简介
这一篇我讲给大家分享如何自定义输入和输出,可能听起来比较抽象,我们用实际应用中的一个例子来说明。
自定义输入问题
我们现在有这样的数据文件,
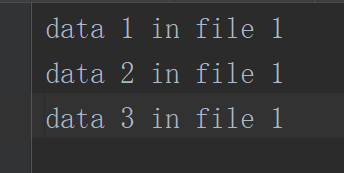
每个文件的数据格式是这样的
那么我们除了用conbiner以外,还有什么效率更高的,所谓更高端的方式来将这些小文件进行合并吗。
下面我们就通过自定义输入,重写FileinputFormat中的方法来完成这个目标。
自定义输入
目录结构:
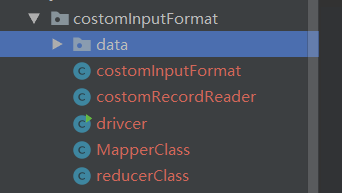
MapperClass
package costomInputFormat;
import org.apache.hadoop.io.BytesWritable;
import org.apache.hadoop.io.NullWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Mapper;
import org.apache.hadoop.mapreduce.lib.input.FileSplit;
import java.io.IOException;
/**
* @Author: Braylon
* @Date: 2020/1/29 10:33
* @Version: 1.0
*/
public class MapperClass extends Mapper<NullWritable, BytesWritable, Text, BytesWritable> {
Text k = new Text();
@Override
protected void setup(Context context) throws IOException, InterruptedException {
FileSplit split = (FileSplit) context.getInputSplit();
String name = split.getPath().getName();
k.set(name);
}
@Override
protected void map(NullWritable key, BytesWritable value, Context context) throws IOException, InterruptedException {
context.write(k, value);
}
}
知识点:
- Map过程的输入和输出
也就是看一下那四个参数类型<NullWritable, BytesWritable, Text, BytesWritable>,
简单来说就是我们输入不再需要偏移量,直接改为了只要文件内容,而BytesWritable就代表文件内容的数据类型。然后我们将文件名作为key(Text)输出,然后文件内同作为value(BytesWritable)。
- map方法啥事情都没做,主要看setup中的逻辑
其实也很简单,就是获取了文件的名字,至于FileSplit我前面的blog中也有讲过和用过,这里不再多说了。
reducerClass
package costomInputFormat;
import org.apache.hadoop.io.BytesWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Reducer;
import java.io.IOException;
/**
* @Author: Braylon
* @Date: 2020/1/29 10:43
* @Version: 1.0
*/
public class reducerClass extends Reducer<Text, BytesWritable, Text, BytesWritable> {
@Override
protected void reduce(Text key, Iterable<BytesWritable> values, Context context) throws IOException, InterruptedException {
super.reduce(key, values, context);
}
}
reduce阶段没有做什么直接跳过。
当然我这里只是演示一下自定义输入,reduce阶段大家可以加自己需要的业务逻辑。
重点:
costomInputFormat:
package costomInputFormat;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.BytesWritable;
import org.apache.hadoop.io.NullWritable;
import org.apache.hadoop.mapreduce.InputSplit;
import org.apache.hadoop.mapreduce.JobContext;
import org.apache.hadoop.mapreduce.RecordReader;
import org.apache.hadoop.mapreduce.TaskAttemptContext;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import java.io.IOException;
/**
* @Author: Braylon
* @Date: 2020/1/29 10:47
* @Version: 1.0
*/
public class costomInputFormat extends FileInputFormat<NullWritable, BytesWritable> {
@Override
protected boolean isSplitable(JobContext context, Path filename) {
return false;
}
@Override
public RecordReader<NullWritable, BytesWritable> createRecordReader(InputSplit inputSplit, TaskAttemptContext taskAttemptContext) throws IOException, InterruptedException {
costomRecordReader costomRecordReader = new costomRecordReader();
costomRecordReader.initialize(inputSplit, taskAttemptContext);
return costomRecordReader;
}
}
自定义就要重写 FileInputFormat方法。
isSplitable是否可分,这个其实没有所谓,看你的数据量和业务要求,我的演示数据很小,没必要分。
createRecordReader方法,这个是关键因为MR流程中inputformat通过recordReader来实现数据的读取的,所以costomRecordreader是我们自定义的类,更是主要的自定义输入的逻辑所在。
costomRecordreader:
package costomInputFormat;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.FSDataInputStream;
import org.apache.hadoop.fs.FileSystem;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.BytesWritable;
import org.apache.hadoop.io.IOUtils;
import org.apache.hadoop.io.NullWritable;
