C++基础语法知识点
可执行文件产生的步骤
源文件 —> 预处理 —> 编译 —>优化 —> 汇编 —>链接 —>可执行文件
- 预处理:
将源文件中的伪指令(以#开头)代理处理,比如宏定义替换、条件编译指令等 - 编译:
将代码编译成汇编代码 - 优化:
将汇编代码进行优化,主要是提高代码执行效率、减少内存访问次数,对代码进行优化 - 汇编:
将汇编代码翻译成机器可识别的机器代码 - 链接
代码中使用到了外部的库或者函数,链接程序需要用到的依赖文件,最后生成可执行文件
基础数据类型字节
| C++数据类型 | 字节数 |
|---|---|
| char | 1 |
| short | 2 |
| int | 4 |
| float | 4 |
| long | 8 |
| double | 8 |
| long double | 16 |
| java数据类型 | 字节数 |
|---|---|
| boolean | 1 |
| byte | 1 |
| char | 2 |
| short | 2 |
| int | 4 |
| float | 4 |
| long | 8 |
| double | 8 |
指针和引用
定义
指针,是一种变量,占用内存,存放的是地址,地址指向另一个变量
引用,俗称变量的别名,可以当做变量本身自己一样使用,变量传递时不会发生值拷贝,C++底层汇编引用的实现原理和指针一样,也会分配内存
区别
二者底层实现原理一样,都会分配内存,存放变量的地址,只是在使用上引用多了许多限制,如下:
- 引用声明时必须为其赋值,指明引用的对象,而且后期不允许修改引用
- 引用对象的生命周期和原对象生命周期一样,所以尽可能不要将引用绑定到一个局部对象上去
- 任何对引用的运算加减实质都是操作到原对象上去
指针则没有上面的诸多限制,指向可以随意指定,也可以为NULL,并且可以有二级、三级指针等,那么 为什么还需要由引用这种东西?
解决指针满天飞的情况,代码的优雅性和便利性,而且引用初始化必须绑定,保证了引用的安全性。
以下是我对引用底层实现原理的分析,得出的引用也会分配内存的结论
以下是我的分析,源代码:
#include <stdio.h>
int main(){
int a = 2;
int *p = &a;
int c = 4;
int &b = c;
printf("pointer %d hand %d \n", *p, b);
return 0;
}
汇编,分析过程在汇编的注释当中
objdump -S file.cpp得到汇编文件file.s,如下:
.section __TEXT,__text,regular,pure_instructions
.macosx_version_min 10, 13
.globl _main
.p2align 4, 0x90
_main: ## @main
.cfi_startproc
## BB#0:
pushq %rbp
Lcfi0:
.cfi_def_cfa_offset 16
Lcfi1:
.cfi_offset %rbp, -16
movq %rsp, %rbp //rsp是栈顶指针,不参与栈内指针偏移计算,rbp是栈帧指针,要参与偏移计算
Lcfi2:
.cfi_def_cfa_register %rbp
subq $48, %rsp //栈底到栈顶是地址递增的,所以这里用到栈内48个字节,做减法
leaq L_.str(%rip), %rdi
movl $4, %eax
movl %eax, %ecx
leaq -20(%rbp), %rdx //lea加载rbp-20这个偏移地址,把这个地址读取到rdx中
leaq -8(%rbp), %rsi //同上,rdx和rsi是32位寄存器
movl $0, -4(%rbp)
movl $2, -8(%rbp) //将立即数2写入栈的rbp-8这个地方去,也就是rbp-5 6 7 8这4个字节
movq %rsi, -16(%rbp) //把rsi的内容移动到rbp-16这个地方,rsi保存的就是-8的地址,也就是源码中的p指针
movl $4, -20(%rbp) //-20处赋值4,也就是c变量
movq %rdx, -32(%rbp) //同理,把rdx移动到-32位置去,rdx保存了-20的地址,说明-32是b引用,也就是引用也占用内存
movq -16(%rbp), %rdx
movl (%rdx), %esi
movq -32(%rbp), %rdx
movl (%rdx), %edx
movb $0, %al
callq _printf
xorl %edx, %edx
movl %eax, -36(%rbp) ## 4-byte Spill
movl %edx, %eax
addq $48, %rsp
popq %rbp
retq
.cfi_endproc
.section __TEXT,__cstring,cstring_literals
L_.str: ## @.str
.asciz "pointer %d hand %d sizeofint %d\n"
.subsections_via_symbols
C语言宏定义特性
__builtin_clz
__builtin_clz(4) = 28
返回高位开始到低位连续0的个数,特殊情况当传值为0和1时,返回都是31
#define __func__ __PRETTY_FUNCTION__
返回当前函数的的函数名
C++类大小计算
空类的大小为1,为什么了?
