RNN生成文本
RNN生成文本的步骤
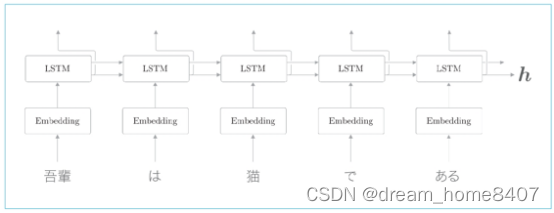
我们使用LSTM层实现了语言模型,这个语言模型的网络结构如下:

现在我们说明一下语言模型生成文本的顺序,这里仍以you say goodbye and i say hello 这一语料库上学习,考虑将单词i 赋给这个语言模型的情况
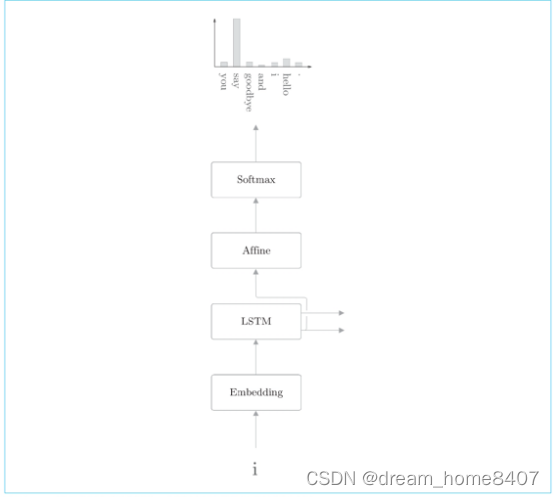
语言模型输出下一个单词的概率分布
语言模型输出下一个出现的单词的概率分布
语言模型输出了当给定单词i时下一个出现单词的概率分布,那么它是如何生成下一个新单词?
一种可能的方法是先择概率最高的单词,这种情况下,因为选择是概率最高的单词,所以这一结果 能唯一确定,这就是说这是一种确定性的方法,另一种概率性地进行选择,这种概率高的单词容易被选到,概率低的单词难以被选到,这种情况下,被选到的单词每一次都不一样,
我们想让每次生成的文本有所不同,这样以来,生成文本富有变化会更有趣,因此,我们通过后一种方法来选择但系,回到我们的例子中,概率性的选择单词say
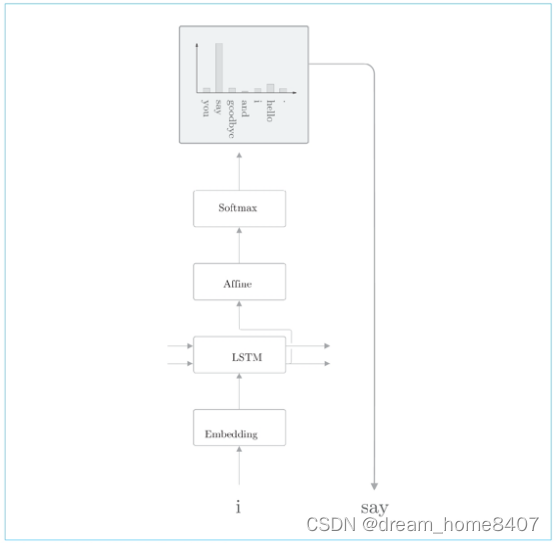
根据概率分布进行采样后结果为say的例子,say的概率最高,所以它被采样到的概率也是最高,不过请注意,这里选到say并不是必然的,而是概率性的,因此,say以外的其他单词根据出现的概率也可能被采样
确定性的是指算法结果是唯一确定的,是可预测的,假设选择概率最高的单词,那么这就是以后一种确定性的算法,而是概率性的算法则概率性确定解雇,因此每次实验时选择的单词都是有变化的,
接下来,采样第二个单词,这只需要重复一下刚才的操作,也就是说,将生成单词say输入语言模型,获得单词的概率分布,然后再根据这个概率分布采样下一个出现的单词,
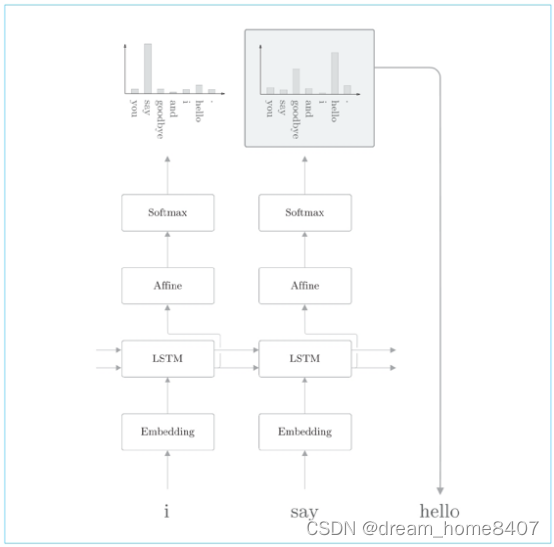
之后根据需要重复此过程即可,知道出现这一个结尾记号,这样一来,我们就可以生成新的文本
