2.5.1 强化指针概念
指针是C语言中最基本且很重要的概念,某种程度上甚至可以说:指针是C语言的灵魂。
不巧的是,我们公司新招聘的好多新人对C语言指针都比较陌生。和大家交流,思考背后原因,可能要拜人性中的“选择性遗忘”了(最近脑科学研发成果。人们一般会将极伤心的事忘记的干干净净,如果C语言会给我们带来痛苦,我们会第一时间忘记它)。大家因为道听途说C语言指针很难,然后就故意躲得远远的,即使尝试学了一点点,也努力忘他个干干净净。
真实产品是离不开指针的,尤其是在尝试引入各种架构设计后,指针更是漫天飞舞。因此,在入职C语言训练中,指针强化成为必不可少的课程。
C语言中对指针的基本定义是保存地址的变量,我刚开始学习C语言的时候还容易接受这个概念,但工作多年后反而容易犯糊涂了,挺像那种汉字越看越不像的感觉。
为了给新人讲解指针概念,在多年的培训实践中,我尝试了一种对比法,期望能帮助我们的小伙伴更容易理解指针。
在我眼中,指针由低级到高级,由生到死,一次迭代了三个层次:
1. 硬件层面的指针概念:
追根溯源,我们先来看最底层的汇编程序(直面硬件体系结构)是如何定义数据变量的,如下汇编代码片段:
value1:
DCD 0x11
DCD 0x22
value2:
DCB "welcome"
上述代码段定义了两个变量,value1和value2。我们习惯性认为value1对应了两个字(32位),value2对应了一个字符串。实际语言层面,value1和value2仅是一个地址标注,value1后面可以逻辑的认为是字符串,而value2后面也可以逻辑的认为是一个字,仅汇编语言本身并没有给予特别约定。
因此,在汇编语言(硬件体系)层次,所有的变量定义本质上都是地址(指针),至于地址里面存储的是什么内容,在汇编语言级别没有特别规定,可完全由我们自己自由发挥。
2. C语言中的指针
进入C语言后,为了编程的方便,我们增加了语义定义,数据开始有类型了,因此也出现了针对各种数据类型的指针定义,如int和float就有着不同又相同的含义。相同是因为都是指针,不同是因为指针指向内容存在差异。
因此,此时指针的含义,不能仅仅的理解为一个地址概念,还要关注地址指定的对象。同时,也需要记住指针变量仅仅是地址,因为这是指针作为变量本身的规则。
在C语言中,大家应该都知道,有且仅有值传递这一种方式,也就是说,传递给被调函数的参数值存放在一个临时变量中,而不是存储在原始变量中。换句话说,一个函数传递参数和返回值,或者一个赋值语句拷贝过程,都是完整字节拷贝模式,即使传递的是一个对象(结构体),也是老老实实的逐项拷贝。如果传递的是一个指针,是以指针的本质(地址)进行拷贝的。
比较下面几条代码片段:
int fun1(int a);
struct A fun2(struct A a)
{
struct A b;
……;
return b;
}
struct A* fun3(struct A* a);
fun1函数为基本的数值拷贝,比较好理解,函数内部怎样折腾变量a,都不担心对外部有影响。fun2参数和返回值的传递都是对象,逐个字节拷贝,当然这种代码效率较低。fun3参数和返回值拷贝的仅仅是指针本身,只是间接达到了对象的引用传递效果而已。
3.高级语言中的“指针”
我们经常说C语言是中级语言,为何呢,我个人的理解是:C语言仅引入了有限的语义,同时保留了大量的汇编级别语言的特性。如数组的概念,本质上依旧是指针而已,没有增加过多的语义概念。
但是随着编程理念的发展,各种新语义概念开始层出不穷。
如在C++中引入了类和对象的概念后,如果理解C++对象模型呢?要知道对象的数据结构比较复杂,甚至干脆就不在一块连续的内存上(如包含静态变量时,下图为典型的C对象内部结构图),此时的对象指针概念如何定义呢?

