1,背诵单词:unjust:不公平的 tiny:极小的 strict:严格的 translation:翻译 steal:偷 thumb:拇指 summary:总结 tennis:网球运动 tax:税金 turkey:火鸡 sweat:流汗 statement:声明 sprinkle:洒 tramp:流浪汉 yard:院子 distribution:分配 wreck:残骸 dismiss:解雇 interpreter:解释着
2,做spark实验1到实验3,回顾了之前学习的scala语法等
1.1 Spark Streaming是什么
Spark Streaming用于流式数据的处理。Spark Streaming支持的数据输入源很多,例如:Kafka、Flume、Twitter、ZeroMQ和简单的TCP套接字等等。数据输入后可以用Spark的高度抽象原语如:map、reduce、join、window等进行运算。而结果也能保存在很多地方,如HDFS,数据库等。
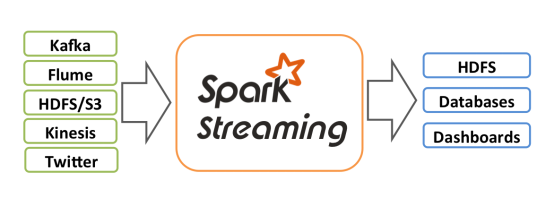
和Spark基于RDD的概念很相似,Spark Streaming使用离散化流(discretized stream)作为抽象表示,叫作DStream。DStream 是随时间推移而收到的数据的序列。在内部,每个时间区间收到的数据都作为 RDD 存在,而DStream是由这些RDD所组成的序列(因此得名“离散化”)。
1.2 Spark Streaming特点
1.易用

2.容错
3.易整合到Spark体系
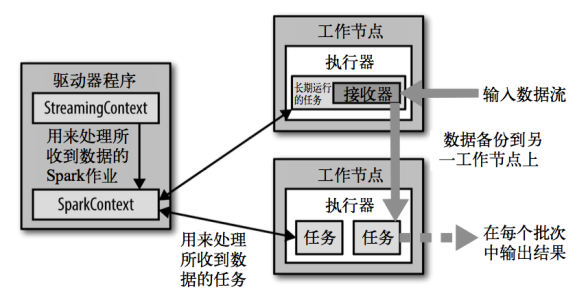
1.3 SparkStreaming架构
3,遇到的问题:
4,明天计划:学习spark和做实验