在指定的时间间隔内将内存中的数据集快照写入磁盘,也就是Snapshot快照,它恢复时是将快照文件直接读到内存里。
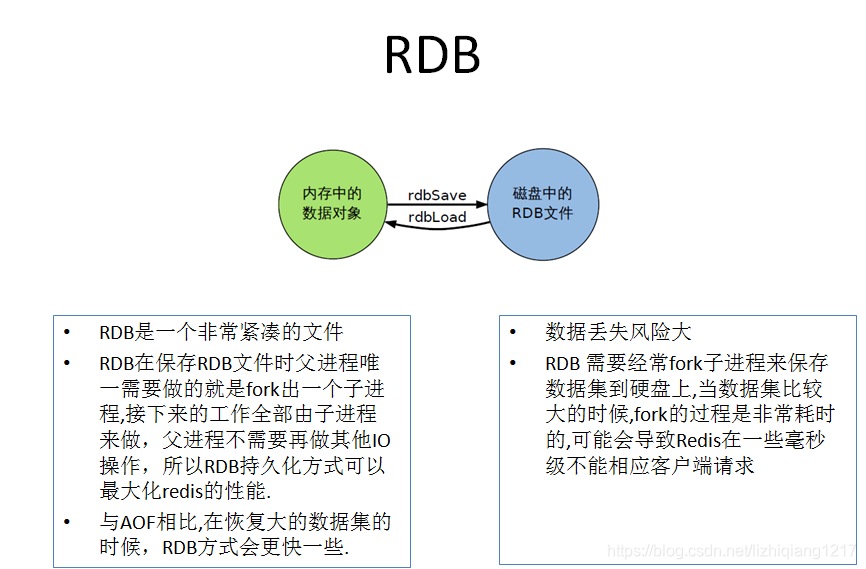
Redis会单独创建(fork)一个子进程来进行持久化,会先将数据写入到一个临时文件中,待持久化过程都结束了,再用这个临时文件替换上次持久化好的文件。整个过程中,主进程是不进行任何IO操作的,这就确保了极高的性能。如果需要进行大规模数据的恢复,且对于数据恢复的完整性不是非常敏感,那RDB方式要比AOF方式更加的高效。RDB的缺点是最后一次持久化后的数据可能丢失。
Fork的作用是复制一个与当前进程一样的进程。新进程的所有数据(变量、环境变量、程序计数器等)。数值都和原进程一致,但是是一个全新的进程,并作为原进程的子进程。
Rdb 保存的是dump.rdb文件。
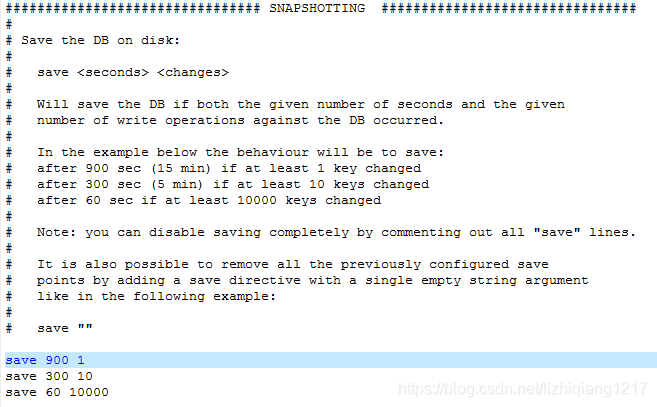
redis会自动把数据备份到dump.rdb文件中。要恢复数据只需将备份文件 (dump.rdb) 移动到 redis 安装目录并启动服务即可。注意:shutdown和flushall操作会清空内存,并生成新的dump.rdb空文件。
命令:
1、可以执行save命令或者bgsave命令手动备份数据。save:save时只管保存,其它不管,全部阻塞。bgsave:Redis会在后台异步进行快照操作,快照同时还可以响应客户端请求。可以通过lastsave命令获取最后一次成功执行快照的时间。
2、停止RDB保存规则的方法:redis-cli config set save ""
优势:
1、适合大规模的数据恢复。
2、对数据完整性和一致性要求不高。
劣势:
1、在一定间隔时间做一次备份,所以如果redis意外down掉的话,就会丢失最后一次快照后的所有修改。
2、Fork的时候,内存中的数据被克隆了一份,大致2倍的膨胀性需要考虑。
redis持久化-RDB
猜你喜欢
转载自blog.csdn.net/lizhiqiang1217/article/details/90108321
今日推荐
周排行