一、准备工作
1.安装centos 6.5
2.安装 jdk 1.8.x
3.配置三台机器之间的ssh通信
4.安装hadoop2.7.x以上的版本
以上步骤在已经配置,本文不再多说。
https://blog.csdn.net/yangang1223/article/details/79883113
二、安装spark
依旧是三台机器:
master:192.168.163.145
worker1:192.168.163.146
worker2:192.168.163.147
1.spark是scala语言开发,依赖于scala,所以在这之前我们先装scala
本文选择scala 2.11.8
在spark官网和scala官网或清华大学镜像站下载
本文使用spark-2.2.0-bin-hadoop2.7.tgz进行安装,如果是生产环境也可以下载源码包进行编译。
$tar -zxvf spark-2.1.1-bin-hadoop2.7.tgz
$tar -zxvf scala-2.11.8.tgz
$mv spark-2.1.1-bin-hadoop2.7 spark-2.1.1
$mkdir scala
$mv scala-2.11.8 scala

$vim ~/.bash_profile加入SCALA_HOME和SPARK_HOME,以及bin和sbin目录
JAVA_HOME=/app/java/jdk1.8.0_141
HADOOP_HOME=/app/hadoop/hadoop-2.7.3
SCALA_HOME=/app/scala/scala-2.11.8
SPARK_HOME=/app/spark/spark-2.1.1
PATH=$PATH:$HOME/bin:$JAVA_HOME/bin:$HADOOP_HOME/bin:$HADOOP_HOME/sbin:$SCALA_HOME/bin:$SPARK_HOME/bin:$SPARK_HOME/sbin

保存退出
$ source ~/.bash_profile
查看scala版本

2.进入spark根目录的conf目录,配合slaves配置文件
cp slaves.template slaves 复制一份样本文件 打开

说明:slaves文件里面写三个集群的主机名意味着三个节点都会有worker节点计算,你也可以不写master节点,让worker运行在worker1和worker2上

配置spark-env.sh,几个home比较重要后面的可以不做配置,默认就是。
export JAVA_HOME=/app/java/jdk1.8.0_141
export HADOOP_HOME=/app/hadoop/hadoop-2.7.3
export SCALA_HOME=/app/scala/scala-2.11.8
export SPARK_HOME=/app/spark/spark-2.1.1
export HADOOP_CONF_DIR=/app/hadoop/hadoop-2.7.3/etc/hadoop
export SPARK_DIST_CLASSPATH=$($HADOOP_HOME/bin/hadoop classpath)
export SPARK_MASTER_IP=master
export SPARK_MASTER_PORT=7077
export SPARK_EXECUTOR_INSTANCES=1
export SPARK_WORKER_INSTANCES=1
export SPARK_WORKER_CORES=1
export SPARK_WORKER_MEMORY=1024M
export SPARK_MASTER_WEBUI_PORT=8080
export SPARK_CONF_DIR=$SPARK_HOME/conf
3.至此master节点spark配置完成,现在将spark和scala分发到worker1和worker2上
[hadoop@master app]$ scp -r spark hadoop@worker1:/app/
[hadoop@master app]$ scp -r spark hadoop@worker2:/app/
[hadoop@master app]$ scp -r spark hadoop@worker1:/app/
[hadoop@master app]$ scp -r spark hadoop@worker2:/app/
将master节点的环境变量配置也分发过去
[hadoop@master app]$ scp ~/.bash_profile hadoop@worker1:~/
[hadoop@master app]$ scp ~/.bash_profile hadoop@worker2:~/
进入master节点的sbin目录
./start-all.sh或者分开启动./start-master.sh start 、./start-slaves.sh start
[hadoop@master sbin]$ ./start-all.sh

查看worker1、worker2节点的jps
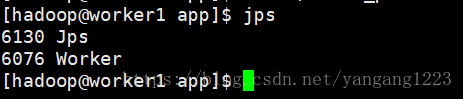
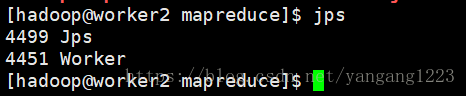
4.在浏览器输入192.168.163.145:8080

至此spark集群配置完成。