无聊医生玩python
爬虫------mzitu图片下载
自己没事写的图片下载爬虫
用到的包主要是urllib和re
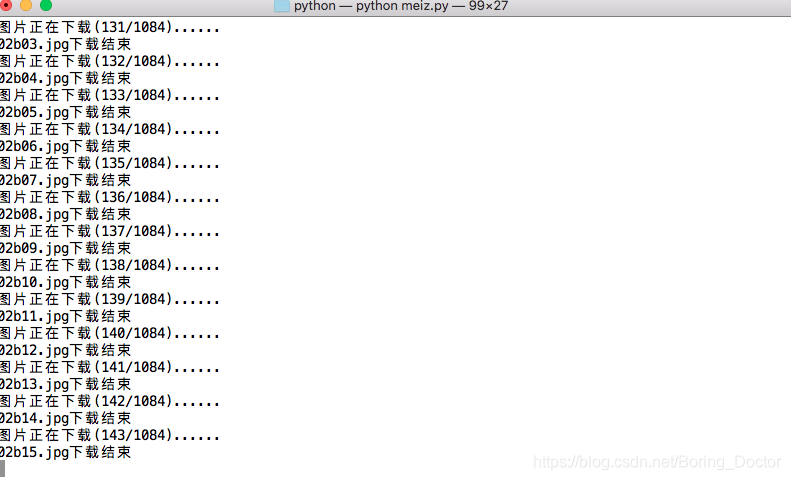
先看下使用效果

下载过程
代码
关键的步骤都加了注释,不做说明
import urllib.request
import urllib.parse
import os
import time
import re
def handle_request(url, page = None):
'''构建发送请求,返回request'''
if page == None:
url = url
else:
url = url + str(page) + '/'
headers = {'User-Agent': 'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_13_6) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/72.0.3626.96 Safari/537.36'}
# print(url)
request = urllib.request.Request(url = url, headers = headers)
return request
def img_src(content):
'''提取图片地址,返回图片地址列表'''
pattern = re.compile(r'<li>.*?<a href="(.*?)".*?>.*?</li>',re.S)
mo = pattern.search(content)
page_url = mo.group(1)
request = handle_request(page_url)
content = urllib.request.urlopen(request).read().decode()
# 匹配字段确定每组图片张数
pattern = re.compile(r'<span>(\d\d)</span>')
mo = pattern.search(content)
totle_page = mo.group(1)
ls = []
for ii in range(1, int(totle_page)+1):
url_img = page_url+'/'+str(ii)
ls.append(url_img)
return ls
# print(ls)
# print(len(ls))
def down_img(content):
'''提取图片地址,访问并下载图片'''
pattern = re.compile(r'<div class="main-image">.*?<img src="(.*?)".*?>.*?</div>', re.S)
mo = pattern.search(content)
image_src = mo.group(1)
#print(image_src)
# 创建文件名及文件路径
dirname = 'meizi'
if not os.path.exists(dirname):
os.mkdir(dirname)
filename = image_src.split('/')[-1]
filepath = dirname + '/' + filename
#为使用urlretrieve()添加请求头,注意请求头格式为元组列表
myheaders = [
('Referer', 'https://www.mzitu.com'),
('Upgrade-Insecure-Requests', '1'),
('User-Agent', 'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_13_6) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/72.0.3626.96 Safari/537.36'),
]
opener = urllib.request.build_opener()
opener.addheaders = myheaders
urllib.request.install_opener(opener)
# 下载图片
urllib.request.urlretrieve(image_src,filepath )
print('%s下载结束'%filename)
time.sleep(2)
def main():
'''根据输入的页码,下载mzitu中图片'''
url = 'https://www.mzitu.com/page/'
page = int(input('请输入下载页码(每页约1000张): '))
print('第%s页开始下载......' %page)
request = handle_request(url, page)
content = urllib.request.urlopen(request).read().decode()
url_list = img_src(content)
totle = len(url_list)
n = 0
for url_img in url_list:
# print(url_img)
request = handle_request(url_img)
content = urllib.request.urlopen(request).read().decode()
n += 1
print('图片正在下载(%d/%d)......' %(n, totle))
down_img(content)
print('第%d页下载结束' %page)
if __name__ == '__main__':
main()
注意几点
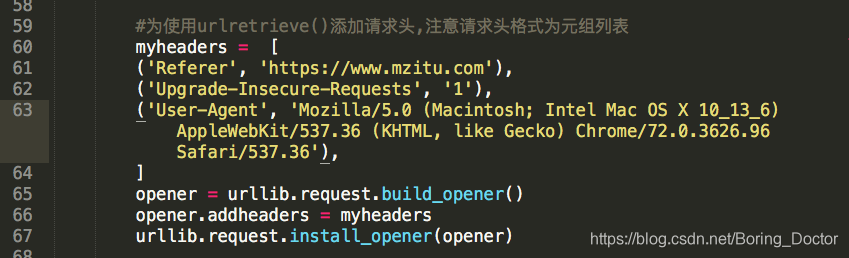
主要是这几行由于urlretrieve不带请求头,在网上搜索了加headers的方法.问题迎刃而解.
