操作步骤
- 分析代理IP网站页面结构。
- 请求代理IP网站,解析并获取代理IP。
- 校验代理IP的可用性。
- 保存可用代理IP到文件中。
页面解析
- 分析https://www.xicidaili.com/nn页面,发现第二页和第三页的url分别为
https://www.xicidaili.com/nn/2和https://www.xicidaili.com/nn/3,即第n页需要访问https://www.xicidaili.com/nn/n。 - 分析页面源码,发现IP列表位于id为ip_list的table中,第一个tr标签为表头,剩余的tr标签中则存在着IP信息。
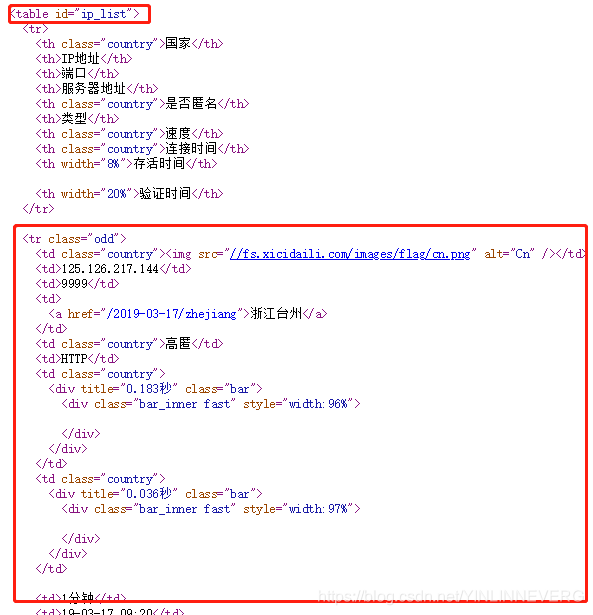
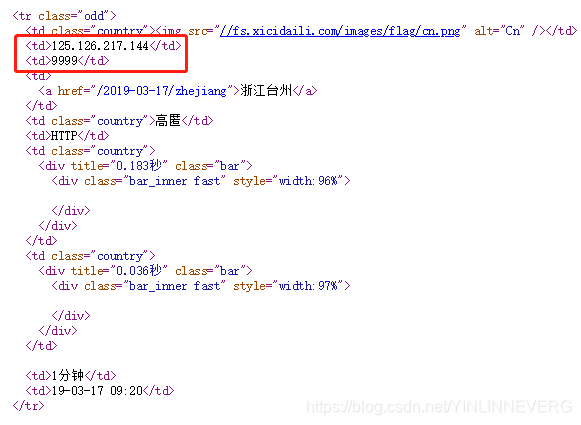
- 分析tr标签,可以看到,第二个td标签为IP,第三个td标签为端口。
IP可用性验证
最简单的办法就是使用该代理IP访问其他网址,访问成功即为可用。这里访问http://httpbin.org/ip这个网址,它会返回发起请求的客户端IP,返回内容为
{
"origin": ip
}
代码
- 需安装beautifulsoup4和requests模块,使用beautifulsoup4模块解析html页面,使用requests模块发送网络请求,将可用代理IP保存到proxies.txt文件中。
- https://github.com/Yinevg/PythonLearn/blob/master/get_proxy_ip/GetProxyIp.py
import json
import random
import requests
from bs4 import BeautifulSoup
base_url = 'https://www.xicidaili.com/nn/{}'
checkUrl = 'http://httpbin.org/ip'
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/72.0.3626.121 Safari/537.36'}
file_content = []
for i in range(1, 6):
proxies = {}
# 从已获取的代理IP中随机取一个来获取代理列表
if len(file_content) > 0:
random_proxy = random.sample(file_content, 1)[0]
proxies['http'] = random_proxy
proxies['https'] = random_proxy
# 获取请求结果
try:
resp = requests.get(url=base_url.format(i), headers=headers, proxies=proxies)
except Exception as e:
# 使用代理请求失败,移除该代理
if len(file_content) > 0:
file_content.remove(proxies['http'])
print('remove proxy %s: %s' % (proxies['http'], e))
continue
# 判断请求是否成功
if resp.status_code != requests.codes.ok:
print("get proxy list fail : %s" % resp.status_code)
continue
# 页面解析
bsObj = BeautifulSoup(resp.text, 'html.parser')
ipList = bsObj.find('table', {'id': 'ip_list'}).findAll('tr')
# 去除表头
for ip in ipList[1:]:
tds = ip.select('td')
proxy_ip = tds[1].get_text()
proxy_port = tds[2].get_text()
proxy = proxy_ip + ':' + proxy_port
check_proxies = {
'http': proxy,
'https': proxy
}
try:
print('check proxy %s' % proxy)
checkResp = requests.get(url=checkUrl, headers=headers, proxies=check_proxies, timeout=1)
# 检查是否为有效ip
if proxy_ip in json.loads(checkResp.text)["origin"]:
file_content.append(proxy)
print('proxy %s is valid' % proxy)
else:
print('proxy %s is invalid' % proxy)
except Exception as e:
print('proxy %s is invalid : %s' % (proxy, e))
if len(file_content) > 0:
with open("proxies.txt", "w", encoding="utf-8") as f:
for line in file_content:
f.write(line + '\n')
print('total: %s' % len(file_content))