OS:Ubuntu 16.04
Framework:darknet
Dataset Format:VOC
零、来看看官网的简介
Darknet: Open Source Neural Networks in C.
Darknet is an open source neural network framework written in C and CUDA. It is fast, easy to install, and supports CPU and GPU computation. You can find the source on GitHub .
一、安装darknet
- 下载darknet库
git clone https://github.com/pjreddie/darknet.git
这条命令是下载到当前目录的,所以下载前要选择好目录。
- 修改编译文件Makefile
Makefile在darknet根目录
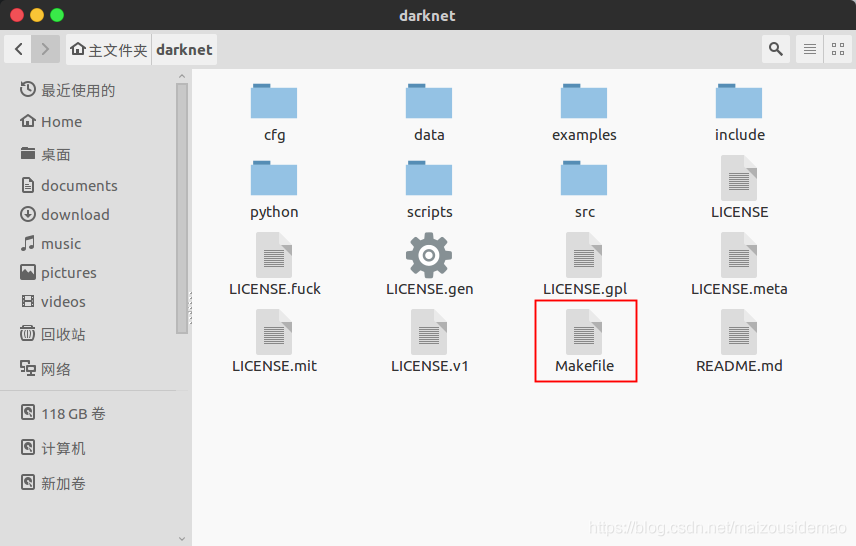
修改说明:
GPU=0 # 是否使用GPU,0则使用CPU
CUDNN=0 # 是否使用CUDNN
OPENCV=0 # 是否使用OpenCV
OPENMP=1 # 是否开启OPENMP
DEBUG=0
- 编译
每次修改都要重新编译
cd darknet # 进入到darknet根目录
make
编译结束

至此,darknet安装完成。
二、准备卷基层预训练权重
- 下载权重
下载链接 - 放置权重文件并记录位置
找一个目录存放该文件,并记录路径。
官网显示存放在了darknet根目录,感觉还是找个文件夹的好,我在darknet下新建了一个weights。
三、准备数据集
自己的数据集是要标准化才能输入神经网络的,比如图片大小等,这一步我们用Python脚本来完成,darknet已经为我们准备好了Python脚本,在scripts里,voc_label.py就是。
下面是voc_label.py的初始状态,后面我们还要对其修改。
import xml.etree.ElementTree as ET
import pickle
import os
from os import listdir, getcwd
from os.path import join
sets=[('2012', 'train'), ('2012', 'val'), ('2007', 'train'), ('2007', 'val'), ('2007', 'test')]
classes = ["aeroplane", "bicycle", "bird", "boat", "bottle", "bus", "car", "cat", "chair", "cow", "diningtable", "dog", "horse", "motorbike", "person", "pottedplant", "sheep", "sofa", "train", "tvmonitor"]
def convert(size, box):
dw = 1./(size[0])
dh = 1./(size[1])
x = (box[0] + box[1])/2.0 - 1
y = (box[2] + box[3])/2.0 - 1
w = box[1] - box[0]
h = box[3] - box[2]
x = x*dw
w = w*dw
y = y*dh
h = h*dh
return (x,y,w,h)
def convert_annotation(year, image_id):
in_file = open('VOCdevkit/VOC%s/Annotations/%s.xml'%(year, image_id))
out_file = open('VOCdevkit/VOC%s/labels/%s.txt'%(year, image_id), 'w')
tree=ET.parse(in_file)
root = tree.getroot()
size = root.find('size')
w = int(size.find('width').text)
h = int(size.find('height').text)
for obj in root.iter('object'):
difficult = obj.find('difficult').text
cls = obj.find('name').text
if cls not in classes or int(difficult)==1:
continue
cls_id = classes.index(cls)
xmlbox = obj.find('bndbox')
b = (float(xmlbox.find('xmin').text), float(xmlbox.find('xmax').text), float(xmlbox.find('ymin').text), float(xmlbox.find('ymax').text))
bb = convert((w,h), b)
out_file.write(str(cls_id) + " " + " ".join([str(a) for a in bb]) + '\n')
wd = getcwd()
for year, image_set in sets:
if not os.path.exists('VOCdevkit/VOC%s/labels/'%(year)):
os.makedirs('VOCdevkit/VOC%s/labels/'%(year))
image_ids = open('VOCdevkit/VOC%s/ImageSets/Main/%s.txt'%(year, image_set)).read().strip().split()
list_file = open('%s_%s.txt'%(year, image_set), 'w')
for image_id in image_ids:
list_file.write('%s/VOCdevkit/VOC%s/JPEGImages/%s.jpg\n'%(wd, year, image_id))
convert_annotation(year, image_id)
list_file.close()
os.system("cat 2007_train.txt 2007_val.txt 2012_train.txt 2012_val.txt > train.txt")
os.system("cat 2007_train.txt 2007_val.txt 2007_test.txt 2012_train.txt 2012_val.txt > train.all.txt")
可以看到voc_label.py有对文件操作的语句,我们按照这个目录创建文件夹,这个目录结构也是VOC2007的标准结构。
- 采用VOC格式的数据集,建立VOC数据集目录结构
注意该目录结构要和voc_label.py在同一目录,即都在scripts下!!!
目录结构如下:
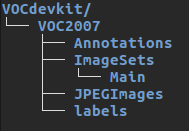
可以通过以下命令快速创建:
# 注意此命令是在scripts目录下执行的,位于其他目录自行修改
mkdir -p VOCdevkit/VOC2007/{Annotations,ImageSets/Main,JPEGImages,labels}
几个文件夹的作用:
Annotations:存放VOC数据集的xml文件
ImageSets/Main:存放训练集train.txt、验证集val.txt和测试集test.txt
JPEGImages:存放训练集、验证集和测试集对应的图片们
labels:将来运行voc_label.py后,生成的训练集、验证集和测试集的各样本的标签信息会自动存放到这里
- 按照上面说明将文件放到指定位置
Annotations目录:

ImageSets/Main目录:
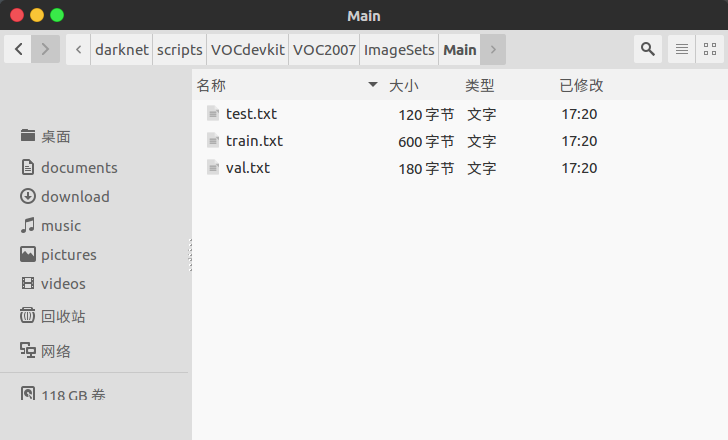
其中train.txt的内容为:
图片文件的名字 ( 不包括扩展名 ) ,一行对应一张图片

val.txt的内容为:

test.txt的内容为:

JPEGImages目录(所有图片都放在这里):
- 修改voc_label.py(位于darknet/scripts下)
修改说明:
# -*- coding: utf-8 -*-
import xml.etree.ElementTree as ET
import pickle
import os
from os import listdir, getcwd
from os.path import join
# 数据集名称,对应darknet/scripts/VOCdevkit/VOC2007/ImageSets/Main中的文件名,数字是VOC版本
sets = [('2007', 'train'), ('2007', 'val'), ('2007', 'test')]
# 类别名称
classes = ["l"]
def convert(size, box):
dw = 1./(size[0])
dh = 1./(size[1])
x = (box[0] + box[1])/2.0 - 1
y = (box[2] + box[3])/2.0 - 1
w = box[1] - box[0]
h = box[3] - box[2]
x = x*dw
w = w*dw
y = y*dh
h = h*dh
return (x, y, w, h)
def convert_annotation(year, image_id):
# 数据集在这个目录,以下有4处目录需要检查是否正确
in_file = open('VOCdevkit/VOC%s/Annotations/%s.xml' %
(year, image_id)) # .xml文件
out_file = open('VOCdevkit/VOC%s/labels/%s.txt' %
(year, image_id), 'w') # 检查是否有labels
tree = ET.parse(in_file)
root = tree.getroot()
size = root.find('size')
w = int(size.find('width').text)
h = int(size.find('height').text)
for obj in root.iter('object'):
difficult = obj.find('difficult').text
cls = obj.find('name').text
if cls not in classes or int(difficult) == 1:
continue
cls_id = classes.index(cls)
xmlbox = obj.find('bndbox')
b = (float(xmlbox.find('xmin').text), float(xmlbox.find('xmax').text), float(
xmlbox.find('ymin').text), float(xmlbox.find('ymax').text))
bb = convert((w, h), b)
out_file.write(str(cls_id) + " " +
" ".join([str(a) for a in bb]) + '\n')
wd = getcwd()
for year, image_set in sets:
if not os.path.exists('VOCdevkit/VOC%s/labels/' % (year)):
os.makedirs('VOCdevkit/VOC%s/labels/' % (year)) # 此处不用修改,会自动创建
image_ids = open('VOCdevkit/VOC%s/ImageSets/Main/%s.txt' %
(year, image_set)).read().strip().split() # .txt文件
list_file = open('%s_%s.txt' % (year, image_set), 'w')
for image_id in image_ids:
list_file.write('%s/VOCdevkit/VOC%s/JPEGImages/%s.jpg\n' %
(wd, year, image_id)) # 图片文件
convert_annotation(year, image_id)
list_file.close()
# 与前面第9行的sets对应,但只有训练集和验证集
os.system("cat 2007_train.txt 2007_val.txt > train.txt")
os.system("cat 2007_train.txt 2007_val.txt 2007_test.txt > train.all.txt") # 所有的数据集
- 执行voc_label.py(与VOCdevkit在同一目录)
python voc_label.py
执行成功后,多了几个东西:
a. 在darknet/scripts下
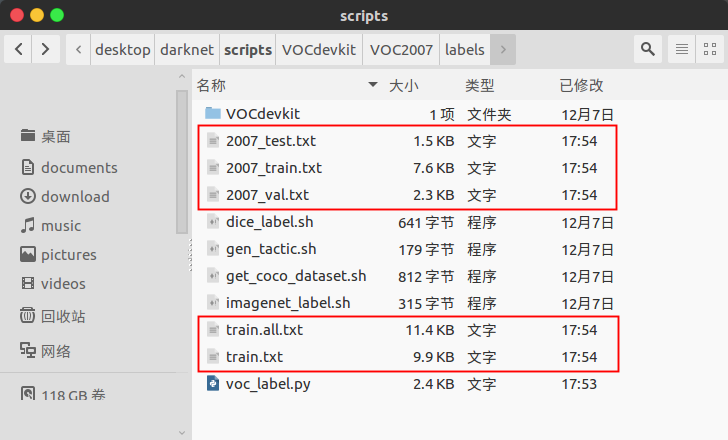
2007_test.txt、2007_train.txt和2007_val.txt分别存放相应数据集的图片路径,如下:

b. 在darknet/scripts/VOCdevkit/VOC2007/labels目录下
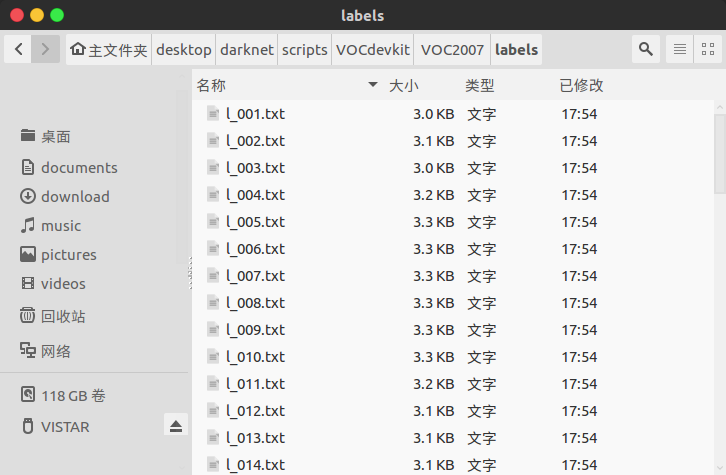
多了些txt文件,这就是前面说的训练集、验证集和测试集各样本的标签信息,打开看一下
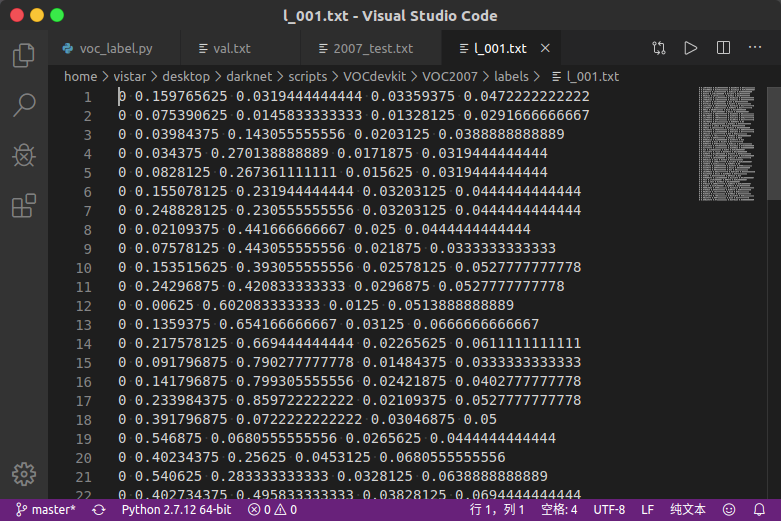
每行有5个数,分别为类别编号(即voc_label.py文件中classes列表的元素索引值)、标签中心坐标和标签宽高,坐标和宽高均为归一化的值,具体可以查看voc_label.py文件里的convert()函数。
四、修改cfg文件
修改darknet/cfg下的yolov3-voc.cfg
-
修改batch和subdivisions
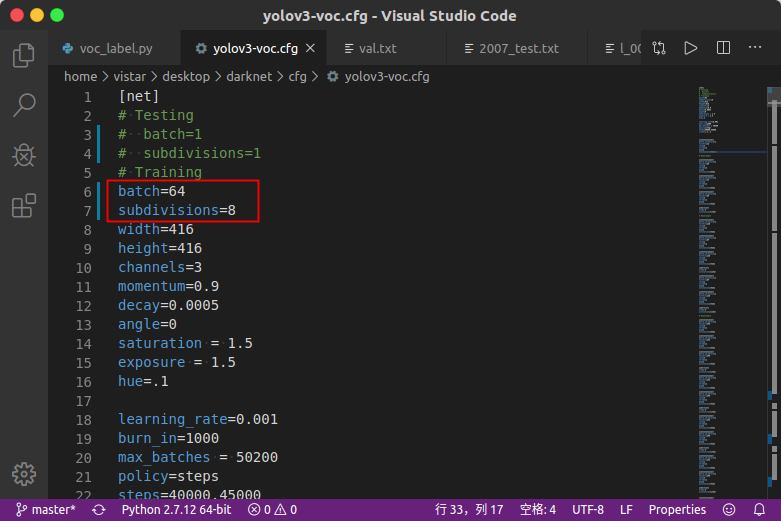
batch表示一次性加载多少图片进内存,subdivisions表示分多少次完成前向传播。 -
修改classes和filters

classes表示识别类别的数量,filters = (classes + 5) * 3
共有三处,都得修改
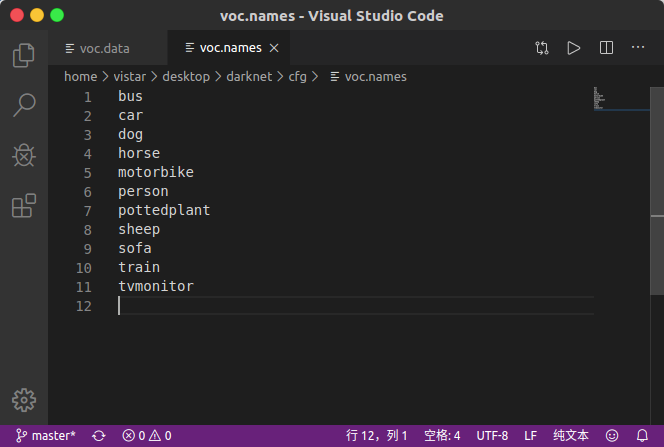
五、创建自己的voc.names
在darknet/cfg下创建voc.names文件,并将自己的类别名称写入,每行一个类别
六、修改voc.data
在darknet/cfg下,修改为:
classes = 1 # 类别数
train = scripts/2007_train.txt # 运行voc_label.py生成的文件,存放训练集图片路径
valid = scripts/2007_val.txt # 运行voc_label.py生成的文件,存放验证集图片路径
names = voc.names # 上一步修改的文件,存放类别名
backup = backup # 训练结束时,存放权重的位置
七、开始训练
在darknet的根目录打开终端,并输入;
./darknet detector train cfg/voc.data cfg/yolov3-voc.cfg weights/darknet53.conv.74
说明:
./darknet —— 编译时生成的可执行文件
detector —— 要执行任务的模型
train —— 进行的任务
cfg/voc.data —— 第六步修改的文件
cfg/yolov3-voc.cfg —— 第四步修改的文件
weights/darknet53.conv.74 —— 第二步下载的权重
参考:
https://pjreddie.com/darknet/
https://www.cnblogs.com/pprp/p/9525508.html
https://segmentfault.com/a/1190000017773610
https://blog.csdn.net/qq_38451119/article/details/83313857#commentsedit