seq2seq的原理
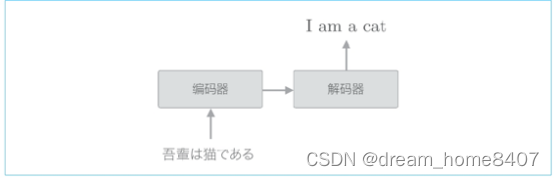
Seq2seq模型也成为Encoder-Decoder模型,顾名思义,这个模型有两个模块,Encoder(编码器)和Decoder(解码器),编码器对输入数据进行编码,解码器对被编码的数据进行解析,编码是基于既定规则的信息转换过程,以字符为例,将字符”A”转换为“1000001”(二进制)就是一个编码的例子,而解码则将被编码的信息还原到它的原始形态,这相当于将位模式的100001转换为字符A
现在我们举一个例子来说明seq2seq的机制,这里考虑将日语翻译成英语,比如“吾輩は猫である”1 翻译为“I am a cat”,seq2seq基于编码器和解码器进行时序数据的转换,
编码器首先对日语这话进行编码,然后将编码好的信息传递给解码器,由解码器生成目标文件, 将一个时序数据转换为另一个时序数据,另外,在这些编码器和解码器内部可以使用RNN,下面我们来看一下细节,首先看编码器
编码器利用RNN将时序数据转换为隐藏状态h,这里RNN使用的是LSTM,也可以使用简单的RNN,另外,这里考虑的是将日语句子分割为单词输入的情况,
编码器输出的向量h是LSTM层的最后一个隐藏状态,其中编码了翻译输入文本所需的信息,这里的重点是,LSTM隐藏状态h是一个固定长度的向量,说到底,编码就是将任意长度的文本转换为一个固定长度的向量。
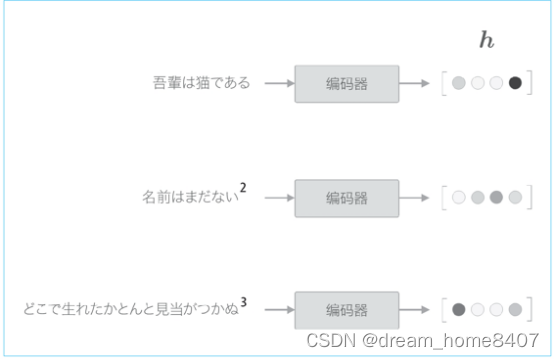
编码器将文本编码为固定长度向量
如图,编码器将文本转换为固定长度的向量,那么解码器如何处理这个编码好的向量,从而生成文本呢,我们可以使用上一节讨论的进行文本生成的模型即可
解码器
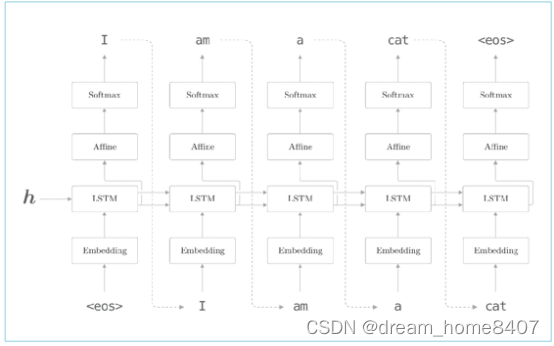
解码器的结构和编码器的神经网络完全相同,不过它和上一届的模型存在一点差异,就是LSTM接收向量h,编码器LSTM层不接受任何信息,这个唯一的,微笑的改变使得普通的语言模型进化可以驾驭翻译的编辑器.