import org.apache.hadoop.mapreduce.InputSplit;
import org.apache.hadoop.mapreduce.RecordReader;
import org.apache.hadoop.mapreduce.TaskAttemptContext;
import org.apache.hadoop.mapreduce.lib.input.FileSplit;
import java.io.IOException;
/**
* @Author: Braylon
* @Date: 2020/1/29 11:02
* @Version: 1.0
*/
public class costomRecordReader extends RecordReader<NullWritable, BytesWritable> {
private Configuration configuration;
private FileSplit fileSplit;
private boolean processed = false;
private BytesWritable value = new BytesWritable();
@Override
public void initialize(InputSplit inputSplit, TaskAttemptContext taskAttemptContext) throws IOException, InterruptedException {
this.fileSplit = (FileSplit) inputSplit;
configuration = taskAttemptContext.getConfiguration();
}
@Override
public boolean nextKeyValue() throws IOException, InterruptedException {
if (!processed) {
byte[] bytes = new byte[(int) fileSplit.getLength()];
FileSystem fs = null;
FSDataInputStream fis = null;
//获取文件系统
Path path =fileSplit.getPath();
fs = path.getFileSystem(configuration);
//读取数据
fis = fs.open(path);
IOUtils.readFully(fis, bytes, 0, bytes.length);
//输出文件内容
value.set(bytes, 0, bytes.length);
IOUtils.closeStream(fis);
processed = true;
return true;
}
return false;
}
@Override
public NullWritable getCurrentKey() throws IOException, InterruptedException {
return NullWritable.get();
}
@Override
public BytesWritable getCurrentValue() throws IOException, InterruptedException {
return value;
}
@Override
public float getProgress() throws IOException, InterruptedException {
return processed ? 1 : 0;
}
@Override
public void close() throws IOException {
}
}
知识点:
-
变量
上面两个变量用于获取配置信息
private Configuration configuration;
private FileSplit fileSplit;
是否处理过,防止重复处理
private boolean processed = false;
创建缓冲区,用于储存value
private BytesWritable value = new BytesWritable(); -
流程
initialize初始化配置信息。
nextKeyValue方法,主要的自定义逻辑,其中当处理完之后,将processed设置为true。
getCurrentKey方法,设置输出的k,v结构
driver
package costomInputFormat;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.BytesWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
import org.apache.hadoop.mapreduce.lib.output.SequenceFileOutputFormat;
import java.io.IOException;
/**
* @Author: Braylon
* @Date: 2020/1/29 11:17
* @Version: 1.0
*/
public class drivcer {
public static void main(String[] args) throws IOException {
args = new String[]{"D:\\idea\\HDFS\\src\\main\\java\\costomInputFormat\\data", "D:\\idea\\HDFS\\src\\main\\java\\costomInputFormat\\out"};
Configuration conf = new Configuration();
Job job = Job.getInstance(conf);
job.setJarByClass(drivcer.class);
job.setMapperClass(MapperClass.class);
job.setReducerClass(reducerClass.class);
job.setInputFormatClass(costomInputFormat.class);
job.setOutputFormatClass(SequenceFileOutputFormat.class);
job.setMapOutputKeyClass(Text.class);
job.setMapOutputValueClass(BytesWritable.class);
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(BytesWritable.class);
FileInputFormat.setInputPaths(job, new Path(args[0]));
FileOutputFormat.setOutputPath(job, new Path(args[1]));
try {
job.waitForCompletion(true);
System.out.println("done");
} catch (InterruptedException e) {
e.printStackTrace();
} catch (ClassNotFoundException e) {
e.printStackTrace();
}
}
}
知识点:
- job.setInputFormatClass(costomInputFormat.class);
job.setOutputFormatClass(SequenceFileOutputFormat.class);
将自定义的类设置为输入类,输出类是hadoop框架中自带的,二进制输出。
欢迎指正
大家共勉~~
