使用安装包版本:
spark-2.0.0-bin-hadoop2.6
下载地址 https://spark.apache.org/
Spark概述
Apache Spark是一个快速的通用集群计算系统。它提供Java,Scala,Python和R中的高级API,以及支持常规执行图的优化引擎。
一、安装
1、解压
[root@master app] # tar -zxvf spark-2.0.0-bin-hadoop2.6.tgz -C /usr/local/src/
[root@master app]# cd /usr/local/src/
[root@master src]# ls
anaconda-ks.cfg hbase-1.2.0 mysql zookeeper-3.4.5
apache-hive-1.2.2-bin jdk1.8.0_221 spark-2.0.0-bin-hadoop2.6
hadoop-2.6.0 kafka_2.11-1.0.0 sqoop-1.4.7.bin__hadoop-2.6.0
[root@master src]# cd sqoop-1.4.7.bin__hadoop-2.6.0/
2、环境变量
[root@master conf]# vi ~/.bash_profile
[root@master conf]# source ~/.bash_profile
export LD_LIBRARY_PATH=$HADOOP_HOME/lib/native
export SQOOP_HOME=/usr/local/src/sqoop-1.4.7.bin__hadoop-2.6.0
export PATH=$PATH:$SQOOP_HOME/bin
3、配置spark-env.sh
环境变量
通过环境变量配置确定的Spark设置。环境变量从Spark安装目录下的conf/spark-env.sh脚本读取(或者windows的conf/spark-env.cmd)。在独立的或者Mesos模式下,这个文件可以给机器确定的信息,如主机名。当运行本地应用程序或者提交脚本时,它也起作用。
注意,当Spark安装时,conf/spark-env.sh默认是不存在的。你可以复制conf/spark-env.sh.template创建它。
可以在spark-env.sh中设置如下变量:
[root@master conf]# pwd
/usr/local/src/spark-2.0.0-bin-hadoop2.6/conf
[root@master conf]# cp spark-env.sh.template spark-env.sh
[root@master conf]# vi spark-env.sh
export JAVA_HOME=/usr/local/src/jdk1.8.0_221
# export SCALA_HOME=/usr/etc/scala-2.12.4 # 未安装SCALA
export HADOOP_HOME=/usr/local/src/hadoop-2.6.0
export HADOOP_CONF_DIR=/usr/local/src/hadoop-2.6.0/etc/hadoop
# 本机名 master 在/etc/hosttname映射了自身IP
export SPARK_MASTER_IP=master
export SPARK_HOME=/usr/local/src/spark-2.0.0-bin-hadoop2.6
export SPARK_DIST_CLASSPATH=$(/usr/local/src/hadoop-2.6.0/bin/hadoop classpath)
export LD_LIBRARY_PATH=$HADOOP_HOME/lib/native
变量说明
- JAVA_HOME:Java安装目录
- SCALA_HOME:Scala安装目录
- HADOOP_HOME:hadoop安装目录
- HADOOP_CONF_DIR:hadoop集群的配置文件的目录
- SPARK_MASTER_IP:spark集群的Master节点的ip地址
- SPARK_WORKER_MEMORY:每个worker节点能够最大分配给exectors的内存大小
- SPARK_WORKER_CORES:每个worker节点所占有的CPU核数目
- SPARK_WORKER_INSTANCES:每台机器上开启的worker节点的数目
4、添加配置项到spark-default.conf
按需调整,增加运算速度,合理资源调度
[root@master conf]# pwd
/usr/local/src/spark-2.0.0-bin-hadoop2.6/conf
[root@master conf]# cp spark-defaults.conf.template spark-defaults.conf
[root@master conf]# vi spark-defaults.conf
spark.eventLog.enabled true
spark.eventLog.dir hdfs://master:9000/Spark/historyserverforSpark
spark.yarn.historyServer.address master:18080
spark.history.fs.logDirectory hdfs://master:9000/Spark/historyserverforSpark
spark.executor.extraJavaOptions -XX:+PrintGCDetails -Dkey=value -Dnumbers="one two three"
