RocketMQ
一、RocketMQ基本组成
1、基本组成
在了解Rocket架构之前,我们先了解下RocketMQ中,各个角色分别是干什么的,起到了一个什么作用。
I、NameServer
1、主要用于存储topic,broker的关系,功能类似于zookeeper。
2、NameServer之间互相不通信,支持集群,一个挂掉之后不会影响其他的节点。
3、当Producer和Consumer都获取到Broker的信息后,就算NameServer宕机,也不会影响使用,但是路由信息未注册的,也就是在NameServer宕机之后注册的Producer、Consumer和Broker都是不能够正常工作的。
4、NameServer无状态,NameServer中存储的Broker、Topic的信息并不会持久化的存储,而是动态随Broker的上报而进行改变,虽然NameServer自身支持持久化的配置,但是一般意义不大。
5、Broker向NameServer发送心跳包时,会带上所有的Topic信息,如果Topic的信息量太大,而网络条件却又不太好时,就会导致心跳检测失败,NameServer会误以为Broker已经挂掉。
II、Broker
1、消息容器,接收provider推送的消息,并将对应的消息转发给指定的consumer消费,Broker就相当于时RocketMQ的处理逻辑的服务器。
A、消息顺序写:在消息的写入过程中,所有的Topic共用一个文件,该文件大小为1G,如果文件大小没有满,是不会写入新的文件中的,这样能够保证顺序写盘,提高发消息的TPS;
B、消息跳跃读:MQ读取消息依赖系统PageCache,PageCache命中率越高,读性能越高,Linux平时也会尽量预读数据,使得应用直接访问磁盘的概率降低。
(参见:https://blog.csdn.net/javahongxi/article/details/72956619)
2、负载均衡与动态伸缩
消息是存在queue中的,想要有更大的吞吐量,可以增加queue的数量,也可以增加Broker节点数量。
A、如果Topic的消息量比较大,但是该集群节点的压力并不是很大,可以增加该Topic下面的queue数量,Topic的队列数跟发送、消费速度成正比。
B、如果集群cpu的使用率已经到达85%以上,那么就需要通过增加集群节点来提高吞吐量,现有的节点数量已经无法满足业务需求了。
3、高可用、高可靠
A、高可用:搭建集群,一台服务器宕机并不会影响整体的服务。
B、高可靠:数据不允许丢失,有可靠的持久化机制。
4、心跳机制
心跳机制分为两个方面:
A、Broker每隔30s向NameServer发送心跳包,包含改Broker所有的Topic信息。
B、NameServer查询Broker心跳情况,如果某个Broker在2分钟内没有心跳,则认为该Broker已经宕机。
III、Producer
消息的生产者,一般有业务发起的一端发送MQ消息。
1、Producer Group
一类消费的的集合,一般发送同一类消息,且发送逻辑一致。
2、Producer的心跳机制
A、Producer在启动的时候需要指定NameServer,启动后与NameServer保持长连接,并每隔30s从NameServer获取Topic的队列情况,获取到当前消费Topic和Broker的信息后,与相关的Broker保持长连接。
B、Producer每隔30s向Broker发送心跳包,同时Broker也会每隔10s扫描一次当前的Producer,如果2分钟没有发生心跳,那么认为该Producer已经移除,将会断开连接。
3、Producer生产消息
发送消息是可以选择消息的类型,默认Producer会轮流向Broker发送消息,以达到负载均衡的目的。
(Producer发送的相关知识可以参考这篇博客:https://blog.csdn.net/a1084986263/article/details/81223689)
IV、Consumer
消息的消费者,一般由后台系统异步消费消息。
1、Consumer Group
概念与Producer Group类同。
2、Consumer心跳机制
概念与Producer类同。
3、Consumer消费模式
A、MQPullConsumer:由用户控制线程,主动从服务端获取消息,需要自己维护offset,编程难度较大,不推荐使用。
B、MQPushConsumer:底层同样由pull实现,由用户注册的MessageListener来消费消息,不用自己维护offset。
2、基本架构(来自RocketMQ官网)
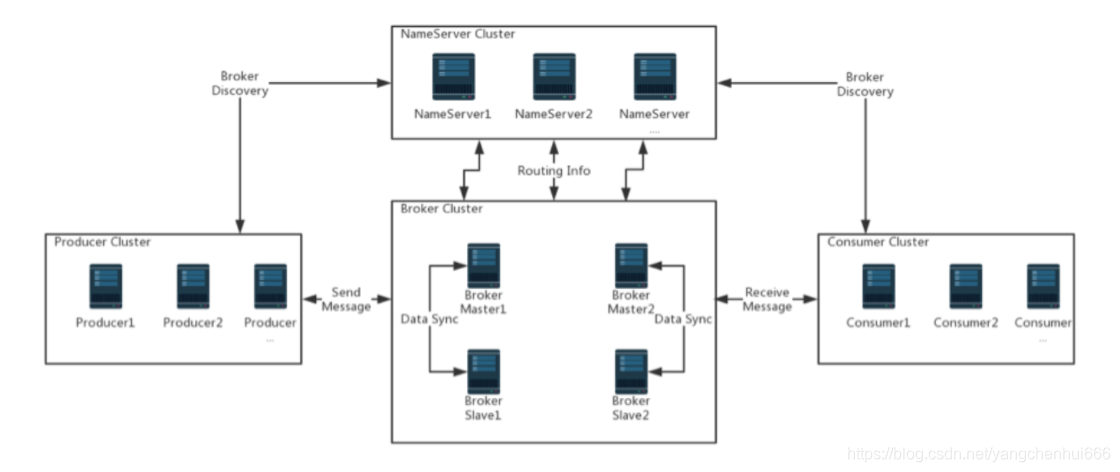
在图中我们可以看到四个角色都可以搭建集群。
Producer和Consumer这个不用多说,可以通过我们业务系统的节点数控制,同时也可以增加Group中的成员数量来控制。
NameServer搭建集群的时候每个节点都会拥有一份完整的信息,所以一个NameServer宕机并不会影响整个系统的工作,同时为了做容灾,我们可以将NameServer的服务器不布在统一地区。
Broker可以可以通过增加Broker的数量来保证系统的吞吐量,同时也可以使用主从模式增加系统的可靠性,具体的配置在RocketMQ的包里面有示例。
二、RocketMQ优化
1、Producer优化
1、一个应用尽可能只用一个 Topic,消息自类型可以用tags来标示,tags可以有应用自由设置,只需要producer和consumer使用一样的即可;
2、发送消息时,尽量设置keys,这样方便定位消息丢失的问题,例如可以使用订单id这样的主键作为消息的keys,因为keys是一种哈希索引,保证keys的唯一行可以在最大程度上避免哈希冲突。
3、如果消息的可靠性要求比较高,可以打印出消息日志进行追踪和定位。
4、如果消息属于同一个tag,同时消息的信息量又比较大,我们可以通过发送批量消息进行处理,提升性能。
5、建议消息大小不超过512K。
6、发送消息有同步和异步两种方式,如果对消息的性能要求比较高,可以使用异步的方式,因为同步发送的方式会阻塞。
7、send发送消息时,不抛异常,就代表发送成功。但是可以定义更加明确的返回状态。

8、对于消息不可丢失的业务,例如转账,必须使用消息重发机制。

具体可参照分布式事务MQ保证一致性的做法,维护一张中间表保证事务的最终一致性。
2、Consumer优化
1、消费组和订阅

2、消息监听器

public class Consumer {
public static final String NAME_SERVER_ADDR = "*.*.*.*:9876";
public static void main(String[] args) throws MQClientException {
// 1. 创建消费者(Push)对象
DefaultMQPushConsumer consumer = new DefaultMQPushConsumer("GROUP_TEST");
// 2. 设置NameServer的地址,如果设置了环境变量NAMESRV_ADDR,可以省略此步
consumer.setNamesrvAddr(NAME_SERVER_ADDR);
// 消费重试次数 -1代表16次
consumer.setMaxReconsumeTimes(-1);
// 3. 订阅对应的主题和Tag
consumer.subscribe("TopicTest", "*");
// 4. 注册消息接收到Broker消息后的处理接口
consumer.registerMessageListener(new MessageListenerConcurrently() {
public ConsumeConcurrentlyStatus consumeMessage(List<MessageExt> list, ConsumeConcurrentlyContext consumeConcurrentlyContext) {
try {
MessageExt messageExt = list.get(0);
System.out.printf("线程:%-25s 接收到新消息 %s --- %s %n", Thread.currentThread().getName(), messageExt.getTags(), new String(messageExt.getBody(), RemotingHelper.DEFAULT_CHARSET));
} catch (UnsupportedEncodingException e) {
e.printStackTrace();
}
return ConsumeConcurrentlyStatus.RECONSUME_LATER;
}
});
// 5. 启动消费者(必须在注册完消息监听器后启动,否则会报错)
consumer.start();
System.out.println("已启动消费者");
}
}
当消息消费失败时,消息的存储方式将会发生改变,当前的消息会变为一个延时消息,默认等级为3,延时时间为10s,并且随着消费失败的次数提升延时消息的等级,设置-1的时候默认尝试重新消费16次。

非顺序消息,如果处理慢,可以自己重新开一个线程,不要阻塞队列,但是如果是顺序消息,开启线程并不能够解决阻塞问题。

3、JVM和Linux配置
1、JVM配置

2、Linux配置

如果不清楚Linux配置和原理,最好保持默认参数。
