1.什么是checkpoint
checkpoint是数据库的一个内部事件,检查点激活时会触发数据库写进程(DBWR),将数据缓冲区里的脏数据块写到数据文件中。
其作用有两个方面:
1)保证数据库的一致性,这是指将脏数据从数据缓冲区写出到硬盘上,从而保证内存和硬盘上的数据是一致的。
2)缩短实例恢复的时间,实例恢复时,要把实例异常关闭前没有写到硬盘的脏数据通过日志进行恢复。如果脏块过多,实例恢复的时间也会过长,检查点的发生可以减少脏块的数量,从而减少实例恢复的时间。
2.检查点分类
①完全检查点 full checkpoint
②增量检查点 incremental checkpoint
③局部检查点 partial checkpoint
2-1.完全检查点工作方式:
记下当前的scn, 将此scn之前所有的脏块一次性写完,再将该scn号同步更新控制文件和数据文件头。
触发完全检查点的四个操作
①正常关闭数据库:shutdown immediate
②手动检查点切换:alter system checkpoint;
③日志切换:alter system switch logfile; ##滞后触发dbwr,先记后写
④数据库热备模式:alter database begin backup;
示例1:
验证以上概念可以做一下alter system checkpoint,然后观察v$datafile和v$datafile_header中scn被更新。
>alter system checkpoint;
>select file#,name,checkpoint_change#,last_change# from v$datafile;
>select file#,name,checkpoint_change#,last_change# from v$datafile_header;
示例2:
研究一下日志切换:alter system switch logfile;
设置FAST_START_MTTR_TARGET<>0,查看v$log视图中的active状态几分钟后会变成inactive状态,说明了什么?确认该操作也更新了控制文件和日志文件头部的SCN。 ##滞后触发
Sys>alter system set FAST_START_MTTR_TARGET=int;
>alter system switch logfile; ##等待5分钟查看v$log视图
>select group#,sequence#,status,archived from v$log;
>select file#,name,checkpoint_change#,last_change# from v$datafile;
2-2.增量检查点:
作用:提高实例恢复的效率
1)被修改过的块,在oracle中都被统称为脏块.脏块按照首次变脏的时间顺序被一个双向链表指针串联起来,这称做检查点队列。
2)当增量检查点发生时,DBWR就会被触发,沿着检查点队列的顺序将部分脏块刷新到磁盘上,每次刷新截止的那个块的位置就叫检查点位置,检查点位置之前的块,都是已经刷新到磁盘上的块。而检查点位置对应的日志地址(RBA)又总是被记录在控制文件中。如果发生系统崩溃,这个最后的检查点位置就是实例恢复运用日志的起点。
3)增量检查点使检查点位置前移。进而缩短实例恢复需要的日志起点和终点之间的距离,触发增量检查点越频繁,实例恢复的时间越短,但数据库性能受到频繁IO影响会降低。
4)增量检查点不会同步更新数据文件头和控制文件的SCN。
在了解学习增量检查点之前,需要重点理解实例恢复
什么是实例恢复?实例恢复的机制是什么?
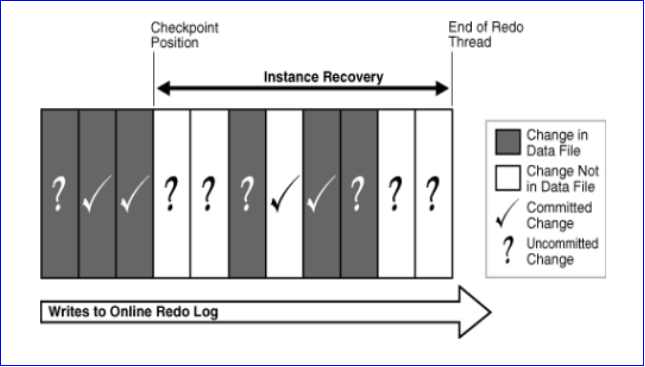
每当增量检查点触发时,一部分dirty buffer被刷新到磁盘,并记录了最后一次检查点位置。当实例恢复时,Oracle首先从控制文件里找到最后一次检查点位置,这个位置其实就是实例恢复时运用日志的起点(RBA)。然后是smon监控下的一系列动作:
1)roll forward ##利用redo,将检查点位置之后的变更,包括commit和uncommit的都前滚出来了,然后统统写到磁盘(datafile)里。
2)open ##用户可以连接进来,访问数据库。
3)roll back ##回滚掉数据文件中未提交的数据
如何理解此图:
背景:当实例崩溃发生时,内存数据丢失,而当时的内存中db buffe和磁盘上的datafile内容不一致。
当发生实例奔溃时,checkpoint记录的scn之前的数据无需关注,已经刷写到datafile中,但是在db buffer cache中,有已经提交的数据和为提交的数据和已经刷写到dbfile中的数据。
我们的重点是噶按住已经提交的数据但是还未刷写到dbfile中的数据。通过FAST_START_MTTR_TARGET这个参数的设置时间,我们可以倒推出FAST_START_MTTR_TARGET参数规定时间内增量检查点需要刷写的
日志数量。当重新启动数据库时,数据库可以快速完成实例恢复。
要解决两个问题:
①重新构成崩溃时内存中还没有保存到磁盘的已commit的变更块。
②回滚掉已被写至数据文件的uncommit的变更块。
实例恢复有关的顾问
使能实例恢复顾问(MTTR Advisory)。需要设置两个参数 ##show parameter mttr;
1)STATISTICS_LEVEL 置为typical(缺省) 或者all
2)FAST_START_MTTR_TARGET 置为非零值
FAST_START_MTTR_TARGET参数
SYS@ prod>show parameter mttr;
NAME TYPE VALUE
------------------------------------ ----------- ------------------------------
fast_start_mttr_target integer 0
此参数单位为秒,缺省值0,范围0-3600秒,根据这个参数,Oracle计算出在内存中累积的dirty buffer所需的日志恢复时间,如果日志累计到达一定量,则增量检查点进程被触发。该参数如果为0,ORACLE则会根据DBWN进程自身需要尽量减少写入量,这样虽然实现了性能最大化,但实例恢复时间可能会比较长。
设置fast_start_mttr_target参数
sys>alter system set fast_start_mttr_target=int;
为了合理的设置MTTR参数,可以参考视图 v$instance_recovery的估算值
SQL>select recovery_estimated_ios,actual_redo_blks,target_redo_blks,target_mttr,estimated_mttr from v$instance_recovery;
RECOVERY_ESTIMATED_IOS ACTUAL_REDO_BLKS TARGET_REDO_BLKS TARGET_MTTR ESTIMATED_MTTR
------------------------------------------ -------------------------------- -------------------------------- ---------------------- ---------------------------
29 94 2267 0 12
最后:通过设置FAST_START_MTTR_TARGET参数的时间,通过重新启动数据库,观察数据库启动时间是否接近 ESTIMATED_MTTR参数时间
2-3.部分检查点:(局部检查点)
对于仅限于局部影响的操作,可以触发局部检查点。##表空间设置为只读或者offine,不会产生脏buffer,故而
比如:表空间offline,数据文件offline,删除extent,表truncate,begin backup(将表空间置于备份模式)等。