Seq2seq由两个LSTM层组成,即编码器的LSTM和解码器的LSTM,此时LSTM隐藏状态是编码器和解码器的桥梁,在正向传播时,编码器的编码信息通过LSTM层隐藏状态传递给解码器,在反向传播时候,解码器的梯度通过这个桥梁传给编码器。
时序转换
我们将加法视为一个时序转换问题,在我们看来加法运算是一个非常简单的问题,但是seq2seq对加法的逻辑一无所知,我们将加法视为字符,不同的加法问题及其回答的字符数是不同的,如此,在加法问题中,每个样本在时间方向的大小不同,也就是说加法问题,每个样本在时间方向上的大小不同,也就是说加法问题处理的是可变长度的时序数据,因此,在神经网络中,mini-bath处理时,需要想一些应对的办法,
在使用批数据进行学习时,会一起处理多个样本,此时我们的实现中需要保证一个批次内各个样本的数据形状是一致的,
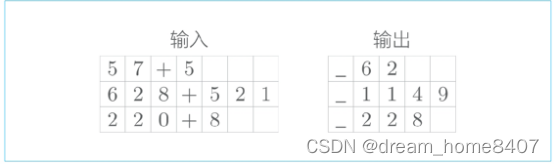
在基于mini-bath学习可变长度的时序数据时,最简单的方法是使用填充(padding),所谓填充,就是用无效数据填充原始数据,从而是数据长度对齐,就是上面这个加法的例子来说,在多余位置插入无效字符,从而使输入数据长度对齐,
为了进行mini-bath学习,使用空白字符进行填充
本次问题处理的是0~999的两个数的加法,因此,包括+在内输入数字的最大字符是7位,另外加法结果最大也是4个字符,因此,对监督数据进行类似的填充,从而对齐多有样本数据,在输出的开始处加上分隔符‘_’,使得输出数据的字符统一为5,这个分隔符作为通知解码器开始生成文本的信号使用
seq2seq的实现
Seq2seq是组合了两个RNN的神经网络,这里我们西安将这两个RNN实现为Encoder和Decoder类,然后将这两个类组合起来,实现seq2seq类,我们先从Encoder类开始介绍
Encoder类
Encoder类接收字符串,将其转化为向量h
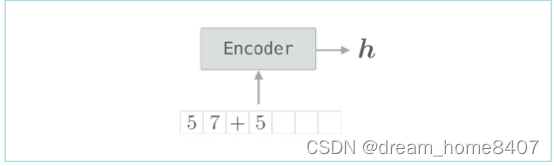
Encoder类的输入输出
我们使用Rnn实现编码器,这里使用LSTM层实现层的结构
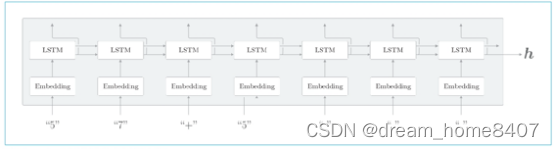
Encoder类由Embedding层和LSTM层组成,Embedding层将字符(字符ID)转化为字符向量,然后将字符向量输入LSTM层,
LSTM层向右时间方向上输出隐藏状态和记忆单元,向上输出隐藏状态,这里的上方不存在,所以丢弃LSTM层向上输出,在编码器处理完最后一个字符后,输出LSTM层隐藏状态h,然后隐藏状态h被传递给解码器,
编码器只将LSTM的隐藏状态传递给解码器,尽管也可以把LSTM的记忆单元传递给解码器,但我们通常不会把LSTM记忆单元传递给其他层,这是因为,LSTM的记忆单元被设计只给自身使用
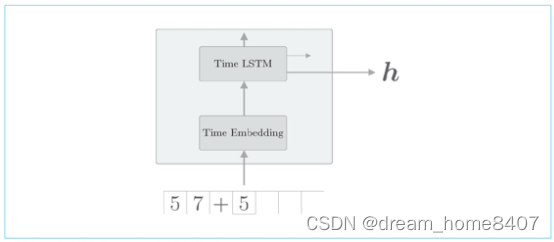
代码实现Endocer类,如下所示,
先看初始化层
class Encoder:
def __init__(self, vocab_size, wordvec_size,hidden_size):
V, D, H = vocab_size, wordvec_size, hidden_size
