XML
1.XML(extensible markup language ):可扩展标记语言。
2.XML特点是,标签可以由用户自己随意扩展。比如,html中标签如何写,属性如何写,属性值如何写,都是有规范的(w3c规定的)。但是在xml文件中,标签没有规范,可以随意扩展。
3.XML文件有两个作用:
(1)做其它技术的配置文件:
<config>
<nav>
<color>red</color>
<size>5</size>
</nav>
<body>
<color>red</color>
<size>5</size>
</body>
<foot>
<color>red</color>
<color>blue</color>
<color>green</color>
<size>5</size>
</ foot >
</config>(2)在不同语言环境下交换数据:
中国人–>中国话–>人–>韩语—>韩国人
中国人–>中国话–>人–>日语—>日本人
XXX国人—>英语—>YYY国人
这就有一个要求,所有国家的人,都要学习英语。
Java程序–>java结果 –> 人—>C参数–> C语言
Java程序–>java结果 –> 人—>php参数–> php程序
Java程序–>java结果 –> 人—>asp参数–>asp程序
C程序–>C结果–>人–>php参数–>php程序
XXX程序–> xml –>YYY程序
这就有一个要求,所有的编程语言都要支持xml。
a)支持向xml中写数据
b)支持从xml中读取数据
解析XML文件
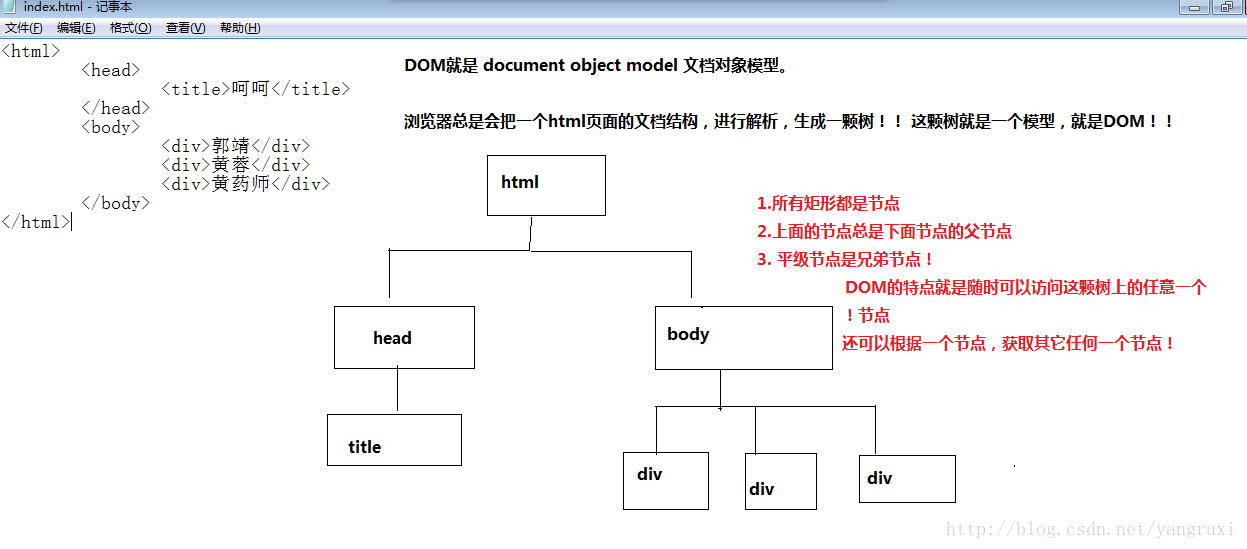
1.每个浏览器都会根据html文档,解析出一个DOM对象。
Document代表整棵树,document.getElementByTd()就是在这棵树上根绝id找节点。
2.所有后缀为xml的文件都必须写的:<?xml version="1.0" encoding="utf-8"?>,它的作用就是告诉程序,xml版本是多少,使用什么编码表。
3.自己编写的xml文件其他内容,完全是自己扩展出来的标签。
4.我们有3种解析xml文件的方式:
jdom dom4j sax
5.解析XML文件的工具可以分为两大类:
(1)将xml解析为一棵树:jdom dom4j…
优点:
这种解析方式,可以随时访问一棵树上的任意一个节点。
缺点:
这种方式需要把整个xml文件的内容加载到内存中,然后才创建dom。如果xml文件的内容特别大,超过58M,就会内存溢出。
(2)将xml不解析为一棵树,而是从上向下扫描:sax
优点:
不会加载整个xml文件到内存中,而是局部加载,扫描到哪里,就加载到哪里,解析到哪里。
缺点:
不会随时随地任意访问xml文件的任意节点,不会修改xml文件(不能添加节点,删除节点,修改节点)。
jdom解析XML文件
其实,安装好jdk以后,jdk自带的API就有能XML的API,但是Java自带的API操作再来太麻烦,所以出现了jdom,jdom是对原声Java解析XML API的封装,操作起来更简单方便。
jdom解析XML文件具体步骤可以参考下面这个例子:
1.XML文件中写:
student.xml:
<?xml version="1.0" encoding="UTF-8"?>
<!DOCTYPE students SYSTEM "students.dtd">
<students>
<student>
<id>1</id>
<name>张三</name>
<age unit="岁">20</age>
</student>
<student>
<id>2</id>
<name>李四</name>
<age unit="岁">30</age>
</student>
<student>
<id>3</id>
<name>王五</name>
<age unit="岁">40</age>
</student>
</students>
2.dtd文件:一套为了进行程序间的数据交换而建立的关于标记符的语法规则。
student.dtd:
<!ELEMENT students (student*) >
<!ELEMENT student (id,name,age) >
<!ELEMENT id (#PCDATA) >
<!ELEMENT name (#PCDATA) >
<!ELEMENT age (#PCDATA) >
<!ATTLIST age unit CDATA #REQUIRED> 3.利用jdom解析上面那个student.xml文件:
package com.westos.jdom;
import java.io.File;
import java.io.FileOutputStream;
import java.util.List;
import org.jdom.Attribute;
import org.jdom.Document;
import org.jdom.Element;
import org.jdom.input.SAXBuilder;
import org.jdom.output.XMLOutputter;
public class App {
public static void find() throws Exception {
// 创建一个解析器
SAXBuilder sb = new SAXBuilder();
// 打开验证模式
sb.setValidation(true);
// 用解析器来解析一个xml文件,得到一个Document对象,此时树已经生成
Document document = sb.build(new File("src/students.xml"));
// 通过document对象,可以获取根对象
Element root = document.getRootElement();
// 再从根对象中获取所有子节点
List<Element> list = root.getChildren();
for (Element elt : list) {
System.out.println("===================================");
System.out.println(elt.getName());
Element id = elt.getChild("id");