为此,在C++中额外增加了“引用”概念,主要就是用于对象的操作抽象,其本质相当于是一种别名。当然为了延续历史脉络,C++需要兼容设计,又需要拓展,导致其长成了一种杂合语言。大家平时会讨论指针和引用的区别,如果理解指针概念的发展史,就非常清晰了,对象尽量用引用,原有的数值和数组继续使用指针即可。
理解了这一点,就会明白很多高级语言为何会逐渐的取消指针,而进一步加强类引用的概念了,如java等。
经历了C语言指针有低级到高级,由生到死的迭代之旅后,您是否对C语言指针有更深刻的理解。我的理解:C语言指针不仅是一个地址,更需要关注它指向的内容,以及与此关联的语义。
2.5.2 指针类型及操作
上一节我们提到了C语言指针不仅是一个地址,更需要关注它指向的内容,以及与此关联的语义,这节就让我们来一起聊一聊C指针常见的语义。
首先,我们先来关注指针地址这个概念。如果有人接触过8位或16位单片机编程,就会发现指针地址本身也是存在很多差异的,有指向小范围的和大范围的,有短跳转和长跳转等。此时,各类指针变量本身的长度(sizeof)都不一样,指针变量拷贝赋值等操作都需要谨慎。
滚滚长江东逝水,目前嵌入式领域已逐渐的进入了32位系统,尤其是以arm cortex-m系列为首,此时,几乎所有的指针地址都是32位了。我们的系列文章如无特殊说明,都是以cortex-m系列芯片为主,大家可以将指针地址等价为32位整数。大家应该了解指针发展的历史脉络,这样会有更加完整的认知。
简单介绍C语言指针地址的概念后,我们来侧重关注指针指向的内容。依据我的工程实践经验,我将其提炼分解为几类:
- 0;
- void*;
- 指向常规变量的指针,如int*,float*等;
- 指向字符串的指针;
- 指向对象的指针;
- 指向函数的指针。
培训中,第一条就会让我们的一些小伙伴不淡定了, 0竟然也是指针!在c语言中,我感觉0就是个捣乱鬼,大家都知道八进制以0为起始,那么0是十进制数呢,还是八进制数呢,这个问题曾经困惑了我很多年。后来受中国文化“求同存异”的影响,我才能安慰自己,0既是十进制数,也是八进制数,破解了我多年的困惑。既然如此,0为何不能也同时是指针呢。
大家应该会经常看到这样的代码片段:
if (p != NULL)
{
……
}
该处的NULL一般被定义为0,此时,0就是以指针的身份存在的。抛开这些抽象概念,我们总结成一句话:任何指针和0进行相等或不等的比较或赋值操作都是有意义的。换句话说:指针和整数之间不能相互转换(强制转换除外),但0除外,0可以赋值给指针,也可以同指针进行比较(仅限相等和不等)。
◇◇◇
第二类指针语义是void指针。大家知道C语言一开始是没有void的吗?那为何后来有了呢,追根溯源,或许更好理解void*指针。
一开始C语言的通用指针大家都习惯使用int*,但因为指针是允许加减操作的,而且让人痛苦的是指针加减是按照执行对象大小加减的,更痛苦的是int在C语言中是一个自然变量(尽量发挥硬件特性的变量,因此各系统经常存在差异),因此,我们经常一不小心,就引入了一系列异常。
为了规避该问题,有人想出了一招,通用指针使用void*,因指向是虚无的,因此指针加加减减的操作就不被允许了,间接规避了好多无意识的错误。
既然是通用指针,因此可以装得下任何指针,但想返回去,就需要特定类型转换了,如下代码示例:
int *pint;
void *pvoid;
pvoid = pint; /* 合法 */
pint = pvoid; /* 不合法 */
pint = (int*)pvoid; /* 合法 */
因为void这个特点,如果需要传递各种指针时,我们就应该尽量使用void了,最典型的应用场合就是memcpy函数了,原型如下,大家在构建函数原型的时候也可以模仿:
void *memcpy(void *dest, const void *src, size_t n);
在我们团队的项目中,我喜欢将NULL定义为((void*)0),道理类似,其额外的好处就是强调不要拿NULL进行数学运算了。
◇◇◇
第三类为指向变量的指针,这个就不在赘述了,我们直接来关注第四类,指向字符串的函数。
指向字符串的指针实际上也是一种指向char变量的指针,但因为在实际使用过程中大家经常犯糊涂,因此被我独立的归为一类了。
谈起字符串指针,我们先来判断一下下面两条语句的差异:
char szMsg[] = "hello, xiaomaer";
char* pMsg = "hello, xiaomaer";
这道题经常用于面试时考察同学们对C语言的理解深度,如果不理解指针本质含义,一般要迷糊半天。比较如下:
-
szMsg是一个数组,是一种高级语义定义,赋值语句只是将这个数组大小被约定为字符串长度,并且将字符串给放进去当初值了而已。pMsg是一个指针变量,但其指向了一个常量字符串(在嵌入式系统中,该常量字符串一般位于flash区域了)。
-
对szMsg本身加减是不允许的,但可以修改数组内容(这是C语言赋予数组的语义),pMsg可以加减(这是C语言赋予指针的语义),但想去修改字符串内容,结果C语言不作假设(在嵌入式系统中,常量字符串经常放在flash中,会触发异常)。
如能细细体会该处的差异,应该能理解字符串指针概念。
指向对象的指针我们下一小节开始描述,指向函数的指针和架构设计关联比较紧密,几乎是构建整个嵌入式软件系统的基石,我们在例程三种详细描述。
◇◇◇
前面我们介绍了指针指向的语义,但不完整,我们还需要对其进行操作,还需要关心指针运算方面的语义。
指针最基本的操作是*和&运算符,单个都比较好理解,但碰到一些常用的组合语句后,我们就会犯糊涂。(我是做产品的,不允许产品中故意弄一些乱七八糟的组合,如i+++j之类,但下面的语句是真实产品中真实存在且经常使用的):
int* p;
int* q;
*p += 1;
*p++;
(*p)++;
*q++=*p++;
……
如p++操作,因为运算符低于++运算符,因此p++是先执行p++运算,后取值,但又因为是后加操作,所以先执行p,等取值操作完成后,p在++。(*p)++是对指针取出的数据进行后加操作的。
上述描述过程中存在两次反转,大家是否会感觉糊涂。实际上,我写了这些年的C语言程序,碰上这类混合运算也经常会犯糊涂。大家如果不服,可以品一品(*p[])()的语法含义,在《C程序设计语言》一本书中还有专门讲解,比较费解,容易折腾人。
工程实践中,为了解决这类问题,我们采取了一种典型策略:严格约定项目中允许使用的组合表达式,并通过实例代码让大家理解这些约定组合表达式含义即可。除了项目组约定的组合表达式之外,就不允许在使用其他组合表达式了。
我们项目组中,典型的组合表达式部分截取如下:
- (*p)++主要用于指针指向变量加1操作,示例如下:
DWORD* pCount; /* 个数 */
pCount = (DWORD*)(COUNT_ADDR);
(*pCount)++;
if (*pCount >= 32) /* 反转 */
*pCount = 0;
- *q++=*p++主要用于内存拷贝操作,相当于“*q=*p; p++; q++;”,示例如下:
pDes = &...;
pSrc = &...;
for (i = 0; i < sizeof(...); i++)
*pDes++ = *pSrc++;
- 规避直接的函数指针(*p)()或函数指针数组(*p[])(),通过typedef增加可读性,示例如下:
/* 端口驱动,读取数据 */
typedef DWORD (*HWPortDrvRead)(DWORD dwPort, BYTE* pBuf, DWORD dwLen);
HWPortDrvRead pfnRead; /* 读函数 */
HWPortDrvRead pfnReadArray[] = /* 读函数列表 */
{
rs232_read, rs485_read, ether_read
};
……
除了&和*外,指针还允许==,!=,<,>,+,-等运算符,但要注意不是全部都可以,经常使用的情况汇总如下:
- 任何指针和0进行相等或不等的比较都是有意义的;
- 指针可以和整数进行加减操作,如p+n,需要注意的是,是按照指向对象大小空间进行加减的;
- 同一数组中的指针可以进行比较操作,用于判断前后关系;
- 同一数组中指针执行相减操作,尤其是减去头部指针可判断当前元素位置,这是常使用的技巧。
2.5.3 教科书级的指针列表
在上一节文章中,我们将指针按其指向语义分为多个类型,其中第5类是对象指针。在C语言中,对象用struct来表达,如果将指针和数组结合在一起,一种常见且很有价值的数据结构“链表”就诞生了。
为了让小伙伴进一步熟悉链表操作,我们的第二个例程诞生了:使用链表方式构建一个学生信息管理系统,支持添加、删除、查询、遍历等操作。
各位读者,是否有一点点熟悉的味道。没错,因为这经常就是大学C语言教材中讲解链表所用到的例程(各学校使用的教材不同,但不影响本节后续内容阅读)。因此,这个例子我们的小伙伴都完成的很happy。
现在,让我们一起重新温故这个例程。
◇◇◇
为了简单,学生信息结构描述如下:
struct student
{
int num; /* 学号 */
float score; /* 成绩 */
struct student *next; /* 指向下一结点 */
};
构建的列表结构如下图示意:
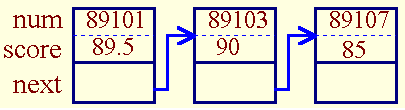
为了访问链表,需要定义如下变量
struct student *head; /* 表头 */
struct student *p1; /* 新建结点 */
struct student *p2; /* 表尾结点 */
◇◇◇
我们首先来分析链表的构建(也即添加操作)过程,然后,很郁闷的发现需要分两种情况分别处理:
- 链表为空
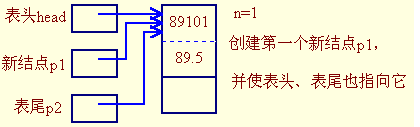
p1 = malloc(...);
head = p1;
p2 = p1;
- 链表不为空
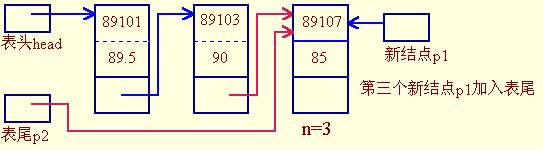
p1 = malloc(...);
p2->next = p1;
p2 = p1;
◇◇◇
然后,是删除操作。在删除时,首先要执行查找操作,先要找到需要删除的节点,假设用p1指向它,并用p2指向p1的前一个节点。同添加操作一样,我们悲催的发现,需要分三种情况分别处理。
- 列表为空,要删除的节点为NULL:
if (head == NULL)
return;
- 要删除的节点是头节点:
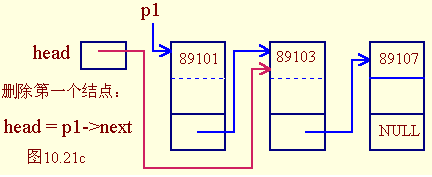
free(head);
head = p1->next;
- 要删除的节点不是头节点:
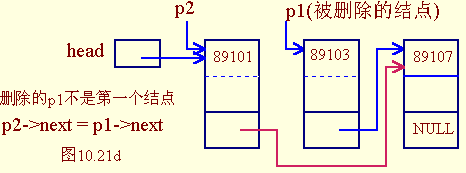
p2->next = p1->next;
free(p1);
◇◇◇
前面谈到了链表的添加和删除操作,如果在加上很简单的查询遍历操作,已经构建了一个完备的链表数据模型。但不知大家有没有意识到:链表虽然将学生信息组织在一起,实际上学生信息是乱序的。而如果链表内容要求排序,添加操作(准确描述应该称之为插入操作)就需要重构了。
假设我们的学生信息按学号从小到大排序,p0指向要插入的对象,查找定位p1节点,并在p1之前插入。然后本节最郁闷的事情出现了,竟然需要分为四种情况分别处理:
- 链表为空
head = p0;
- 将p0插入第一个结点之前
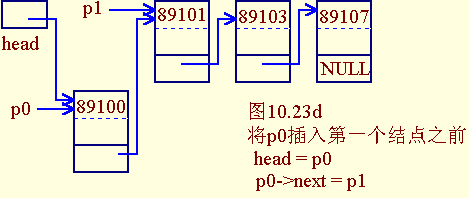
head = p0;
p0->next = p1;
- 将p0插入表尾结点之后
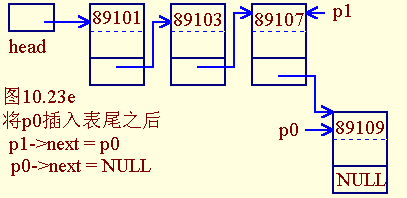
p1->next = p0;
p0->next = NULL;
- 中间插入,此时p2指向p1的前一个节点
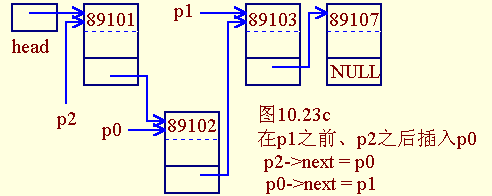
p2->next = p0;
p0->next = p1;
◇◇◇
至此,我们已经将链表的基本操作温故了一遍,但大家感觉如何,有没有头晕。上面是大学教程中的标准实现,但这种方法好吗!要知道链表操作在真实产品中可经常会用到,但大家能准确的记住上面共计(2+3+4)种分支吗!能保证每次都准确无误且不遗漏的写出来吗!能保证你在审核时碰到类似的代码时能立即发现其中bug吗!
