近几年来,深度学习的研究和应用的热潮持续高涨,各种开源深度学习框架层出不穷,包括TensorFlow,Keras,MXNet,PyTorch,CNTK,Theano,Caffe,DeepLearning4,Lasagne,Neon,等等。Google,Microsoft等商业巨头都加入了这场深度学习框架大战,当下最主流的框架当属TensorFlow,Keras,MXNet,PyTorch,接下来我对这四种主流的深度学习框架从几个不同的方面进行简单的对比。
一、 简介
TensorFlow:
TensorFlow是Google Brain基于DistBelief进行研发的第二代人工智能学习系统,其命名来源于本身的运行原理,于2015年11月9日在Apache 2.0开源许可证下发布,并于2017年12月份预发布动态图机制Eager Execution。
Keras:
Keras是一个用Python编写的开源神经网络库,它能够在TensorFlow,CNTK,Theano或MXNet上运行。旨在实现深度神经网络的快速实验,它专注于用户友好,模块化和可扩展性。其主要作者和维护者是Google工程师FrançoisChollet。
MXNet:
MXNet是DMLC(Distributed Machine Learning Community)开发的一款开源的、轻量级、可移植的、灵活的深度学习库,它让用户可以混合使用符号编程模式和指令式编程模式来最大化效率和灵活性,目前已经是AWS官方推荐的深度学习框架。MXNet的很多作者都是中国人,其最大的贡献组织为百度。
PyTorch:
PyTorch是Facebook于2017年1月18日发布的python端的开源的深度学习库,基于Torch。支持动态计算图,提供很好的灵活性。在今年(2018年)五月份的开发者大会上,Facebook宣布实现PyTorch与Caffe2无缝结合的PyTorch1.0版本将马上到来。
有关四个框架的一些基本属性的比较如表1-1所示:
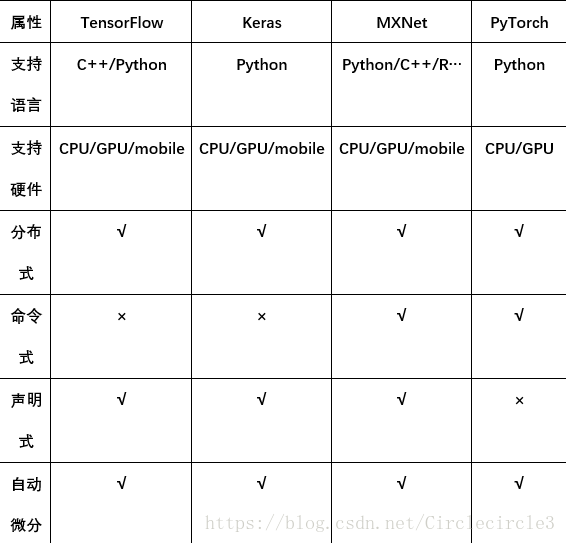
表1-1 各个框架的相关属性
二、 流行度
四个深度学习库均为开源,我们可以通过其在Github上的数据看出他们在行业中的流行程度,截止到2018年6月17日Github上数据如表2-1、表2-2所示。
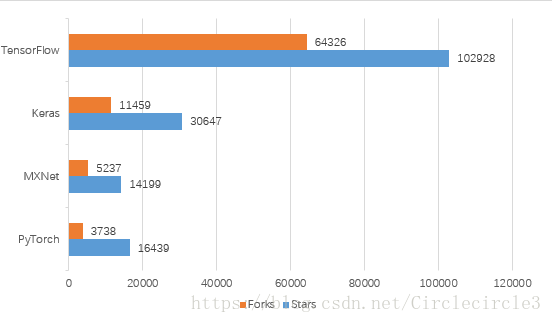
表2-1
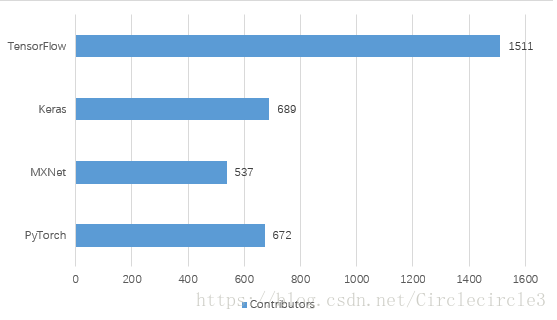
表2-2
三、 灵活性
TensorFlow主要支持静态计算图的形式,计算图的结构比较直观,但是在调试过程中十分复杂与麻烦,一些错误更加难以发。但是2017年底发布了动态图机制Eager Execution,加入对于动态计算图的支持,但是目前依旧采用原有的静态计算图形式为主。TensorFlow拥有TensorBoard应用,可以监控运行过程,可视化计算图。
Keras是基于多个不同框架的高级API,可以快速的进行模型的设计和建立,同时支持序贯和函数式两种设计模型方式,可以快速的将想法变为结果,但是由于高度封装的原因,对于已有模型的修改可能不是那么灵活。
