redis是一个内存数据库,数据库的状态被存储在内存中。但是这就存在一个问题:如果没存在磁盘中,一但将服务器关闭,就会使得服务器中的数据库状态消失。为了解决这样的问题,Redis提供了RDB持久化功能,将内存中的数据库状态保存到磁盘中,当服务器关闭,数据库状态也不会意外丢失。
RDB持久化功能会生成一个压缩了的二进制文件、RDB文件。这个文件保存着生成RDB文件时的数据库状态,当需要时,RDB文件可以被还原为数据库状态。这样就实现了在Redis数据库服务器退出时,只要生成了RDB文件,下一次开启时,仍然能够使用生成RDB文件服务器保存的数据库状态。
一,创建和载入RDB文件
生成RDB文件有两种触发机制:手动触发和自动触发。
手动触发:使用命令SAVE或者BGSAVE。
自动触发:根据服务器配置选项定期执行。
save 900 1 //服务器在900秒之内,对数据库执行了至少1次修改
save 300 10 //服务器在300秒之内,对数据库执行了至少10修改
save 60 1000 //服务器在60秒之内,对数据库执行了至少1000修改
// 满足以上三个条件中的任意一个,则自动触发 BGSAVE 操作
// 或者使用命令CONFIG SET 命令配置
生成RDB文件的命令有两个:一个是SAVE另一个是BGSAVE。
1.1、save命令
1,SAVE命令生成RDB文件:
![]()
SAVE命令生成RDB文件时,会阻塞服务器进程,只有RDB文件生成后结束才能继续执行其他命令。
2,SAVE实现源代码://代码来源:https://github.com/menwengit/redis_source_annotation/blob/master/rdb.c
// SAVE 命令实现
void saveCommand(client *c) {
// 如果正在执行持久化操作,则退出
if (server.rdb_child_pid != -1) {
addReplyError(c,"Background save already in progress");
return;
}
// 执行SAVE
if (rdbSave(server.rdb_filename) == C_OK) {
addReply(c,shared.ok);
} else {
addReply(c,shared.err);
}
}1.2、BGSAVE
1、BGSAVE命令生成RDB文件:
![]()
BGSAVE命令在执行时,不同于save命令不会阻塞服务器,而是采用派生一个子进程去执行。因此在BGSAVE命令执行时,服务器还可以执行其他的命令。但是不能执行save命令,服务器禁止同时执行BGSAVE命令和SAVE命令。
2、BGSAVE命令源码:
// BGSAVE 命令实现
void bgsaveCommand(client *c) {
int schedule = 0; //SCHEDULE控制BGSAVE的执行,避免和AOF重写进程冲突
/* The SCHEDULE option changes the behavior of BGSAVE when an AOF rewrite
* is in progress. Instead of returning an error a BGSAVE gets scheduled. */
if (c->argc > 1) {
// 设置schedule标志
if (c->argc == 2 && !strcasecmp(c->argv[1]->ptr,"schedule")) {
schedule = 1;
} else {
addReply(c,shared.syntaxerr);
return;
}
}
// 如果正在执行RDB持久化操作,则退出
if (server.rdb_child_pid != -1) {
addReplyError(c,"Background save already in progress");
// 如果正在执行AOF持久化操作,则退出
} else if (server.aof_child_pid != -1) {
// 如果schedule为真,设置rdb_bgsave_scheduled为1,表示可以执行BGSAVE
if (schedule) {
server.rdb_bgsave_scheduled = 1;
addReplyStatus(c,"Background saving scheduled");
} else {
addReplyError(c,
"An AOF log rewriting in progress: can't BGSAVE right now. "
"Use BGSAVE SCHEDULE in order to schedule a BGSAVE whenver "
"possible.");
}
// 执行BGSAVE
} else if (rdbSaveBackground(server.rdb_filename) == C_OK) {
addReplyStatus(c,"Background saving started");
} else {
addReply(c,shared.err);
}
}1.3、RDB文件的载入
RDB文件的载入,在服务器开启时自动执行(服务器在开启时自动检测是否有RDB文件,如果有自动载入),因此没有载入RDB文件的命令。
这里需要注意,如果AOF持久化和RDB持久化同时被开启了的。就会优先载入AOF文件,来还原数据库状态。(因为AOF文件更新频率通常比RDB文件更新频率高。)
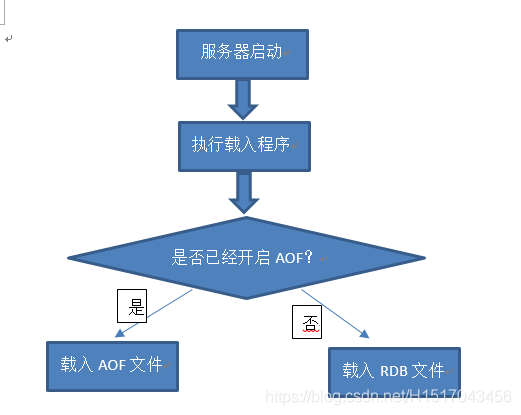
在载入RDB文件时,服务器一直处于阻塞状态,不能执行其他命令。
二、自动间隔性保存
2.1、自动保存条件的设置和实现
上面提到了,生成RDB文件有两种方式,其中一种是自动执行。而其本质就是Redis允许用户通过设置服务器配置的save选项,让服务器每隔一段时间自动执行一次BGSAVE命令。
save 900 1 //服务器在900秒之内,对数据库执行了至少1次修改
save 300 10 //服务器在300秒之内,对数据库执行了至少10修改
save 60 1000 //服务器在60秒之内,对数据库执行了至少1000修改
// 满足以上三个条件中的任意一个,则自动触发 BGSAVE 操作
// 或者使用命令CONFIG SET 命令配置
以上就是向服务器进行save选项的配置。
struct redisServer {
// 数据库数组,长度为16
redisDb *db;
// 从节点列表和监视器列表
list *slaves, *qiank; /* List of slaves and MONITORs */
/* RDB / AOF loading information ××××××××××××××××××××××××××××××××××××××××××××××××××××××××××*/
// 正在载入状态
int loading; /* We are loading data from disk if true */
// 设置载入的总字节
off_t loading_total_bytes;
// 已载入的字节数
off_t loading_loaded_bytes;
// 载入的开始时间
time_t loading_start_time;
// 在load时,用来设置读或写的最大字节数max_processing_chunk
off_t loading_process_events_interval_bytes;
// 服务器内存使用的
size_t stat_peak_memory; /* Max used memory record */
// 计算fork()的时间
long long stat_fork_time; /* Time needed to perform latest fork() */
// 计算fork的速率,GB/每秒
double stat_fork_rate; /* Fork rate in GB/sec. */
/* RDB persistence ××××××××××××××××××××××××××××××××××××××××××××××××××××××××××××××××××××××××××××*/
// 脏键,记录数据库被修改的次数
long long dirty; /* Changes to DB from the last save */
// 在BGSAVE之前要备份脏键dirty的值,如果BGSAVE失败会还原
long long dirty_before_bgsave; /* Used to restore dirty on failed BGSAVE */
// 执行BGSAVE的子进程的pid
pid_t rdb_child_pid; /* PID of RDB saving child */
// 保存save参数的数组
struct saveparam *saveparams; /* Save points array for RDB */
// 数组长度
int saveparamslen; /* Number of saving points */
// RDB文件的名字,默认为dump.rdb
char *rdb_filename; /* Name of RDB file */
// 是否采用LZF压缩算法压缩RDB文件,默认yes
int rdb_compression; /* Use compression in RDB? */
// RDB文件是否使用校验和,默认yes
int rdb_checksum; /* Use RDB checksum? */
// 上一次执行SAVE成功的时间
time_t lastsave; /* Unix time of last successful save */
// 最近一个尝试执行BGSAVE的时间
time_t lastbgsave_try; /* Unix time of last attempted bgsave */
// 最近执行BGSAVE的时间
time_t rdb_save_time_last; /* Time used by last RDB save run. */
// BGSAVE开始的时间
time_t rdb_save_time_start; /* Current RDB save start time. */
// 当rdb_bgsave_scheduled为真时,才能开始BGSAVE
int rdb_bgsave_scheduled; /* BGSAVE when possible if true. */
// rdb执行的类型,是写入磁盘,还是写入从节点的socket
int rdb_child_type; /* Type of save by active child. */
// BGSAVE执行完的状态
int lastbgsave_status; /* C_OK or C_ERR */
// 如果不能执行BGSAVE则不能写
int stop_writes_on_bgsave_err; /* Don't allow writes if can't BGSAVE */
// 无磁盘同步,管道的写端
int rdb_pipe_write_result_to_parent; /* RDB pipes used to return the state */
// 无磁盘同步,管道的读端
int rdb_pipe_read_result_from_child; /* of each slave in diskless SYNC. */
/* time cache ××××××××××××××××××××××××××××××××××××××××××××××××××××××××××××××××××××××××××××*/
// 保存秒单位的Unix时间戳的缓存
time_t unixtime; /* Unix time sampled every cron cycle. */
// 保存毫秒单位的Unix时间戳的缓存
long long mstime; /* Like 'unixtime' but with milliseconds resolution. */
/* Latency monitor ××××××××××××××××××××××××××××××××××××××××××××××××××××××××××××××××××××××××××××*/
// 延迟的阀值
long long latency_monitor_threshold;
// 延迟与造成延迟的事件关联的字典
dict *latency_events;
};
---------------------
作者:men_wen
来源:CSDN
原文:https://blog.csdn.net/men_wen/article/details/71248449
版权声明:本文为博主原创文章,转载请附上博文链接!save命令实现依靠着redisServer中的saveparams属性。saveparam属性是一个数组,数组中的每一个saveparam结构如下:
struct saveparam{
//秒数
time_t seconds;
//修改数
int changes;
};修改save选项的配置就是在修改saveparam中的seconds和changes。
2.2、dirty计数器和lastsave属性
redisServer结构中还有两个于RDB文件生成重要的属性:dirty计数器,lastsave属性。
- dirty计数器记录距离上一次成功执行save命令或BGSAVE命令后,服务器对数据库进行了多少次修改(写入,删除,更新等操作)当成功执行一个数据库修改命令后,dirty计数器就会被更新。
- lastsave属性:是一个Unix时间戳,记录了上一次成功执行save命令或BGSAVE命令的时间。
2.3,检查保存条件是否满足
redis服务器会周期性的操作函数serverCron(默认100毫秒执行一次),对正在进行的服务器进行检查维护,其中就会检查是否满足save选项的配置,如果满足就会自动执行BGSAVE命令。
三,RDB文件结构组成
一个RDB文件的各个部分:

- RDB文件最开头的部分redis标识,5个字节大小,保存着“REDIS”五个字符。在程序载入时,可以通过这个标识快速的确认载入的文件是否是RDB文件。
- db_version:长4字节,它的值是由字符串表示的整数,这个整数记录了RDB文件的版本号。
- databases部分包含着0个或任意多个数据库,以及数据库中的键值对数据。
- EOF:长度1字节,这个常量标志着RDB文件正文内容的结束,当读到这个值的时候,对于RDB文件的载入就结束了。
- check_sum:长8个字节的无符号整数,保存着一个校验和。这个校验和等于前面4个部分的内容计算出的。服务器载入RDB文件会将载入数据经计算然后和check_sum进行比较判断RDB文件是否出错或者被损坏。
四、databases
RDB文件的database部分用于保存任意数量的非空数据库。

database 0 表示0号数据库中的所有键值对数据,database 1表示1号数据库所有键值对数据。
在RDB文件中,每个非空数据库可以保存为:SELECTDB、db_number、key_value_pairs三个部分。
- SELECTDB常量的长度为1字节,当读入程序到这里时就能识别将要读入一个数据库号码。
- db_number:保存着数据库号码。程序读到db_number时,服务器使用SELECT命令,根据这个号码切换到相应的数据库。使得数据载入到相应的数据库中。
- key_value_pairs:保存了数据库中的所有键值对数据。这里包括:键值对的数量、类型、内容以及过期时间等。
key_value_pairs:又分为了type,key,value三个部分。这里的key就是键对象,value是值对象。type保存了value的编码方式。
五、RDB的优缺点
- 优点:
RDB是一个紧凑压缩的二进制文件,代表Redis在某个时间点上的数据快照。非常适用于备份,全景复制等场景。Redis 加载RDB恢复数据远远快于AOF的方式。 - RDB没有办法做到实时持久化或秒级持久化。因为BGSAVE每次运行的又要进创建子进程,这属于重量级操作,频繁执行成本过高,因为虽然Linux支持读时共享,写时拷贝(copy-on-write)的技术,但是仍然会有大量的父进程的空间内存页表,信号控制表,寄存器资源等等的复制。
RDB文件使用特定的二进制格式保存,Redis版本演进的过程中,有多个RDB版本,这导致版本兼容的问题。