参数说明 http://spark.apache.org/docs/1.6.1/configuration.html
5、 在hdfs上创建文件
[root@master jars]# hdfs dfs -mkdir /Spark/
[root@master jars]# hdfs dfs -mkdir /Spark/historyserverforSpark
6、配置slaves
[root@master conf]# cp slaves.template slaves
[root@master conf]# vi slaves
# A Spark Worker will be started on each of the machines listed below.
slave1
slave2
7、删除spark的slf4Jar包,因为hadoop有这个Jar包了
[root@master jars]# pwd
/usr/local/src/spark-2.0.0-bin-hadoop2.6/jars
[root@master conf]# rm slf4j-log4j12-1.7.16.jar
8、scp
[root@master conf]# scp ~/.bash_profile slave1:~/.bash_profile
[root@master conf]# scp ~/.bash_profile slave2:~/.bash_profile
[root@master conf]# scp -r /usr/local/src/spark-2.0.0-bin-hadoop2.6/ slave1:/usr/local/src
[root@master conf]# scp -r /usr/local/src/spark-2.0.0-bin-hadoop2.6/ slave2:/usr/local/src
二、启动Spark集群
1、启动hadoop的HDFS文件系统
因为我们只需要使用hadoop的HDFS文件系统,所以我们并不用把hadoop全部功能都启动。
[root@master conf]# start-dfs.sh
[root@master conf]# jps
2418 Jps
2166 JournalNode
1959 DataNode
1849 NameNode
2361 DFSZKFailoverController
[root@master conf]#
2、启动Spark,
因为hadoop/sbin以及spark/sbin均配置到了系统的环境中,它们同一个文件夹下存在同样的start-all.sh文件。最好是打开spark-2.2.0,在文件夹下面打开该文件。这个可以改名然后加入环境变量
./sbin/start-all.sh
[root@master spark-2.0.0-bin-hadoop2.6]# cd sbin/
[root@master sbin]# ls
slaves.sh start-mesos-shuffle-service.sh stop-mesos-dispatcher.sh
spark-config.sh start-shuffle-service.sh stop-mesos-shuffle-service.sh
spark-daemon.sh start-slave.sh stop-shuffle-service.sh
spark-daemons.sh start-slaves.sh stop-slave.sh
start-all.sh start-thriftserver.sh stop-slaves.sh
start-history-server.sh stop-all.sh stop-thriftserver.sh
start-master.sh stop-history-server.sh
start-mesos-dispatcher.sh stop-master.sh
[root@master sbin]# pwd
/usr/local/src/spark-2.0.0-bin-hadoop2.6/sbin
[root@master sbin]# ./start-all.sh
[root@master sbin]# jps
2483 Master
2166 JournalNode
1959 DataNode
1849 NameNode
2361 DFSZKFailoverController
2589 Jps
出现 Master 验证成功
3、打开 slave1 slave2
[root@slave1 ~]# jps
3250 Jps
1875 JournalNode
1780 DataNode
3160 Worker
2473 QuorumPeerMain
2634 DFSZKFailoverController
2957 NameNode
[root@slave2 ~]# jps
2096 QuorumPeerMain
1717 DataNode
2504 Jps
2413 Worker
[root@slave2 ~]#
出现 Worker 验证成功
4、打开spark
[root@master sbin]# spark-shell
Welcome to
____ __
/ __/__ ___ _____/ /__
_\ \/ _ \/ _ `/ __/ '_/
/___/ .__/\_,_/_/ /_/\_\ version 2.0.0
/_/
Using Scala version 2.11.8 (Java HotSpot(TM) 64-Bit Server VM, Java 1.8.0_221)
Type in expressions to have them evaluated.
Type :help for more information.
scala>
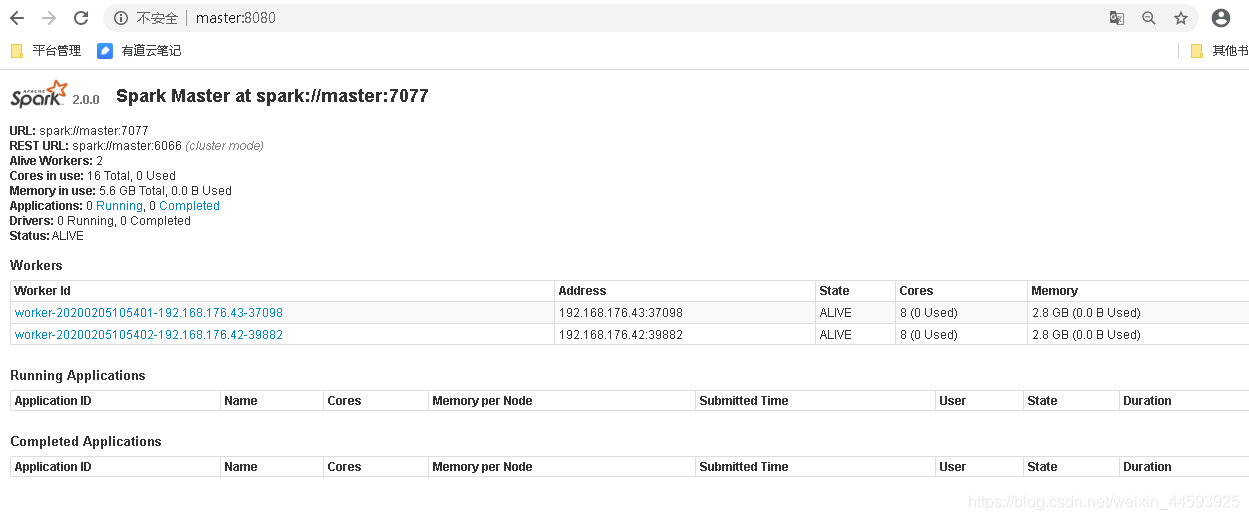
5、打开 master:8080