因为C++里面每个类都可以实例化,空类也可以,都会为其分配一个地址,所以编译器默认为空类分配一个字节
虚函数和纯虚函数
虚函数子类可以(也可以不)重新定义,纯虚函数子类必须重新定义;拥有寻函数的类会生成一个虚函数表,同时类里面也会多一个指针指向这个虚函数表
虚函数是C++多态的关键,在运行时根据实际运行类去调用他的方法

关于虚函数继承问题:
例子一:子类和父类同时拥有自己的虚函数,不存在这重写父类虚函数情况
内存结构将会是这样,子类父类同一个虚函数表,父类的虚函数在子类前面

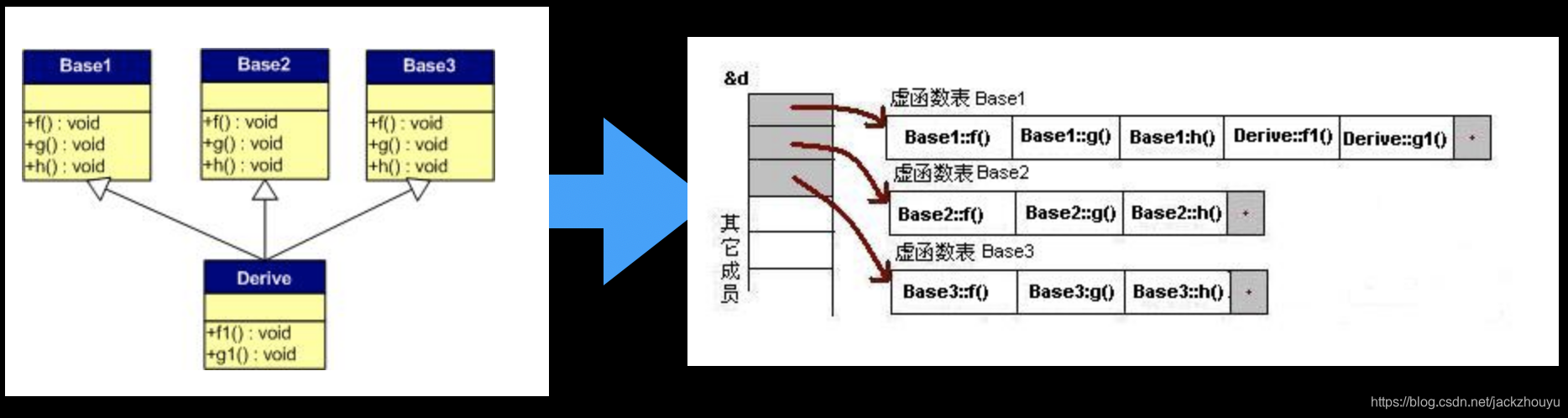
多继承问题:
继承多个类,多个父类有自己的虚函数,子类也有,不重写父类方法:
多了2个指针,一共三个
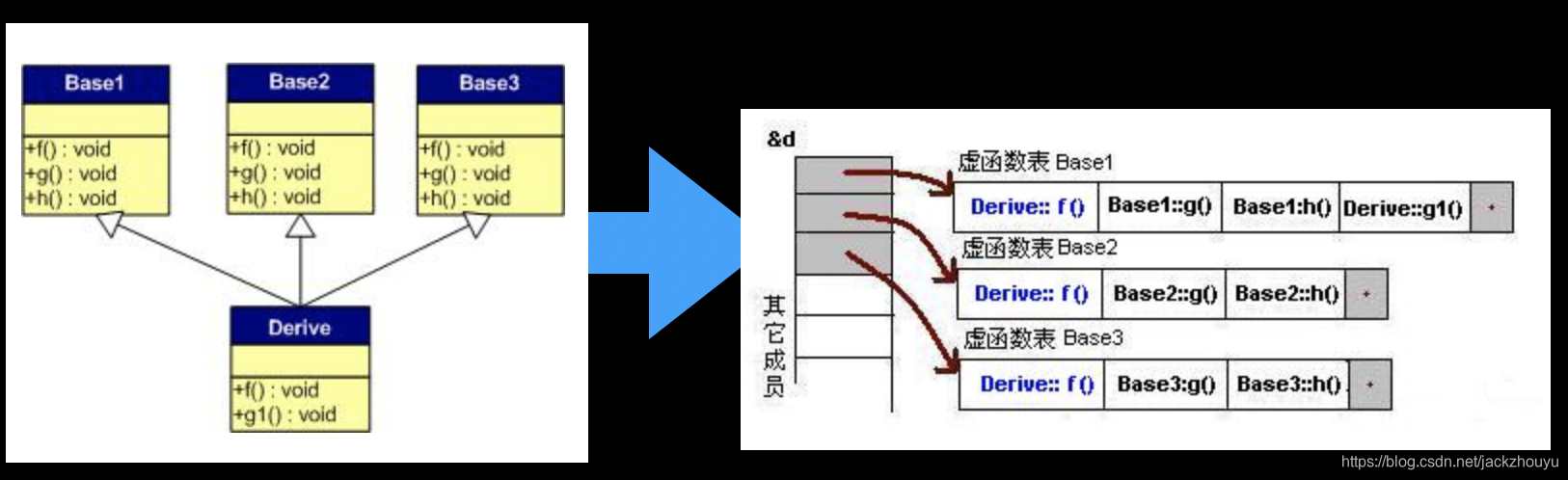
继承时有覆盖父类虚函数:
类大小同上,但是会覆盖父类的虚函数表中的对应的方法
虚继承 class A : public virtual B
当Test多继承A和B时,而A和B同时继承C这样在Test中会同时存在两份C中的函数,为了节省空间,使用虚继承,会保证只存在一份拷贝,而且还会多一个虚类指针;由于虚继承主要解决多继承中的问题,离开了多继承也就无法适用了
auto关键字
auto关键字主要有以下两个方面作用
- 声明变量时根据变量初值或者表达式为变量分配一个类型
- 声明函数时,作为占位符
所以,声明变量时必须有明确的初始化;
auto a = 9; //int类型
但是不建议如上操作,代码应尽可能描述准确,而不是阅读性更复杂;所以auto可以使用在如std::vector<>这种复杂类型时,起到优化作用