MXNet同时支持命令式和声明式两种编程方式,即同时支持静态计算图和动态计算图,并且具有封装好的训练函数,集灵活与效率于一体,同时已经推出了类似Keras的以MXNet为后端的高级接口Gluon。
PyTorch为动态计算图的典型代表,便于调试,并且高度模块化,搭建模型十分方便,同时具备及其优秀的GPU支持,数据参数在CPU与GPU之间迁移十分灵活
四、 学习难易程度
对于深度学习框架的学习难易程度以及使用的简易度还是比较重要的,我认为应该主要基于框架本身的语言设计、文档的详细程度以及科技社区的规模考虑。对于框架本身的语言设计来讲,TensorFlow是比较不友好的,与Python等语言差距很大,有点像基于一种语言重新定义了一种编程语言,并且在调试的时候比较复杂。每次版本的更新,TensorFlow的各种接口经常会有很大幅度的改变,这也大大增加了对其的学习时间;Keras是一种高级API,基于多种深度学习框架,追求简洁,快速搭建模型,具有完美的训练预测模块,简单上手,并能快速地将所想变现,十分适合入门或者快速实现。但是学习会很快遇到瓶颈,过度的封装导致对于深度学习知识的学习不足以及对于已有神经网络层的改写十分复杂;MXNet同时支持命令式编程和声明式编程,进行了无缝结合,十分灵活,具备完整的训练模块,简单便捷,同时支持多种语言,可以减去学习一门新主语言的时间。上层接口Gluon也极其容易上手;PyTorch支持动态计算图,追求尽量少的封装,代码简洁易读,应用十分灵活,接口沿用Torch,具有很强的易用性,同时可以很好的利用主语言Python的各种优势。对于文档的详细程度,TensorFlow具备十分详尽的官方文档,查找起来十分方便,同时保持很快的更新速度,但是条理不是很清晰,教程众多;Keras由于是对于不同框架的高度封装,官方文档十分详尽,通俗易懂;MXNet发行以来,高速发展,官方文档较为简单,不是十分详细,存在让人十分迷惑的部分,框架也存在一定的不稳定性;PyTorch基于Torch并由Facebook强力支持,具备十分详细条理清晰的官方文档和官方教程。对于社区,庞大的社区可以推动技术的发展并且便利问题的解决,由Google开发并维护的TensorFlow具有最大社区,应用人员团体庞大;Keras由于将问题实现起来简单,吸引了大量研究人员的使用,具有很大的用户社区;MXNet由Amazon,Baidu等巨头支持,以其完美的内存、显存优化吸引了大批用户,DMLC继续进行开发和维护;PyTorch由Facebook支持,并且即将与Caffe2无缝连接,以其灵活、简洁、易用的特点在发布紧一年多的时间内吸引了大量开发者和研究人员,火爆程度依旧在不断攀升,社区也在不断壮大。
五、 性能
为了比较四个框架的性能(主要是运行速度),我进行了三个不同的实验,对于不同的神经网络以及不同类型的数据集在分别在CPU、GPU环境下进行了测试。
CPU环境:Ubuntu14.04 内存 32GB AMD Opteron(tm) Processor 4284
GPU环境1:Ubuntu16.04 内存 32GB Quadro P2000(5GB显存)