rn = np.random.randn
embed_W = (rn(V, D) / 100).astype('f')
lstm_Wx = (rn(D, 4 * H) /
np.sqrt(D)).astype('f')
lstm_Wh = (rn(H, 4 * H) /
np.sqrt(H)).astype('f')
lstm_b = np.zeros(4 * H).astype('f')
self.embed = TimeEmbedding(embed_W)
self.lstm = TimeLSTM(lstm_Wx, lstm_Wh, lstm_b,
stateful=False)
self.params = self.embed.params +
self.lstm.params
self.grads = self.embed.grads + self.lstm.grads
self.hs = None
初始化方法接收 vocab_size、wordvec_size 和 hidden_size,这3个参数,voc_size是词汇量,相当于字符的种类,比如数字加法运算,我们使用的而是13个字符,(数字 0 ~ 9、“+”、“”( 空白字符 )、“_”),此外wordvec_size对应于字符向量的维数,hidden_size对应于LSTM层隐藏状态的维数,
这个初始化方法进行权重参数的初始化层的生成,最后,将权重参数和梯度分别归纳到变量成员params和grads的列表中,因为这次并不保持LSTM层状态,所以设定stateful=false
def forward(self, xs):
xs = self.embed.forward(xs)
hs = self.lstm.forward(xs)
self.hs = hs
return hs[:, -1, :]
def backward(self, dh):
dhs = np.zeros_like(self.hs)
dhs[:, -1, :] = dh
dout = self.lstm.backward(dhs)
dout = self.embed.backward(dout)
return dout
编码器的正向调用Embedding层和LSTM层的forward()方法,然后出去LSTM层的最后一个时刻的隐藏状态,将它作为编码器
在编码器的反向传播中,LSTM层的最后一个隐藏状态是dh
,这个dh是从解码器传来的梯度,在反向传播实现中,先生成元素为0的张量dhs,再将dh存放在这个dhs中对应的位置上,剩下的就是调用embedding层和lstm层,以上就是encoder类的实现
Decoder类
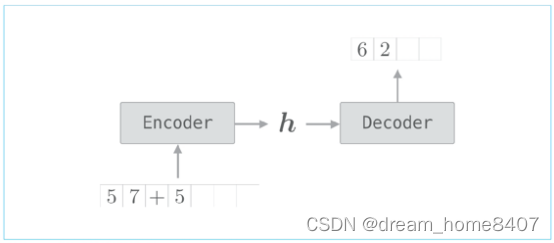
Decoder类接收Encoder类的实现,Decoder类接收Encoder类输出的h,输出目标字符串,
解码器也可以基于RNN实现,
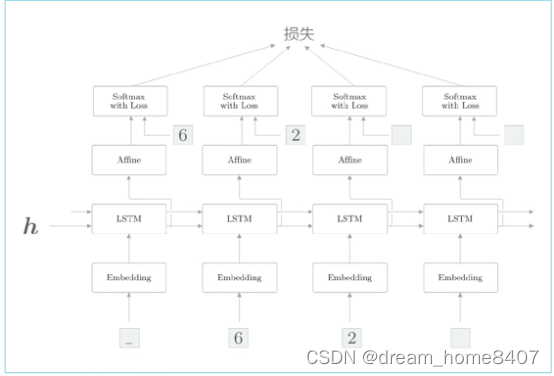
解码器的层结构(学习时)
了解解码器在学习时层的结构,使用了监督数据_62进行学习,此时输入的 数据是[‘_’,’6’,’2’,’ ‘],对应输出是[‘6’,’2’,’ ’,’ ’]
