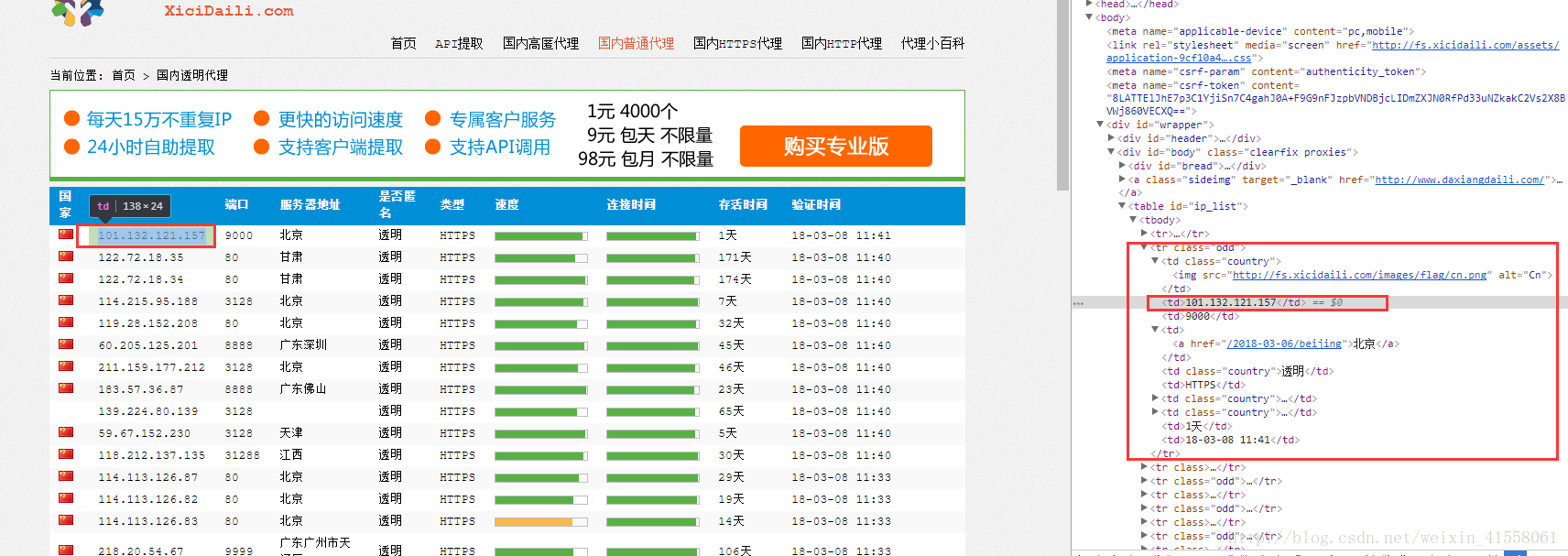
先上码————
#! usr/bin/env python3
# -*- coding:utf-8 -*-
__author__ = 'Lilu'
import os
import re
from bs4 import BeautifulSoup
from html.parser import HTMLParser
from urllib import request
import pandas
import mysql.connector
from datetime import datetime
import urllib.request
import PIL
import time
#用百度首页来进行测试
def _is_alive(p):
header = {
'User-Agent': 'Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML,'
' like Gecko) Chrome/50.0.2661.94 Safari/537.36'}
testurl = 'https://www.baidu.com/'
try:
resp = 0
# 每一个测试3次
for i in range(3):
proxy_support = urllib.request.ProxyHandler({'http': p})
opener = request.build_opener(proxy_support)
urllib.request.install_opener(opener)
req = request.Request(testurl, headers=header)
# 获取状态码
resp = request.urlopen(req, timeout=5).code
print(resp, '`````````````')
if resp == 200:
return True
except:
print('fail ')
return False
#过滤掉不可用的ip
def testIp(pool):
# 创建一个新容器
poolIp = []
# 标识
num = 0
# 标识
numm = 0
for p in pool:
# 为true就存入新容器,false就从pool删除掉
if _is_alive(p):
print(i)
poolIp.append(p)
num += 1
continue
else:
pool.remove(p)
numm -= 1
print(numm)
try:
# 要存入的文件地址
fp = open("C:/Users/Administrator/Desktop/pythonTest/xici/test.txt", 'w+')
# 遍历可用的ip
for item in poolIp:
# 依次写入并换行
fp.write(str(item) + "\n")
# 关闭容器
fp.close()
except IOError:
print('fail l')
#获取西祠代理ip
def XiciAgent(url):
header = {
'User-Agent': 'Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML,'
' like Gecko) Chrome/50.0.2661.94 Safari/537.36'}
req = urllib.request.Request(url, headers=header)
res = urllib.request.urlopen(req)
# 根据URL读取出当首页-_-全是ip 就是不晓得哪些可用哪些不可用
data_all = res.read()
# 把读取的HTML解析成可选择模式
test = BeautifulSoup(data_all, 'lxml')
# 获取到文中的所有tr
tr = test.findAll('tr')
# 准备容器-存放ip
pool = []
# ip我就从第二个tr开始下手了
for i in range(2, len(tr)):
ip = tr[i]
# 只是获取当前tr中的所有td
tds = ip.findAll('td')
# 当然要把为空的过滤掉
if tds == []:
continue
# 获取其中的下表为1的td的ip串和下标为2的号
ip_temp = tds[1].contents[0] + ":" + tds[2].contents[0]
# 存入容器
pool.append(ip_temp)、
# 收集一个延迟1秒再收集
time.sleep(1)
# 过滤掉不可用的ip
testIp(pool)
if __name__ == '__main__':
url = "http://www.xicidaili.com/nt/"
li = XiciAgent(url)
time.sleep(5)
如图:可见我们需要的ip在当前页就能捕捉到被一个一个tr包裹着