const不变关键字
可以修饰变量和函数,保持状态不变稳定
修饰变量
cosnt int a = 1; //a不能修改
实际可以通过指针再次对其修改,并不能保证其不能被修改
修饰指针:
const int * a = 1; // int*不变,也就是指向的变量值无法修改,指针却可以被修改
int * const a; //指针不能被修改,但指向的值可以被修改
修饰函数
如以下代码:
void fun() const;
fun函数内不能修改类的成员变量,且不能调用非const函数,因为非const函数有可能修改数据成员
multable 易变 关键字
与const相反,修饰的变量是易变,不稳定状态
使用场景:
const修饰函数内部,如果需要对某个成员修改,对这个成员赋mutlable属性即可
mutlable不能修改const和static属性的变量
复杂指针强转解释
假如有结构体:
struct A{
class1* c1;
class2* c2;
}
那有 如下操作解释:
A* a = malloc(A);
class1 C = *(class1 **)a;
解释:
第一句: 假设a指针存放了结构体A的地址,A的内存结构体地址:0x123,那a指针放的也是0x123
第二句:首先把a强转成class1的二级指针,此时a无任何变化,只是解释方式变了,0x123是一级class1,指向的结构体变为A内存变为了class1的二级指针,然后对a二级取二级指针解引用,也就是a指向的结构体的第一个指针长度作为C的指针,也就是c1
所以C实质就是c1指针
为什么很多底层库会这样做?现在是否还建议这样做?