Element name = elt.getChild("name");
Element age = elt.getChild("age");
System.out.println("id:" + id.getText());
System.out.println("name:" + name.getText());
System.out.println("age:" + age.getText() + age.getAttribute("unit").getValue());
}
}
public static void save() throws Exception {
SAXBuilder sb = new SAXBuilder();
Document document = sb.build(new File("src/students.xml"));
Element root = document.getRootElement();
List<Element> list = root.getChildren();
Element student = new Element("student");
Element id = new Element("id");
Element name = new Element("name");
Element age = new Element("age");
Attribute unit = new Attribute("unit", "岁");
Attribute aaa = new Attribute("aaa", "bbb");
age.setAttribute(unit);
age.setAttribute(aaa);
id.setText("5");
name.setText("马青青");
age.setText("25");
student.addContent(id);
student.addContent(name);
student.addContent(age);
list.add(student);
// 存盘
XMLOutputter xmlout = new XMLOutputter();
xmlout.output(document, new FileOutputStream(new File("src/students.xml")));
}
public static void update() throws Exception {
SAXBuilder sb = new SAXBuilder();
Document document = sb.build(new File("src/students.xml"));
Element root = document.getRootElement();
List<Element> list = root.getChildren();
// 把id为4的学生,名字改为赵六
for (Element elt : list) {
Element id = elt.getChild("id");
if("4".equals(id.getText())) {
Element name = elt.getChild("name");
Element age = elt.getChild("age");
name.setText("赵六");
age.setText("40");
}
}
// 存盘
XMLOutputter xmlout = new XMLOutputter();
xmlout.output(document, new FileOutputStream(new File("src/students.xml")));
}
public static void delete() throws Exception {
SAXBuilder sb = new SAXBuilder();
Document document = sb.build(new File("src/students.xml"));
Element root = document.getRootElement();
List<Element> list = root.getChildren();
// 把id为4的学生,删除掉
Element del = null;
for (Element elt : list) {
Element id = elt.getChild("id");
if("3".equals(id.getText())) {
del = elt;
break;
}
}
list.remove(del);
// 存盘
XMLOutputter xmlout = new XMLOutputter();
xmlout.output(document, new FileOutputStream(new File("src/students.xml")));
}
public static void main(String[] args) throws Exception {
find();
}
}
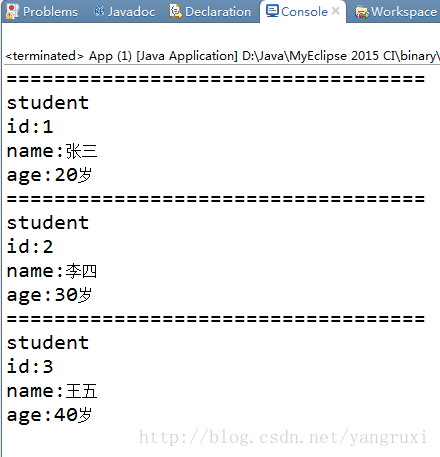
运行结果:
dom4j解析XML文件
jdom能完成什么功能,dom4j也能完成,但是dom4j还支持强大的XPath。
dom4j解析XML文件具体步骤可以参考下面这个例子:
1.XML文件中写:
student.xml:
<?xml version="1.0" encoding="UTF-8"?>
<!DOCTYPE students SYSTEM "students.dtd">
<students>
<student>
<id>1</id>
<name>张三</name>
<age unit="岁">20</age>
</student>
<student>
<id>2</id>
<name>李四</name>
<age unit="岁">30</age>
</student>
<student>
<id>3</id>
<name>王五</name>
<age unit="岁">40</age>
</student>
</students>
2.dtd文件中写:
student.dtd:
<!ELEMENT students (student*) >