好久不写爬虫了,其实是后来用了scrapy框架后,发现框架具有异步多线程的特点,异常强大,写起来也比这种脚本的爬虫简单.
闲来没事对上面的爬虫做了一些改动,主要是改用了requests和xpath, 加了多线程(threading),随机请求头(fake_useragent),文件夹分类,重复请求(@retry),时间统计(time),日志(logging)等等的,这些都不是必须的,主要是用着好玩儿,而且会让代码更强壮一点儿. inputdigit是自己写的一个小模块,主要是判断输入的是否是合法数字,可以直接input替代.代码如下:
import requests
import os,re,time,random
import threading
from lxml import etree
from fake_useragent import UserAgent
from inputdigit import inputdigit
from retrying import retry
import logging
logging.basicConfig (level=logging.INFO, format='%(asctime)s - %(levelname)s - %(message)s')
def _result(result):
return result is None
@retry(stop_max_attempt_number=5, wait_random_min=1000, wait_random_max=2000, retry_on_result=_result)
def handle_requests(url, page = None):
'''构建发送请求,返回requests'''
if page:
url = url + str(page) + '/'
#创建随机请求头
ua = UserAgent()
headers = {'User-Agent': ua.random}
r = requests.get(url = url, headers = headers, timeout = 5)
if r.status_code !=200:
raise requests.RequestException('my_request_get error!!!!')
return r
def img_src(content):
'''提取图片地址,返回图片名称日期及地址列表'''
tree = etree.HTML(content)
li_list = tree.xpath('//ul[@id="pins"]/li')
# print(li_list)
# print(len(li_list))
item_ls = []
for li in li_list:
href_ls = li.xpath('.//span/a/@href')
if len(href_ls) != 0:
href = href_ls[0]
dirname_ls = li.xpath('.//span/a/text()')
if len(dirname_ls) != 0:
dirname = dirname_ls[0]
_time_ls = li.xpath('.//span[@class="time"]/text()')
if len(_time_ls) != 0:
_time = _time_ls[0]
item = {
'time': _time,
'dirname':dirname,
'href':href
}
item_ls.append(item)
return item_ls
def img_nums(content):
# 匹配字段确定每组图片张数
pattern = re.compile(r'<span>(\d\d)</span>')
totle_page = pattern.findall(content)
# print(totle_page)
# exit()
return totle_page[0]
def down_img(content,dirname):
'''下载图片到指定目录'''
tree = etree.HTML(content)
image_src = tree.xpath('.//div[@class="main-image"]/p/a/img/@src')[0]
# 创建文件名及文件路径
filename = os.path.basename(image_src)
filepath = os.path.join(dirname, filename)
ua = UserAgent()
headers = {'User-Agent': ua.random,
'Referer': 'https://www.mzitu.com'}
# 发送请求下载图片
r = requests.get(image_src, headers = headers, timeout = (3, 7))
with open(filepath, 'wb') as fp:
fp.write(r.content)
# urllib.request.urlretrieve(image_src,filepath )
logging.info(' {}下载结束'.format(filename))
time.sleep(random.randint(1,3))
def download_handler(image):
dirname = '/Volumes/MSDOS/pics/meizi/[' + image['time']+ ']' + image['dirname']
if not os.path.exists(dirname):
os.makedirs(dirname)
else:
logging.info('{}已存在.'.format(image['dirname']))
return
r = handle_requests(image['href'])
totle_page = img_nums(r.text)
logging.info('****{}开始下载.****'.format(image['dirname']))
for img_page in range(1, int(totle_page)+1):
img_url = image['href'] + '/' + str(img_page)
r = handle_requests(img_url)
down_img(r.text, dirname)
def main():
'''根据输入的页码,下载mzitu中图片'''
url = 'https://www.mzitu.com/page/'
page = inputdigit('请输入下载页码: ')
r = handle_requests(url, page)
url_list = img_src(r.content)
x = 1
for image_num in url_list:
print(image_num['time'] + image_num['dirname'] + '__' + str(x))
x += 1
print('第{}页共有{}套'.format(page, len(url_list)))
sp = inputdigit('请输入下载起始: ')
ep = inputdigit('请输入下载起始: ')
t_num = inputdigit('请输入开启的线程数: ')
sp = sp - 1
start_time = time.time()
for i in range(0,(ep-sp)//t_num):
thread_list = []
for image in url_list[sp+i:ep:(ep-sp)//t_num]:
#使用多线程下载图像
download_thread = threading.Thread(target = download_handler, args = [image,])
thread_list.append(download_thread)
download_thread.start()
logging.info('*'*40+'\n'+'第{}/{}组线程开始下载.'.format(i+1,(ep-sp)//t_num).center(60)+'\n'+'*'*70)
#等待所有线程结束后再继续后面的主线程
for download_thread in thread_list:
download_thread.join()
logging.info('#'*40+'\n'+'第{}/{}组线程下载结束.'.format(i+1, (ep-sp)//t_num).center(60)+'\n'+'#'*70)
use_time = int(time.time() - start_time)
logging.info('\n全部下载结束, 用时: {}分{}秒。\n\n'.format(use_time//60, use_time%60))
if __name__ == '__main__':
main()