在使用RNN进行文本生成时,学习时和生成时的数据输入方法不同,在学习时,已经知道正确解,所以可以整体地输入时序方向上的数据,相对应,在推理时生成新的字符串,则只能输入第一个通知开始的分隔符,这样将采样1个字符,并将采样出来的字符作为下一个输入,如此重复该过程,
进行文本生成时候,我们基于softmax函数的概率进行采样,因此生成的文本会随机波动,没因为这次的问题是加法,所以我们想消除这种概率性的波动,生成确定性的答案,为此,这次我们仅选择得分最高的字符,也就是说,是确定性的选择,而不是概率性的选择,
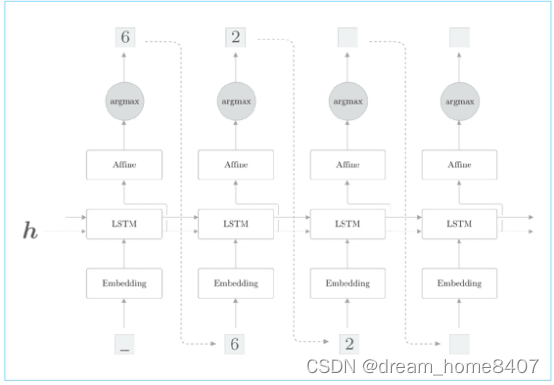
解码器生成字符串的步骤,通过argmax节点从Affine层输出中选择最大的索引
这里出现了新的argmax节点,这里获取最大值的索引(本例中是字符ID),和上一节欸展示的文本生成时结构不同,不过这次没有使用softmax层,而是Affine层输出的得分中最大值的字符ID
Softmax层对输入的向量进行正则化,此时,向量元素的值虽然被改变,但是它们的大小关系没有变化,
在解码器中,学习时和生成处理softmax层的处理方式是不一样的,因此,softmax with loss
层交给此后实现的seq2seq类处理,Decoder类仅承担损失函数层之前的操作
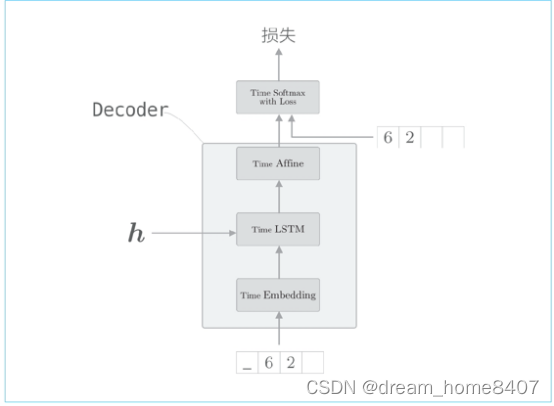
Decoder类由Embedding 和LSTM层实现,
class Decoder:
def __init__(self, vocab_size, wordvec_size,
hidden_size):
V, D, H = vocab_size, wordvec_size, hidden_size
rn = np.random.randn
embed_W = (rn(V, D) / 100).astype('f')
lstm_Wx = (rn(D, 4 * H) /
np.sqrt(D)).astype('f')
lstm_Wh = (rn(H, 4 * H) /
np.sqrt(H)).astype('f')
lstm_b = np.zeros(4 * H).astype('f')
affine_W = (rn(H, V) / np.sqrt(H)).astype('f')
affine_b = np.zeros(V).astype('f')
self.embed = TimeEmbedding(embed_W)
self.lstm = TimeLSTM(lstm_Wx, lstm_Wh, lstm_b,
stateful=True)
self.affine = TimeAffine(affine_W, affine_b)
self.params, self.grads = [], []
for layer in (self.embed, self.lstm,self.affine):
self.params += layer.params
self.grads += layer.grads
def forward(self, xs, h):
self.lstm.set_state(h)