真实产品世界,我们需要寻找新的出路。
2.5.4 实际产品中的指针列表
链表的常见操作包含添加、删除等,在上一节中,我们实际上描述了两种添加操作。为何?因为链表中的内容有两种模式:有序和无序。可惜的是,大部分新人在例程二闭环反馈例程时,很少有新人能提出学生队列是否需要排序的疑问。通过这一次迭代提醒,很多新人会慢慢开悟了,开始真正的认真对待工作闭环反馈。
我们首先来描述无序的链表数据结构,说起无序,实际上类似于集合操作了。在嵌入式系统中,我们经常用链表组织管理一堆信息,如管理所有的任务对象等。
此时如何进行添加操作呢?策略很简单:头部插入即可。
假设表头为pHead,新建节点为pNew,让我们来模拟上一节中插入操作的两种情况:
- 链表为空,此时pHead = NULL:
插入程序为: pNew->next = pHead; pHead = pNew; - 链表不为空,此时pHead != NULL:
插入程序为: pNew->next = pHead; pHead = pNew;
大家发现了什么,不管链表是否为空,插入操作一致而简洁,没有分支,有没有好清爽的感觉。
◇◇◇
在嵌入式产品中,为了规避内存碎片,追求长期稳定运行和可靠性,会使用内存预分配策略,也就是指将一个模块估计使用的内存预先分配出来。大家如果接触过商业代码就会发现,很多模块都有一个配置文件,其中最主要的配置项就是约定预分配大小,如ucos中最大任务数,如lwIP中的最大tcp连接数等。
为了应对这种情况,需要额外构建一个空闲指针,初始化时一次分配预定义大小的结构块,并通过空闲指针串联起来,用时取,用完还,不够用报警。
假设表头为pHead,空闲指针为pFree,无序空闲链表的基本操作包含:初始化、用时取、用完还。
设新取的节点指针为pNew,用时取和不够用报警流程如下:
pNew = pFree;
if (pNew == NULL)
不够用,报警;
pFree = pFree->next;
设p1为要归还的节点,用完还流程如下:
p1->next = pFree;
pFree = p1;
初始化例程,相当于将预分配的空间所有节点都归还,设预分配内存空间为pFree,例程如下:
pHead = NULL;
pFree = NULL;
for (i = 0; i < dwCount; i++)
{
pPre[i].next = pFree;
pFree = &pPre[i];
}
此时,构建出来的列表会先从预分配空间的尾部用起,会给调试带来一些不便,优化的策略也很简单,初始化时逆序排列即可,如下所示:
for (i = dwCount-1; i >=0; i--)
{
pPre[i].next = pFree;
pFree = &pPre[i];
}
至此,无序的链表操作就介绍完毕了。大家有没有发现,所有的操作都是针对头部操作,没有分支,非常简洁。
◇◇◇
前文提到的无序链表的插入和删除操作,都是通过头部进行的。因为无序,所有其中每个节点都是类似的,插入和删除位置无所谓,有点类似集合的概念,因此可以简化为基于头部指针的操作。
假设我们的链表是有序列表,此时的插入和删除操作就会变的啰嗦很多,有没有好的办法呢?我寻觅多年,终于找到一种比较好的策略,项目组内部喜欢将其称为“虚头”指针。
何为“虚头”指针呢?为了减少指针为NULL的判断,我们为何不给其固定的增加一个头部,使其永远不为null呢!额外增加的这个头部指针就称之为“虚头”指针。
增加虚头指针后的插入和删除操作是怎样的呢?我们继续以学生信息结构为例:
struct student
{
int num; /* 学号 */
float score; /* 成绩 */
struct student *next; /* 指向下一结点 */
};
struct student mgr; /* 学生管理链表头, 虚头指针 */
假设以学号正序排列,且pNew为当前要插入的对象,插入操作如下:
void add(struct student* pNew)
{
struct student* q; /* 上一节点 */
struct student* p; /* 当前节点 */
/* 遍历查找并插入 */
p = &mgr; /* 虚头指针 */
for (;;)
{
q = p; /* 备份上一节点位置 */
p = p->pNext; /* 下一节点 */
if (p == NULL || pNew->num < p->num) /* 插入判断 */
{
p1->pNext = p;
q->pNext = pNew;
break;
}
}
}
借助于虚头指针,我们用一条语句将教科书上的4种情况(空、头、尾、中间)全部覆盖了,注意其中||运算符有一定的技巧性,p为NULL时,pNew->num < p->num不会被执行,不存在内存异常访问的情况,是否有很清爽的感觉。
与插入类似,假设知道学号,删除操作流程如下:
void del(int num)
{
struct student* q; /* 上一节点 */
struct student* p; /* 当前节点 */
/* 遍历查找并删除 */
p = &mgr;
for (;;)
{
q = p;
p = p->pNext;
if (p == NULL) /* 未找到 */
break;
if (num == p->num)
{
...; /* 将p还给free队列 */
q->next = p->next;
break;
}
}
}
◇◇◇
前文介绍到一种针对有序列表的插入和删除操作,通过增加一个虚拟头部,减少了很多判断分支。但假如该结构由很多成员,这个虚拟头部就过于浪费内存了,要知道在工业嵌入式设备中,内存可是珍贵资源。
如何破解这一困局呢?