<!ELEMENT student (id,name,age) >
<!ELEMENT id (#PCDATA) >
<!ELEMENT name (#PCDATA) >
<!ELEMENT age (#PCDATA) >
<!ATTLIST age unit CDATA #REQUIRED> 3.利用jdom解析上面那个student.xml文件:
package com.westos.dom4j;
import java.io.File;
import java.io.FileOutputStream;
import java.util.List;
import org.dom4j.Attribute;
import org.dom4j.Document;
import org.dom4j.Element;
import org.dom4j.io.OutputFormat;
import org.dom4j.io.SAXReader;
import org.dom4j.io.XMLWriter;
import org.dom4j.tree.DefaultElement;
public class App {
public static void find() throws Exception {
// 创建解析器
SAXReader sr = new SAXReader();
// 使用解析器去解析一个xml文件,得到一个Document对象
Document document = sr.read(new File("src/students.xml"));
// 获取根元素,根据根元素获取所有子节点
Element root = document.getRootElement();
List<Element> list = root.elements();
for (Element stu : list) {
System.out.println("=================================");
System.out.println(stu.getName());
Element id = stu.element("id");
Element name = stu.element("name");
Element age = stu.element("age");
Attribute unit = age.attribute("unit");
System.out.println("id:" + id.getText());
System.out.println("name:" + name.getText());
System.out.println("age:" + age.getText() + unit.getValue());
}
}
public static void save() throws Exception {
// 创建解析器
SAXReader sr = new SAXReader();
// 使用解析器去解析一个xml文件,得到一个Document对象
Document document = sr.read(new File("src/students.xml"));
// 获取根元素,根据根元素获取所有子节点
Element root = document.getRootElement();
List<Element> list = root.elements();
// 添加一个新学生
Element stu = new DefaultElement("student");
Element id = new DefaultElement("id");
Element name = new DefaultElement("name");
Element age = new DefaultElement("age");
age.setAttributeValue("unit", "岁");
id.setText("11");
name.setText("php门徒");
age.setText("24");
stu.add(id);
stu.add(name);
stu.add(age);
list.add(stu);
// 存盘
OutputFormat formatter = OutputFormat.createPrettyPrint();
XMLWriter xWriter = new XMLWriter(new FileOutputStream(new File("src/students.xml")), formatter);
xWriter.write(document);
}
public static void update() throws Exception {
// 创建解析器
SAXReader sr = new SAXReader();
// 使用解析器去解析一个xml文件,得到一个Document对象
Document document = sr.read(new File("src/students.xml"));
// 获取根元素,根据根元素获取所有子节点
Element root = document.getRootElement();
List<Element> list = root.elements();
// 把id为11的学生,名字改为php骨灰级玩家
for (Element stu : list) {
Element id = stu.element("id");
if("11".equals(id.getText())) {
Element name = stu.element("name");
name.setText("php骨灰级玩家");
break;
}
}
// 存盘
OutputFormat formatter = OutputFormat.createPrettyPrint();
XMLWriter xWriter = new XMLWriter(new FileOutputStream(new File("src/students.xml")), formatter);
xWriter.write(document);
}
public static void delete() throws Exception {
// 创建解析器