out = self.embed.forward(xs)
out = self.lstm.forward(out)
score = self.affine.forward(out)
return score
def backward(self, dscore):
dout = self.affine.backward(dscore)
dout = self.lstm.backward(dout)
dout = self.embed.backward(dout)
dh = self.lstm.dh
return dh
这里仅对反向传播进行一些补充,在backward()的实现中,从上方的softmax with loss 层接收梯度dscore,然后按affine层,lstm层和embedding层顺序传播梯度,lstm层将时间方向的梯度保存在lstm层的成员变量dh中,因此去除时间方向上的梯度dh
,将其作为为decoder类backward的输出
def generate(self, h, start_id, sample_size):
sampled = []
sample_id = start_id
self.lstm.set_state(h)
for _ in range(sample_size):
x = np.array(sample_id).reshape((1, 1))
out = self.embed.forward(x)
out = self.lstm.forward(out)
score = self.affine.forward(out)
sample_id = np.argmax(score.flatten())
sampled.append(int(sample_id))
return sampled
这个generate()方法有三个参数,分别是从编码器接收的隐藏状态h,最开始输入的字符IDstart_id和生成的字符数量 sample_size,这里重复如下操作,输入一个字符,选择affine层输出的最大值的字符ID,这就是decoder类实现,
自动图像描述
自动图像描述将图像转换为文本,这里也可以在seq2seq的框架下解决
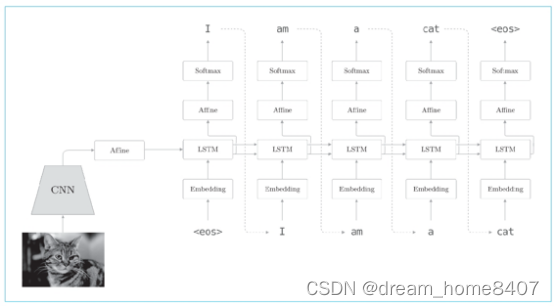
上图是将我们熟悉的网络结构中编码器从LSTM换成了CNN,而解码器任然使用与之前相同的网络,仅通过这点改变,seq2seq就可以处理图像了,
这里补充说明,CNN对图像进行编码,这时CNN的最终输出是特征图,因为特征图(宽,高,通道)是三维的,所以需要想办法让编码器的lstm可以处理它,于是,我们将CNN的特征图扁平化到一维,并基于全连接层进行转换,之后,再将转化按钮后的数据传递给解码器,就可以像之间一样生成文本了,
总结
1.基于RNN的语言模型可以生成新的文本
2再进行文本生成时,重复输入一个单词,基于模型的输出概率分布进行采样这一过程,
通过组合两个RNN,可以将一个时序数据转换为另一个时序数据(seq2seq)
3.在seq2seq中,编码器对输入语句进行编码,解码器接收并解码这个编码信息,获得目标输出语句
4.Seq2seq可以用在机器翻译,聊天机器人和自动图像描述等各种生成式的应用中,