细细分析关于虚拟指针相关代码,我们发现mgr的使用主要是为了减少分支情况,其本身也仅使用next字段而已,那么,如果我们是否可以仅保留next字段,而取消其他内容呢。
此时,我们需要额外定义一个结构,同时需要将next字段提到最前面,如下代码示例:
struct student
{
struct student *next; /* 指向下一结点 */
int num; /* 学号 */
float score; /* 成绩 */
};
struct studentHead{struct student *next;} mgr; /* 学生管理链表头 */
然后在插入删除操作中增加强制类型转换即可,如下示意:
p = (struct student *)&mgr;
◇◇◇
链表结构具备一定的灵活性,但一步执行出错,就会导致整个链表变成脏数据而导致系统异常。实际上,指针操作都有一点让人不踏实的感觉,尤其是可靠性要求很高的嵌入式系统。我在进行代码审核时,指针类操作一般都是我审核的重点之一,如果看到不熟悉的指针操作,经常就会睡不着觉了,会担心产品运行失控。
为了解决这个问题,我们在实际项目中经常使用一种称之为“桩检测”的策略,也就是在指针指向的内容中插入一个或多个检测桩,一般有头部或头尾部两种模式,继续以学生信息结构为例,如下示意:
struct student
{
unsigned int nHeadFlag; /* 头部检测桩, 约定为'stud' */
struct student *next; /* 指向下一结点 */
int num; /* 学号 */
float score; /* 成绩 */
...
};
struct studentHead
{
unsigned int nHeadFlag; /* 头部检测桩, 约定为'stud' */
struct student *next;
} mgr; /* 学生管理链表头 */
结合检测桩,对每一个传递进来的指针进行桩检测,可大幅度减少指针乱飞的情况。
◇◇◇
至此,传统的链表操作已经被我们修改的面目全非了,为了便于项目组内交流方便,我们随意起了一个名字,叫"虚头单向链表",大家感觉好不好听,可以随意修改,只要项目组内交流方便就ok了。完整代码示意如下:
#include <stdio.h>
/* 学生信息结构 */
struct student
{
int flag; /* 头部检测桩,约定为'stud' */
struct student *next; /* 指向下一结点 */
int num; /* 学号 */
float score; /* 成绩 */
};
/* 学生信息虚拟头结构 */
struct studentHead
{
int flag; /* 头部检测桩,约定为'stud' */
struct student *next;
};
/* 预分配的学生信息 */
#define MAX_NUMBER 4
static struct student inf[MAX_NUMBER];
/* 空闲指针 */
static struct student *pFree;
/* 虚拟头 */
static struct studentHead mgr;
/* 初始化,构建空闲列表 */
void init(void)
{
int i;
/* 赋初值 */
pFree = NULL;
mgr.flag = (int)'stud';
mgr.next = NULL;
/* 依次插入空闲队列,并清标志 */
for (i = MAX_NUMBER - 1; i >= 0; i--)
{
inf[i].flag = 0;
inf[i].next = pFree;
pFree = &inf[i];
}
}
/* 头部(无序)插入 */
void add(int num, float score)
{
struct student *pNew;
/* 取出一个空节点 */
pNew = pFree;
if (pNew == NULL) /* 无可用节点 */
return;
pFree = pNew->next;
/* 赋值 */
pNew->flag = (unsigned int)'stud';
pNew->num = num;
pNew->score = score;
/* 插入头部 */
pNew->next = mgr.next;
mgr.next = pNew;
}
/* 有序(按学号顺序)插入 */
void insert(int num, float score)
{
