重定向客户机(请参见请分片(分区)方案),因此客户机必须支持这样的协议,这也是Redis CLI应使用-c命令行选项(支持集群)运行的原因:
redis-cli -h master1 -p 6379 -c
让我们尝试设置存储的键(使用set命令),然后查询它们(使用get命令)。因为我们在三个节点之间分布了散列槽,所以密钥也将分布在所有这些节点上。名为some key的第一个键存储在master1节点上,我们连接到该节点。

但是,如果我们尝试用SomeOtherKey的名称存储该Key,有趣的事情就会发生:redis cli告诉我们,该值将存储在IP地址为192.168.3.105(master3)的节点上,该节点包含该Key所属的哈希槽。

请注意,在命令执行之后,redis cli将自动重定向到节点192.168.3.105(master3)。一旦我们在集群节点192.168.3.105(master3)上,我们就可以通过发出cluster getkeysinslot命令来验证hash slot是否真的包含了这个密钥——aomeAnotherKey。
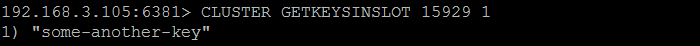
我们还可以验证redis slave节点slave3是否已从主节点(master3)备份了另一个密钥并返回其值。
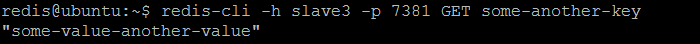
7.4向正在运行的redis集群添加和删除节点
我们已经在分片(分区)方案中提到,redis集群可以在不停机的情况下重新配置,通常涉及散列槽迁移。让我们将另一个主节点master4(IP地址为192.168.7.105)添加到集群中,并将插槽15929从节点master3迁移到master4(它是包含Key的哈希插槽,someAnotherKey)。她是redis node master4(redis-master4.conf)配置:
port 6384
cluster-enabled yes
cluster-config-file nodes.conf
cluster-node-timeout 5000
appendonly yes
redis-server redis-master4.conf
redis-cli -h master1 -p 6379 CLUSTER MEET 192.168.7.105 6384

迁移散列槽过程包括以下阶段:
- 在拥有特定哈希槽(master3)的集群节点上,应执行命令cluster setslot slot migrating,其中是新节点master4(即d8095be33a2b9d06affcb5583f7150b341f4c96)的节点ID。
redis-cli -h master3 -p 6381 CLUSTER SETSLOT 15929 MIGRATING
d8095be33a2b9d06affcb5583f7150b1341f4c96
当一个槽被标记为迁移时,节点将接受关于这个哈希槽的所有查询请求,但仅当给定的键存在时,否则查询将转发到作为迁移目标的节点。
- 在应该成为特定哈希槽(master4)新所有者的集群节点上,命令cluster setslot slot importing,其中是当前所有者master3(即d8a2ae622216212b76d9cf6c1483452e3c26117)的节点ID。
redis-cli -h master4 -p 6384 CLUSTER SETSLOT 15929 IMPORTING d8a2ae6221624212b76d9cf6c1483452e3c26117
- 此时,应使用migrate命令(请参阅http://redis.io/commands/migrate)将哈希槽中的所有密钥从当前所有者master3迁移到新所有者master4。因为我们只有一把钥匙,所以很容易。
redis-cli -h master3 -p 6381 MIGRATE master4 6384 some-another-key 0 0
- 最后,当散列槽变为空(可以通过发出cluster getkeysinslot命令来验证)时,可以将其分配给新节点(master4)。
redis-cli -h master3 -p 6381 CLUSTER SETSLOT 15929 NODE d8095be33a2b9d06affcb5583f7150b1341f4c96
虽然了解细节是非常有用的,但是手动执行这样的过程是困难的,而且容易出错。但是redis cluster包提供了一个名为redis trib的便利实用程序,位于redis分发的src文件夹中。它是用Ruby编写的,通过简化redis集群的管理可能会非常有用(有关详细信息,请参阅http://redis.io/topics/cluster-tutorial)。
8.redis 集群命令
redis cluster添加了一组专门用于集群管理、监视和配置的额外命令。这些命令在本教程的第2部分redis命令中没有介绍,因为它们在稳定版本中还不可用。此外,Redis网站上没有足够的文档,但至少我们可以简要描述每个命令(其中许多命令您已经在实际操作中看到)。
| Command |
CLUSTER SETSLOT slot NODE <node-id> |
| Description |
将哈希槽分配给节点。该命令应在拥有此哈希槽的节点上发出,哈希槽不应包含任何键(应为空)。 |
| Command |
CLUSTER SETSLOT slot IMPORTING <node-id> |
| Description |
将哈希槽标记为从<node id>导入。<node id>应该是这个哈希槽的所有者。 |
| Command |
CLUSTER SETSLOT slot MIGRATING <node-id> |
| Description |
将哈希槽标记为迁移到<node id>。应在拥有此哈希槽的节点上发出该命令。 |
| Command |
CLUSTER NODES |
| Description |
显示Redis群集中的当前节点集。 |
| Command |
CLUSTER ADDSLOTS slot1 [slot2] … [slotN] |
| Description |
将哈希槽分配给redis节点。 |
| Command |
CLUSTER DELSLOTS slot1 [slot2] … [slotN] |
| Description |
从redis节点删除哈希槽分配。 |
| Command |
CLUSTER MEET ip port |
| Description |
将节点添加到Redis群集。 |
| Command |
CLUSTER FORGET <node-id> |
| Description |
从Redis群集中删除节点。 |
| Command |
CLUSTER REPLICATE <master-node-id> |
| Description |
使此节点成为master node<master node id>的副本。 |
| Command |
CLUSTER GETKEYSINSLOT slot count |
| Description |
返回任何特定哈希槽中的键名,这些哈希槽将输出限制为计数键数。如果执行此命令的节点不是槽的所有者,则该命令不会返回任何结果。 |
9.Redis哨兵
Redis的另一个伟大但仍处于实验阶段的特性是Redis Sentinel。它是一个旨在帮助管理实时Redis实例的系统,考虑到以下目标:
- 监控:Sentinel会不断检查主实例和从实例是否按预期工作。
- 通知:如果某个受监控的Redis实例出现问题,Sentinel可以发出通知。
- 自动故障转移:如果某个主节点没有按预期工作,则sentinel可以启动一个故障转移过程,其中一个从节点升级为master。
redis sentinel是一个非常有前途的功能,但它目前正在redis源代码的不稳定分支中开发。它还不是Redis发行版的一部分。
有关详细信息,请访问http://redis.io/topics/sentinel。
六:与应用系统集成
// TODO: throw new BusinessException("困死了!")
