快速排序:是对冒泡排序思想的一种改进
基本思想:分治法。选择一个基准数,比它小的数据放到它的左边,大的放到右边。以基准来切分数组,对切分数组独立排序,直到数据不能再分 (只剩一个数字)。
适用场景:无序且数据量较大
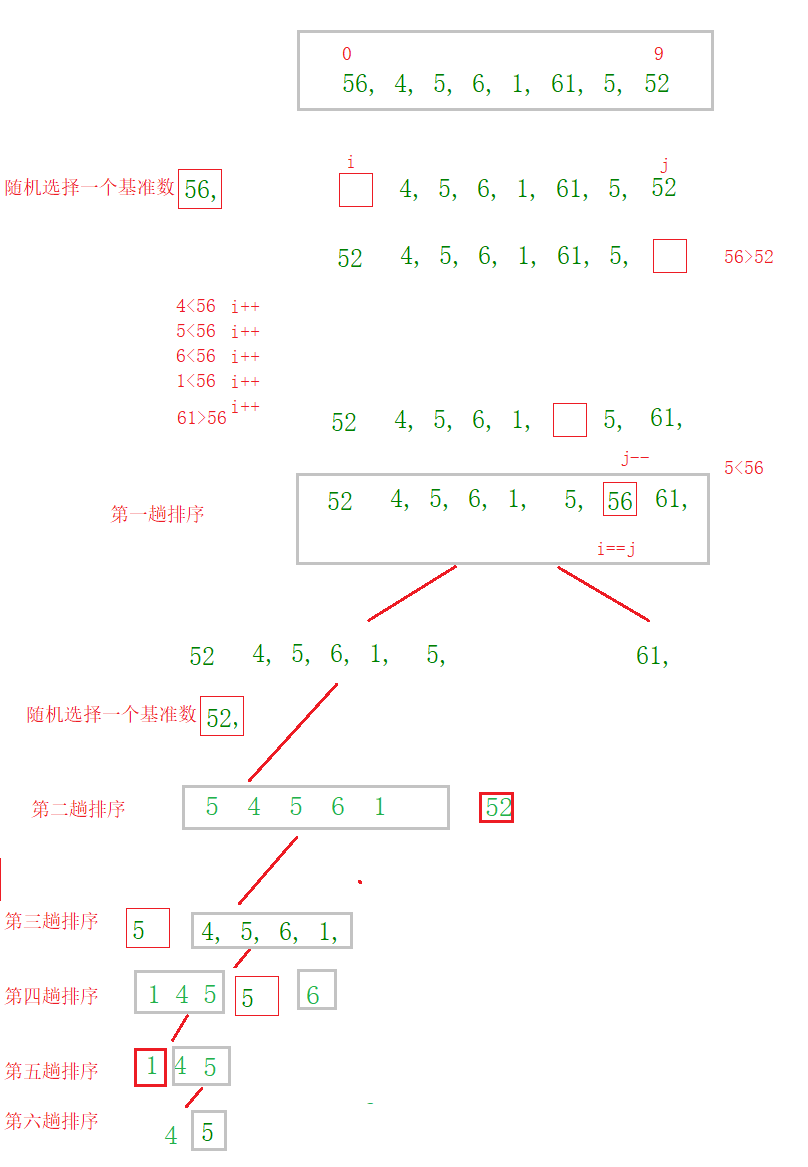
快排大致流程图
1、普通快排的最坏情况
代码如下:
int partition(int arr[], int low, int high)
{
int tmp=arr[low];
while(low!=high)
{
while(low<high && arr[high]>=tmp) high--;
arr[low]=arr[high];
while(low<high && arr[low]<=tmp) low++;
arr[high]=arr[low];
}
arr[low]=tmp;
return low;
}
void Quick(int *arr,int low,int high)
{
if(low<high)
{
int bound=partition(arr,low,high);
Quick(arr,low,bound-1);
Quick(arr,bound+1,high);
}
}
int main()
{
int arr[10]={23,45,112,4,456,1,5,34,11,98};
int len=sizeof(arr)/sizeof(arr[0]);
time_t start,end;
start=clock();//62
Quick(arr,0,len-1);
end=clock();//29142 时间为29080s
return 0;
}
2、优化1: 基本的快排选取第一个或者最后一个元素做基准,这是很不好的处理方法,如果数组此时有序呢?此时的分割就是一个不好的分割,因为每次划分只能使待排序列减1,时间复杂度为 o(n^2)
最好的方法就是选取的基准数刚好能把待排序列分成两个等长的子序列
三分取中法,把数组中第一个元素和最后一个元素,中间元素,三个数比较大小,取中间大小的数字作为基准。
代码如下:
void swap(int arr[], int firstIndex, int secondIndex)
{
int tmp = arr[firstIndex];
arr[firstIndex] = arr[secondIndex];
arr[secondIndex] = tmp;
}
void changeSecondMaxNumber(int arr[], int low, int high, int mid)
{
if (arr[high] < arr[mid])
{
swap(arr, mid, high);
}
if (arr[low] < arr[mid])
{
swap(arr, mid, low);
}
if (arr[low] > arr[high])
{
swap(arr, high, low);
}
}
int partition(int arr[], int low, int high)
{
int tmp= arr[low];
while(low!=high)
{
while(low<high && arr[high]>=tmp) high--;
arr[low]=arr[high];
while(low<high && arr[low]<=tmp) low++;
arr[high]=arr[low];
}
arr[low]=tmp;
return low;
}
void Quick(int *arr,int low,int high)
{
if(low<high)
{
changeSecondMaxNumber(arr,low,high,(high-low)/2+low);
int bound=partition(arr,low,high);
Quick(arr,low,bound-1);
Quick(arr,bound+1,high);
}
}
int main()
{
int arr[12]={23,45,112,4,456,1,5,34,11,98,7,0};
int len=sizeof(arr)/sizeof(arr[0]);
time_t start,end;
start=clock(); //2202
Quick(arr,0,len-1);
end=clock(); //5654 3452s
return 0;
}
3、优化3:数据量较小时,还是选用选择排序的思想,时间复杂度要小一些,排序效率高。
4、优化4:聚合 把与基准点相同的数据聚合在一起 ,不进行下一趟排序
代码如下:
void Gather(int *arr,int low,int high,int bound,int *left,int* right)
{
int count=bound-1;
for(int i=bound-1;i>=0;--i)
{
if(arr[i]==arr[bound])
{
swap(arr,i,count);
count--;
}
}
*left=count;
count=bound+1;
for(int i=bound+1;i<high;++i)
{
if(arr[i]==arr[bound])
{
swap(arr,i,count);
count++;
}
}
*right=count;
}