SAXReader sr = new SAXReader();
// 使用解析器去解析一个xml文件,得到一个Document对象
Document document = sr.read(new File("src/students.xml"));
// 获取根元素,根据根元素获取所有子节点
Element root = document.getRootElement();
List<Element> list = root.elements();
// 把id为10的学生,删除
int size = list.size();
for (int i = 0; i < size; i++) {
Element stu = list.get(i);
Element id = stu.element("id");
if("10".equals(id.getText())) {
list.remove(stu);
break;
}
}
// 存盘
OutputFormat formatter = OutputFormat.createPrettyPrint();
XMLWriter xWriter = new XMLWriter(new FileOutputStream(new File("src/students.xml")), formatter);
xWriter.write(document);
}
}
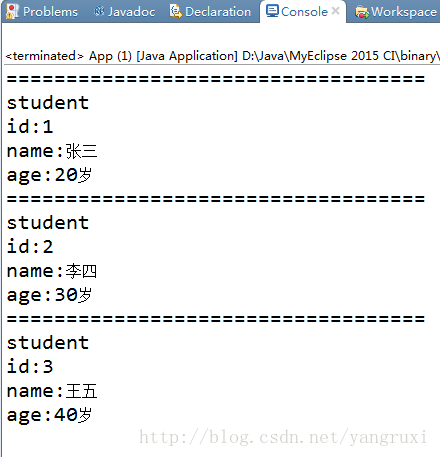
运行结果:
测试dom4j的XPath(Xml Path):
1.foo.xml:
<?xml version="1.0" encoding="utf-8"?>
<AAA>
<BCC>
<BBB/>
<BBB/>
<BBB/>
</BCC>
<DDB>
<BBB/>
<BBB/>
</DDB>
<BEC>
<CCC/>
<DBD/>
</BEC>
</AAA> 2.testXPath方法:
public static void testXPath() throws Exception {
// 创建解析器
SAXReader sr = new SAXReader();
// 使用解析器去解析一个xml文件,得到一个Document对象
Document document = sr.read(new File("src/foo.xml"));
// 使用XPath技术,不需要获取根节点,而是直接调用document的一个api: selectNodes
List<Element> list = document.selectNodes("//*[contains(name(),'C')]");
for (Element elt : list) {
System.out.println(elt.getName());
}
// List<Attribute> list = document.selectNodes("//@id");
// for (Attribute elt : list) {
// System.out.println(elt.getName() + ":" + elt.getValue());
// }
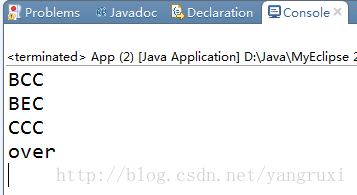
System.out.println("over");运行结果:
sax解析XML文件
还是解析上面那个student.xml文件。
package com.westos.sax;
import java.io.File;
import java.io.FileInputStream;
import javax.xml.parsers.SAXParser;
import javax.xml.parsers.SAXParserFactory;
import org.apache.xerces.jaxp.SAXParserFactoryImpl;
import org.xml.sax.Attributes;
import org.xml.sax.SAXException;
import org.xml.sax.XMLReader;
import org.xml.sax.helpers.DefaultHandler;
public class App {
public static void find() throws Exception {
// 创建解析器
SAXParserFactory spf = new SAXParserFactoryImpl();
SAXParser sp = spf.newSAXParser();
XMLReader reader = sp.getXMLReader();
// 设置事件
reader.setContentHandler(new DefaultHandler(){
private String tag;
// 碰到标记开始
public void startElement(String uri, String localName,
String qName, Attributes attributes) throws SAXException {
// System.out.println(qName+"开始");
tag = qName;
}
// 碰到内容开始
public void characters(char[] ch, int start, int length)
throws SAXException {
if("name".equals(tag)) {
System.out.println(new String(ch,start,length));
}
}
// 碰到结束标记开始
public void endElement(String uri, String localName, String qName)
throws SAXException {
// System.out.println(qName+"结束");
}
});
// 使用解析器,去解析一个xml文件, 此时没有Document生成
reader.parse("src/students.xml");
}
public static void main(String[] args) throws Exception {
find();
}
}
运行结果:
张三
李四
王五