struct student* q; /* 上一节点 */
struct student* p; /* 当前节点 */
struct student *pNew; /* 新建节点 */
/* 取出一个空节点 */
pNew = pFree;
if (pNew == NULL) /* 无可用节点 */
return;
pFree = pNew->next;
/* 赋值 */
pNew->flag = (unsigned int)'stud';
pNew->num = num;
pNew->score = score;
/* 遍历查找并插入 */
p = (struct student *)&mgr;
for (;;)
{
q = p; /* 备份上一节点位置 */
p = p->next;
if (p == NULL || pNew->num < p->num) /* 插入判断 */
{
pNew->next = p;
q->next = pNew;
break;
}
}
}
/* 已知学号删除 */
void del(int num)
{
struct student* q; /* 上一节点 */
struct student* p; /* 当前节点 */
/* 遍历查找并删除 */
p = (struct student *)&mgr;
for (;;)
{
q = p; /* 备份上一节点位置 */
p = p->next;
if (p == NULL) /* 未找到 */
break;
if (num == p->num)
{
q->next = p->next; /* 删除p节点 */
p->next = pFree; /* 将p还给pFree */
pFree = p;
break;
}
}
}
/* 使用 */
void use(struct student* p)
{
if (p == NULL)
return;
if (p->flag != (int)'stud')
return;
printf("num: %d, score: %.2f\n",
p->num, p->score);
}
/* 遍历 */
void list(void)
{
struct student* p;
/* 遍历查找并删除 */
printf("begin-----\n");
for (p = mgr.next; p != NULL; p = p->next)
{
use(p);
}
printf("end-----\n\n");
}
/* 主程序 */
int main (void)
{
...
}
2.5.5 测试路径
前文我提到,在学校学习编程,能将一个问题用程序表达出来就ok了。但做产品,对代码的要求可不止于此。
做嵌入式产品,代码编写并调试完毕,仅仅是开始,后续无数次的阅读、维护、测试、优化、重构才会占去大部时间,如果一开始的工作量为1,后续可能会进行N倍放大。
在单元代码阶段,最有效的测试手段就是代码审核和白盒测试。很多嵌入式设备需要长期稳定运行,此时对代码质量的最低要求是完成100%覆盖测试,如何有效的达到这一要求呢?本小节,我们一起从白盒测试的角度来审视一遍上一节的链表代码。
◇◇◇
首先,我们分析初始化代码,代码示意如下:
void init(void)
{
/* 赋初值 */
...
/* 依次插入空闲队列,并清标志 */
for (i = MAX_NUMBER - 1; i >= 0; i--)
{
inf[i].flag = 0;
inf[i].next = pFree;
pFree = &inf[i];
}
}
这段代码,虽然其中有一个循环体,是单流程代码,没有任何分支,因此它的执行流程是唯一的。如果我们需要写针对这个函数的测试用例,只要一次简单的调用即可。
同理,遍历程序也是单流程代码,示意如下:
void list(void)
{
/* 遍历查找并删除 */
for (p = mgr.next; p != NULL; p = p->next)
{
...
}
}
因此,如对list函数编写测试用例,也仅需简单的调用一次即可。
◇◇◇
现在,让我们找一个复杂的例子,有序插入,这段代码示意如下:
void insert(int num, float score)
{
/* 取出一个空节点 */
if (pNew == NULL) /* 无可用节点 */
return;
/* 赋值 */
...
/* 遍历查找并插入 */
for (;;)
{
if (p == NULL || pNew->num < p->num)
{
...