现在建议不这么做了,建议使用结构体引用去指定变量,指针操作极易出错,而且从效率上讲,都一样,早期这么做是因为当时的编译器还没有优化,现在优化了两种方式效率一样
为什么空类的实例是1
书上说:每个实例在内存中都有一个独一无二的地址,为了达到这个目的,编译器往往会给一个空类隐含的加一个字节,这样空类在实例化后在内存得到了独一无二的地址。所以大小为1。
我补充:为空类分配对象时(new一个),必须要在内存中占用空间才行,否则无法存在,为其分配一个字节是在最小的标准,所以分配了1个字节
四种cast转换
-
const_cast<type_id> (expression)
用于将const或者voliate属性转换为非const和volatile属性 -
static_cast<type_id> (expression)
此种转换运行时不会检查,所以安全性要开发人员来保证,通常用于
非const转const;void与非void类型转换,子类转基类 -
dynamic_cast<type*>(expression)
通常用于子类与基类之间的指针转换,要求基类必须有虚函数,可以向下向上转换;
如果是指针转换失败,则返回NULL;引用转换失败则会抛出转换异常 -
reinpreter_cast<type_id> (expression)
可以用于指针、引用、算数类型、成员、函数指针等转换,实质是进行二进制拷贝,不做任何类型检查和转换
智能指针
智能指针主要作用,超过了指针的作用域,自动回收分配的内存对象;
如何超过作用域,自动回收呢?
创建的智能指针在栈上,当栈上的指针指针弹出,就自动回收这个智能指针指向的对象;普通的对象指针需要主动去delete
智能指针主要有三种:
- shared_ptr< type >
shared_ptr a(new int);
共享类型的智能指针,其原理是通过引用计算来实现共享,被共享指针引用一次,引用计数就加1,为0时就释放内存;
shared_ptr带来循环引用问题,如何解决?
循环引用:
class A{
share_ptrd<B> ptr_b;
};
class B{
share_ptrd<A> ptr_a;
};
void main(){
shared_ptr<A> a(new A); //A引用计数为1
shared_ptr<B> b(new B); //B引用计数为1
a->ptr_b = b; //B引用计数2
b->ptr_a = a; //A引用计数为2
}
描述:b对象内部成员ptr_a因为与a共同管理A对象的内存,导致b不能够被释放;同理a也因为成员中有ptr_b持有b导致无法释放,内部互相持有对方的引用导致无法释放
引入weak_ptr弱引用智能指针,将内部成员类型改为此类型,当他与其他共享智能指针共同引用时,不影响引用计数器的值,所以就不存在循环引用问题
- unique_ptr
独享的智能指针,不与其他指针共享

为什么析构函数必须是虚函数,而默认的析构函数却不是虚函数?
虚函数是多态的核心,为什么析构函数必须是虚函数,这是为了保证多态时,我们声明的基类的指针,也可以去调用子类的析构函数,从而不会内存泄漏
那为什么默认的却不是呢?因为有虚函数的类都会多出虚函数表和指针,增加内存,如果一个类不会被继承那么可以不为虚函数,所以默认不是
进程
进程是一个程序运行题,拥有自己的地址空间,包括代码区、数据区和堆栈区,进程间相互隔离,一个进程的结束并不影响另一个进程;
C++中进程创建:
pid_t pid = fork();
if(pid < 0){
cout << "error" <<end;
}else if(pid > 0){
cout << "running parent process" << endl;
}else{
cout << "running child process" << endl;
}
fork()函数一次调用,两次返回,
- > 0的返回执行在父进程中
- =0返回执行在子进程中
- <0创建进程出错
因此可以根据返回值,将不同的任务放到不同的进程中
fork创建的子进程,拷贝了父进程的数据区和堆栈区,只有当对他们修改了,才会不同;由于进程间相互隔离,同名之间的通信将采用特殊的方式
进程间通信
- 共享内存,速度最快,直接对内存的操作
- 消息队列,独立于进程间,进程退出消息也不一定删除;并且不能保证先进先出
- 信号量,信号量用于进程间同步,若要在进程间传递数据需要结合共享内存。
- 套接字(Socket),一般的进程间通信机制,可用于不同机器之间的进程间通信
- 管道,命名管道在文件系统中有对应的文件名。命名管道通过命令mkfifo或系统调用mkfifo来创建。实质是通过管道文件来共享数据
线程
C++ 11之前是pthread创建线程,C++11则为thread包;
每个进程至少有一个线程,进程内的线程共享地址空间,同一个进程内的线程可以很方便的进行数据共享和操作,比进程能更好的操作;但是线程之间的数据安全需要程序自己来保证
pthread
- 创建一个线程
int pthread_create(pthread_t *thread, pthread_attr_t const * attr, void *(*start_routine)(void *), void * arg);
thread:传入的线程id指针
attr:设置线程的属性,可以为NULL
start_routine:线程要执行的函数,函数指针
arg:执行函数的入参
基本使用:
void* test(void* a){
int b = *(int *)a;
pthread_exit(NULL); //主动退出线程
}
int main(){
pthread_t pid;
int a= 10;
pthread_create(&pid, NULL, test, (void*)&a);
}
注意: 入参arg时,必须要强转为(void*)指针,在test函数内部在在转换回来;还要注意执行函数的类型及返回值,固定的;如果函数是属于某个类的,则这个函数必须是类的static类型
- 线程的join和detach
int pthread_join(pthread_t thid, void ** ret_val);
当前线程使用此函数后,线程会阻塞住,等待thid执行完成后继续执行
int pthread_detach(pthread_t thid);
当前线程使用此函数后,thid线程自己在后台运行,不影响当前线程的运行
- 互斥
为了保证多线程执行同一段代码时,线程之间不相互干扰,加入互斥量,保证同一段代码同一时间段只有一个线程在运行
pthread_mutex_t mutex;
pthread_mutex_init(&mutex, NULL);
//锁住
pthread_mutex_lock(&mutex);
//运行代码
//退出
pthread_mutex_unlock(&mutex);
//销毁互斥量
pthread_mutex_destroy(&mutex);
- 条件Cond/Wait也可以进行线程同步
pthread_cond_t cond;
pthread_cond_init(&cond, NULL);
//拥有该mutex互斥量的线程,变为阻塞状态并且释放mutex互斥量,其他线程可以去抢
-pthread_cond_wait(&cond, &mutex.mutex);
//等待ts后就不等了,醒了以后注意要重新去抢锁,如果抢不到就退出 不要在执行了
//-pthread_cond_timedwait(&cond, &mutex.mutex, &ts);
//其他线程调用cond的signal后,mutex会被唤醒 重新执行
pthread_cond_signal(&cond);
//唤醒所有的线程
//pthread_cond_broadcast(&cond);
//销毁cond
pthread_cond_destroy(&cond);
C++11 thread
- 创建一个线程
#include <thread>
using namespace std;
void test(int a){}
int main(){
thread t(test, 19);
}
以上创建一个thread类型的变量即完成了线程创建与执行,注意线程参数传递根据执行函数的参数类型与数理挨个传就行; 但是注意,这里的参数传递是值拷贝,就算使用了引用也是值拷贝的,修改不会影响原来的变量
如果不想拷贝的话,就要使用std::ref引用去实现,如下:
class test{}
test t;
void myTest(){
}
thread th(myTest, std::ref(t));
这样就保证了线程中的t和之前的t是一样的了;与pthread不一样的是,thread的执行函数可以是类的普通成员函数,不过需要先创建对象并传入对象
class _tagNode{
public:
void do_some_work(int a);
};
_tagNode node;
thread t(&_tagNode::do_some_work, &node,20);
- 线程的join/detach
与pthread用法一致
thread t(run);
t.join();
t.detach();
- 线程控制器转移
当我们创建一个线程时,可以将线程控制权转移,以后对线程的操作都要在新的权限上去做
thread t1(f1);
thread t3(move(t1));
join、detach都必须使用t3,使用t1会报错
- 锁
与pthread的调用方法传递lock就执行加锁不同;在C++11中锁更灵活更强大;锁机制主要由两大类组成:
互斥量
mutex
std::mutex 基本互斥量
std::recursive_mutex 可递归的互斥量(类似于java的可重入锁)
std::time_mutex 可定时的互斥量
std::recursive_time_mutex 定时可递归互斥量
mutex提供的api