Intel(R) Xeon(R) CPU E5-2637 v4 @ 3.50GHz
GPU环境2:Ubuntu16.04 内存 16GB Tesla K40(12GB显存)
Intel(R) Xeon(R) CPU E5-2650 v3 @ 2.30GHz
代码地址:https://github.com/CircleXing001/DL-tools
以下实验时间均为总训练时间,GPU环境下包括数据由内存复制到GPU的时间,不包括数据读入内存所需的时间。
实验一:基于北京pm2.5数据集的多变量时序数据预测问题
数据集:https://archive.ics.uci.edu/ml/datasets/Beijing+PM2.5+Data
模型:简单的单层LSTM+全连接层,如下图所示:

进行训练50epoches,实验结果如表5-1所示:
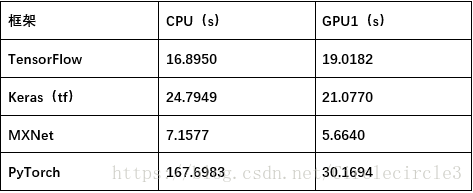
表5-1
实验二:基于Mnist数据集的分类问题
模型:两层卷积神经网络+全连接层,如下图所示:
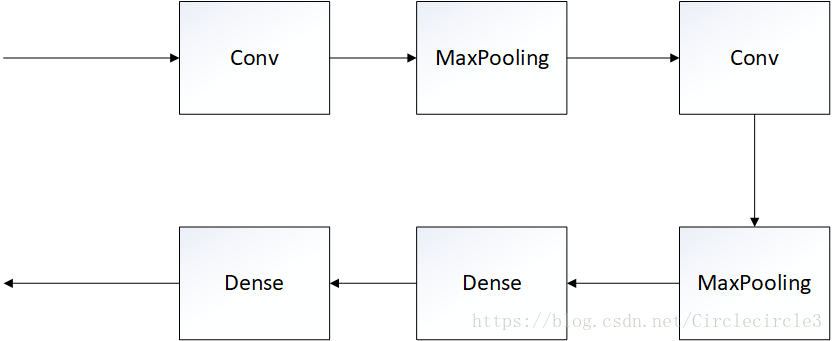
进行训练10epoches,实验结果如表5-2所示:
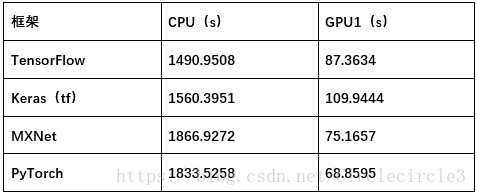
表5-2
实验三:基于DAQUAR数据集的视觉问答问题
数据集:https://www.mpi-inf.mpg.de/departments/computer-vision-and-multimodal-computing/research/vision-and-language/visual-turing-challenge/
模型:卷积神经网络+LSTM,具体如下图所示:

将数据缩放至50*50,进行训练5epoches,实验结果如表5-3所示:
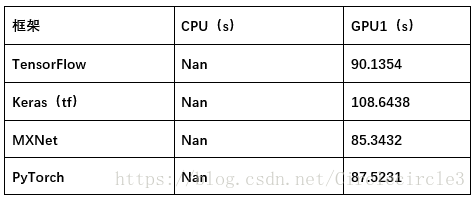
表5-3
在GPU环境2(Ubuntu16.04+内存 16GB +Tesla K40(12GB显存)+
Intel(R) Xeon(R) CPU E5-2650 v3 @ 2.30GHz)
对上述实验三中224*224数据进行实验,对比四种框架对于硬件(GPU)的利用率,结果见表5-4。
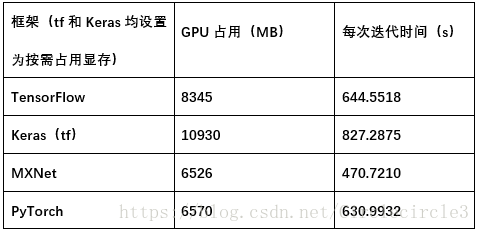
表5-4
通过上述实验我们可以发现,不同的深度学习框架对于计算速度和资源利用率的优化存在一定的差异:Keras为基于其他深度学习框架的高级API,进行高度封装,计算速度最慢且对于资源的利用率最差;在模型复杂,数据集大,参数数量大的情况下,MXNet和PyTorch对于GPU上的计算速度和资源利用的优化十分出色,并且在速度方面MXNet优化处理更加优秀;相比之下,TensorFlow略有逊色,但是对于CPU上的计算加速,TensorFlow表现更加良好。
本文转载自:https://blog.csdn.net/Circlecircle3/article/details/82086396