break;
}
}
}
这个函数就有多个分支了,如何编写白盒测试用例呢,为了达到100%分支覆盖,需如下的几条路径:
- if (pNew == NULL) 的直接返回;
- for循环体中if语句条件始终不满足的情况;
- for循环体中p==nulll条件满足;
- for循环体中pNew->num < p->num条件满足。
为了覆盖上面的几条执行路径,需要构建测试用例如下:
- 无可用节点(路径1);
- 空链表插入(路径3);
- 链表头部插入(路径4);
- 链表尾部插入(路径2);
- 链表中间插入(路径4)。
因此创造条件,五次inser调用即可完成覆盖测试。无序添加和删除构建测试用例,类同于inser过程了,大家可以直接构建。
◇◇◇
前面的代码是已经被我优化过的,因此测试路径比较简洁,但实际产品中,经常是数不清的分支,将测试编程一件不可能的事。实际产品中的代码,一般刚开始很单纯,如下示意:
int test(void)
{
int a;
a = 1;
return a;
}
但随着产品功能的持续增加,我们在不断的加入各种选项判据,导致if判断语句开始增加,可能的代码就变成如下的样子了:
int test(void)
{
int a;
if (flag1)
{
if (flag2)
a = 1;
else
{
if (flag3)
a = 2;
else
a = 3;
}
}
else
a = 4;
}
每增加一种判据,经常导致原有的执行路径扩展一倍,很快,构建可覆盖所有分支的测试用例就成为一件不可能的任务了,同时,产品质量也开始失控了。
现在,大家可以在返回比对第三小节节给出的教科书示例,如果我们需要对其代码进行测试,测试用例会是几何?在嵌入式系统中,尤其是很多涉及安全和高可靠行业的设备,都需要进行代码分支覆盖测试,如何能有效减少代码分支数量,是需要在一开始编码阶段就考虑的事情。
在例程一中,我已经提到了一种有效的减少代码分支的策略:条件卫语句。在一个函数的起始位置集中判断各种错误,如存在错误时直接异常或返回,减少各种条件判断语句和主流程的混杂,可大幅度减少程序执行分支。
多年的工程实践活动,让我们形成了一种低成本且高效的单元白盒测试策略:单元测试用例随同模块一起实施编写,并进行统一审核。因为审核要求代码测试用例全分支覆盖,程序员在编写单元代码时,就会有意识的主动减少程序分支。
2.5.6 总结和思考
又到了要求新人总结思考的时候了,你不妨也掩卷沉思,本节是如何带着大家复习加强指针概念的,同传统的课本知识有哪些不同。
我平时喜欢同新人交流,询问他们总结时有哪些收获。一次,一新人告诉我,总结时才发现,没想到自己已经走出去那么远。记得当时听到这一句话,我内心特欣慰。
本节不仅仅在帮助新人复习加强指针的概念,更是从一名嵌入式软件工程师的角度、实际产品研发的角度帮助大家重新梳理指针概念。
一开始,我们比对了汇编、C语言、C++等高级语言中的指针,通过追溯指针的生死之旅,告诉了你指针的全新概念:C语言指针不仅是一个地址,更需要关注它指向的内容,以及与此关联的语义。
然后,从这个概念出发,我们先简要叙述了8、16、32位等嵌入式系统上的指针地址差异,然后依据指针指向语义,将指针分为如下几种:
- 0;
- void*;
- 指向常规变量的指针,如int*,float*等;
- 指向字符串的指针;
- 指向对象的指针;
- 指向函数的指针。
前4种比较简单,依次复习加强,并顺便提炼了指针允许的各种操作,汇总如下:
- 任何指针和0进行相等或不等的比较都是有意义的;
- 指针可以和整数进行加减操作,如p+n,需要注意的是,是按照指向对象大小空间进行加减的;
- 同一数组中的指针可以进行比较操作,用于判断前后关系;
- 同一数组中指针执行相减操作,尤其是减去头部指针可判断当前元素位置,这是常使用的技巧。
借助指向对象的指针,我们进入了链表的世界。很多新人刚入职时,身上还带有浓浓的学校的烙印,很难从产品的角度去思考。为了帮助大家理解学校和产品的区别,我首先引出教科书上指针链表实现,然后借助白盒单元测试的概念,告诉大家,这样的代码不应该出现在产品中。
产品中有两种常见的链表实现,无序和有序。这两种实现机制在我们自己的产品中使用非常普遍,大家后续在接触真实产品代码时,立即会有一种熟悉的感觉。对比实验表明,例程二对新人克服指针困局,有较大的帮助。
当然,关于C语言指针的内容,肯定不止这些,一些小伙伴会问,为何仅介绍单向链表呢,没有双向链表吗?双向链表因为一次需要好处理好几个指针,直接写在代码中很容易错误,也难于审核,因此一般都被子程序化了。
真实产品中的链表操作可能比我们想象的要复杂好多,经常是各种情况的组合,举一个简单的例子,os中的任务,一般以链表方式组织,但同时多个任务需要等待一个信号量呢,一个任务要等待多个信号量呢,如何组织,上一幅图让大家意会一下:

有没有头晕的感觉。实际上,真实产品中这类代码占比非常小,大部分都位于底层或算法模块中。我们一般不会让新人一开始就接触到这类代码。当新人具备一定工作经验,熟悉各种链表操作后,在接触这类程序,自然会手到擒来,轻易克服。
——————————————
我是小马儿,一个渴望良知与灵魂的嵌入式软件工程师,欢迎您的陪伴与同行,如感兴趣可加个人微信号nzn_xiaomaer交流,需备注“异维”二字。