mutex不允许构造,只能声明定义类型,基本使用方法:
std::mutex mtx;
mtx.lock();
//或者
//mtx.try_lock();
mtx.unlock();
lock(): 当前线程尝试将互斥量锁住,锁住后即可继续执行,没有锁住,被其他线程持有,则本线程会阻塞
try_lock(): 尝试去锁住,没有锁住会立即返回false
最后unlock()释放互斥量解锁
注意:std::mutex只能被锁一次,如果本线程已经获取到锁后,想在用mutex去lock,将会造成死锁状态
std::recursive_mutex就可以很好的解决上面的问题(可递归),但是要记住,锁了多少次就要unlock解锁多少次,除此之外,其他基本特效和mutex一样
std::time_mutex
时间互斥量多了两个api:
try_lock_for(): 该函数会传递一个时间,在此时间内,线程会尝试去锁住mutex,如果没有锁住,线程时间内处于阻塞状态;超时后将放回false
try_lock_until:原理同上,只是将等待时间变为时刻
std::recursive_time_mutex
兼顾以上recursive_mutex和time_mutex的特点
锁对象
lock的方式除了以上基本的两种之外,C++11提供了更为便利的上锁函数
std::lock_guard
std::lock_guard<std::mutex> lck (mtx);
在函数中使用,上锁调用lock_guard类型变量,传入mutex,自动上锁,lock_guard作用域外,自动解锁;原理就是 lock_guard的够着函数调用lock上锁,析构函数时unlock解锁
还有一种比上面的更灵活上锁机制:
std::unique_lock
unique_lock除了拥有lock_guard的自动解除锁机制外,还提供了延迟锁定、尝试锁、所有权转移和与条件变量一同使用;
void print_block (int n, char c) {
//unique_lock有多组构造函数, 这里std::defer_lock不设置锁状态
std::unique_lock<std::mutex> my_lock (mtx, std::defer_lock);
//尝试加锁, 如果加锁成功则执行
//(适合定时执行一个job的场景, 一个线程执行就可以, 可以用更新时间戳辅助)
if(my_lock.try_lock()){
for (int i=0; i<n; ++i)
std::cout << c;
std::cout << '\n';
}
}
lock_guard和unique_lock有什么不同? unique_lock比lock_guard强大,几乎lock_guard支持的他都支持,功能也比他多,但是同时在效率上笔lock_guard差一点;选择谁根据需求场景来选择把
4 条件变量同步
std::condition_variable_any 条件变量,需要与lock配合使用,他的基本用法:
std::mutex mtx; // 全局互斥锁.
std::condition_variable cv; // 全局条件变量.
bool ready = false; // 全局标志位.
void do_print_id(int id)
{
std::lock_guard <std::mutex> lck(mtx);
while (!ready) // 如果标志位不为 true, 则等待...
cv.wait(lck); // 当前线程被阻塞, 当全局标志位变为 true 之后,
// 线程被唤醒, 继续往下执行打印线程编号id.
std::cout << "thread " << id << '\n';
}
std::condition_variable_any::wait(std_lock) 当前线程被阻塞,并且锁对象持有的互斥量会同时释放掉;当前的条件变量在其他地方调用notify_all或者notify_one才会唤醒当前线程,自动重新去获取锁在执行
wait_for()
传入一个时间段,释放锁互斥量并且在该时间段内处于阻塞状态;超时后返回(或者被唤醒返回),自动去获取锁后再执行
wait_until()
同上,只是时间方式变了
notify_all/notify_one
唤醒所有或者一个被条件变量调用了wait处于阻塞状态的线程
还有一种std::condition_variable条件变量,这种变量只能与unique_lock配合使用,不能与其他锁一起使用,condition_variable_any可以与所有的锁一块使用
为什么栈的效率比堆高
栈: 主要用于函数调用时局部临时变量存储,地址由高到低的增长,由系统提供的数据结构;并且有一些系统底层的支持
堆:手动申请和释放内存,频繁操作会导致产生很多内存碎片,效率较低
栈由操作系统提供的数据结构,系统提供指令操作,有专门的寄存器保存地址,压栈/出栈都有系统指令;而堆则由C++库函数管理,申请/释放内存,所以比栈的效率低
