谱聚类算法
谱聚类【全称:Spectral Clustering】,是一种基于图切割的、有别于 KMeans 算法的无监督学习算法,它同样也使用了距离,但不需要指定 K 。以样本及样本间的距离构造一个图,根据指定的距离阀值初步切割图,形成若干个独立的子图,这些子图的含义与 KMeans 的簇相同,就是一个独立的分类。
涉及的矩阵知识
1. 余子式
也是一个行列式,是去掉 i 行 j 列后的一个行列式 Mij 称为元素 aij 的余子式。
2.代数余子式
对于元素 aij,用 (-1 ) 的 (i+j) 次方,乘以其余子式 Mij ,叫做元素 aij 的代数余子式:
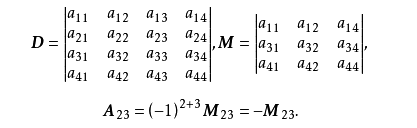
即:
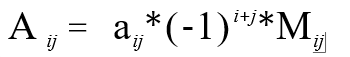
3.矩阵行列式
矩阵计算中的 det(A):矩阵 A 的行列式 determinant,取值是一个标量,记作 det(A) 或者 |A| 。矩阵 A 的行列式,等于其任意一行的每个元素与其对应的代数余子式的乘积之和。按行计算行列式公式为:
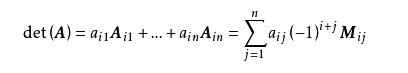
某一列进行计算,其公式为:

4.矩阵行列式定理
- 第一条,det(A)=det(A的转置),推理依据是行列式的定义。
- 第二条,如果方阵 A 有一列或者一行的元素全为 0 ,那么它的行列式为 0 ,取该行求解时,0*Mij 累加和为 0。
- 第三条,如果方阵 A 有两行或者两列元素相等,那么它的行列式为 0 。推理依据为代数余子式分解后的结果,如果有相同行或列,最终形成的特征多项式叠加时正好两个相同元素的乘积一正一负值,抵消为 0 了,最终整个行列式值为 0 了。
5.行列式的现实意义
行列式中的行或列向量所构成的超平行多面体的有向面积或有向体积。
6.矩阵特征值和特征向量
同济大学工程数学线性代数对特征值和特征向量的定义为:
设 A 是 n 阶方阵,如果数 λ 和 n 维非零列向量 x 使关系式 Ax=λx 成立,那么这样的数 λ 称为矩阵 A 的特征值,非零向量 x 称为 A 的对应于特征值 λ 的特征向量。
式 Ax=λx 也可写成 ( A-λE)X=0 。这是 n 个未知数 n 个方程的齐次线性方程组,它有非零解的充分必要条件是系数行列式 | A-λE|=0。
先求该行列式确定所有特征值 λ,再针对每个特征值求对应的特征向量,图切割时依据的就是第二小特征值对应的特征向量。
7.矩阵的秩
矩阵的行或列数最小的值
8.矩阵的迹
一个 NxN 的方阵 A ,其正对角线上所有元素 aii (i=1,2…N)的和称为矩阵 A 的迹,记作 tr(A)。
9.矩阵的谱半径
矩阵 A 的谱半径等于矩阵 A 的特征值的模的最大值。
图切割流程
以样本为点,、本间的距离为边,构造一个初始的大图,然后对图进行分割,直到找到一种合理的分割,使得原来的大图变成若干连通的子图,每个子图即为一个分类簇,具体流程如下:

权重矩阵 W 的构造方法
初始时,构造谱聚无向权重图的方法,图的边为权重 wij,代表两个节点 Vi 和 Vj 之间的相似度,值越小,相似度越低,距离越远;反之,距离越近。常用的构建权重矩阵的方法是用高斯函数:
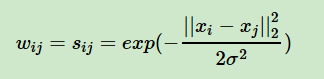
找到一篇对谱聚类算法原理解析的比较清楚的文章,参考资料
谱聚类原理
1.拉普拉斯矩阵特性
图切割第三步得到的一个拉普拉斯矩阵 L=D-W ,它对任意一个列向量 f (nx1),可以做如下计算(f 的 转置和 L):
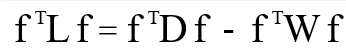
根据前面的定义,左侧三个矩阵计算后得到一个 1X1 的矩阵,第一部分推导过程为:

第二部分推导过程(将裁开的求和,简写得到一个双重求和公式):

合并后,利用多项式的技巧,等价转换得到一个差的平方:

RatioCut
1、基本概念
1.1 所有样本的集合记作 V
1.2 对各个样本归队,得到 K 个 V 的子集合 {A1,A2…Ak}
1.3 所有子集合之间连接边的权重之和,记作 Cut(A1,A2…Ak)
(为什么除以 2,因为算了两遍)
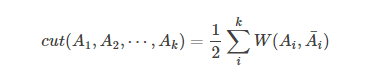
1.4 某个子集 Ai 与其他子集之间的连边权重和为 W(Ai,Ai 补),等于:
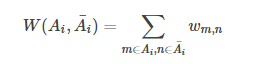
2、切图的目标
使得每个子图内部结构尽量相似,即权重较大;子图之间的尽可能相异,即权重较小。则目标函数就是使得 Cut(A1,…Ak) 尽可能小,而且要避免拆成单点的集合,故需考虑子图内节点个数尽可能多。引入两种切图函数,第一种 Ratio 考虑图内节点数;第二种考虑子图内的权重和。

最终转换为对目标函数的极小化求解问题。
3、每个切图的指示向量 hj
对于每个切图 Aj,引入它的指示向量 hj,它是一个 n (样本总数)行的一维列向量。
3.1 引入某个切图 Aj 的指示向量 hj,定义为:

每个切图 Aj ,它的指示向量的各个元素 hji 的值只有两个选项,非0 即 另外一个。代表样本中每个样本对当前切图的指示结果,非0 ,即指向该图的样本。
3.2 拉普拉斯矩阵计算 h的倒置 L h = 将矩阵乘法化为元素连加求和形式,得到一个双重求和公式:

切图定义转换为 htLh 的过程
谱聚类的巧妙之处是将目标函数切图 RatioCut(A1,A2…Ak) 转换为拉普拉斯矩阵和特征向量 hi 的乘法结果的求和公式,其转换过程如下:

根据切图的定义,各个子图的权重求和后乘以系数 ,最终结果中消掉了系数,该算法原论文中是没有系数的,可能是因为系数对最终的优化没有影响。这个推导过程旨在说明谱聚类切图的最终目标转换为求解拉帕拉斯矩阵 L 的前 k 小的特征值及其特征向量组成的矩阵 H 。
算法相关的点
阅读了网友刘建平前辈关于 谱聚类算法原理 的文章,并看完了该文章所有的评论,还看了很多相关的网络文章后,反问自己,真正理解了谱聚类算法了吗?理解了几分?怎么用此算法解决实际问题呢?令人沮丧的是,貌似还是没有透彻理解。下载并打印了谱聚类那篇论文原文,有空还要继续看看。
据目前的理解,罗列该算法的一些理论要点如下:
- 谱聚类算法名称的由来,为什么叫谱聚类?【基于矩阵的谱半径的算法】
- 构造权重矩阵 W 的三种方式
- 拉帕拉斯矩阵针对任何向量 f 的计算结果的推导
- 两个子图 A、B 间的权重定义
- 针对所有子图 A1…Ak ,切图权重和的定义
- 切图的两次降维:先到 k1 类,在使用 KMeans 聚类到 k2 类
- 指示向量 hi 的定义函数
- 通过对 L 求解前 k 小的 特征向量后得到的特征向量构成的特征矩阵 H 跟 hi 定义的向量之间的关系?【是一种相似的解?】
- 得到的 H 再按行标准化的物理意义【权重的考虑】
- 按指示向量的定义可能出现的解的规模 【NP 问题】
- RatioCut 和 NCut 的考量因素【前者是节点个数最大,后者是子图内的权重最大】
参考资源
搞清楚算法,需要搜索一些文章,它们之间相互补充,才有机会搞清楚整个算法原理,学习参考资料如下:
