文章目录
第 2 章、使用Python进行DIY
2.5、手写数字的数据集MNIST
2.5.1、准备MNIST训练数据
1、下载训练集和测试集
完整的(训练集6万个,测试集1万个):
https://pjreddie.com/projects/mnist-in-csv/
不完整的(训练集100个,测试集10个):
https://raw.githubusercontent.com/makeyourownneuralnetwork/makeyourownneuralnetwork/master/mnist_dataset/mnist_train_100.csv
https://raw.githubusercontent.com/makeyourownneuralnetwork/makeyourownneuralnetwork/master/mnist_dataset/mnist_test_10.csv
2、数据组成
数据放在csv文件中。
一条数据是一行。
每行的第一个是标签,即书写着实际希望表示的数据。
随后的数值,用逗号隔开,是手写体数字的像素值。像素数组尺寸为28*28,因此在一个标签中有784个像素值。
每个像素值的范围是0~255。代表颜色的深度。
3、python查看文件
打开文件,获取其中的内容,然后关闭文件:
data_file = open("mnist_dataset/mnist_train.csv",'r')
data_list = data_file.readlines()
data_file.close()
说明:
(1)、open函数的参数列表,第一个是要打开的文件,第二个是打开方式,这里r代表只读方式。
(2)、readlines()函数的意思是读取整个文件所有的内容,生成一个字符串数组,每行是一个字符串。
(3)、打开的文件必须close()掉,否则可能会出现各种问题。
4、读取一条数据
import numpy
import matplotlib.pyplot
# 训练集有6万条,测试集有1万条
# 读文件,open函数的参数列表,第一个是要打开的文件,第二个是打开方式,这里r代表只读方式
data_file = open("mnist_dataset/mnist_train.csv", 'r')
# readlines()函数的意思是读取整个文件所有的内容,生成一个字符串数组,每行是一个字符串
data_list = data_file.readlines()
# 打开的文件必须close()掉,否则可能会出现各种问题。
data_file.close()
# 输出第1行内容
print(data_list[0])
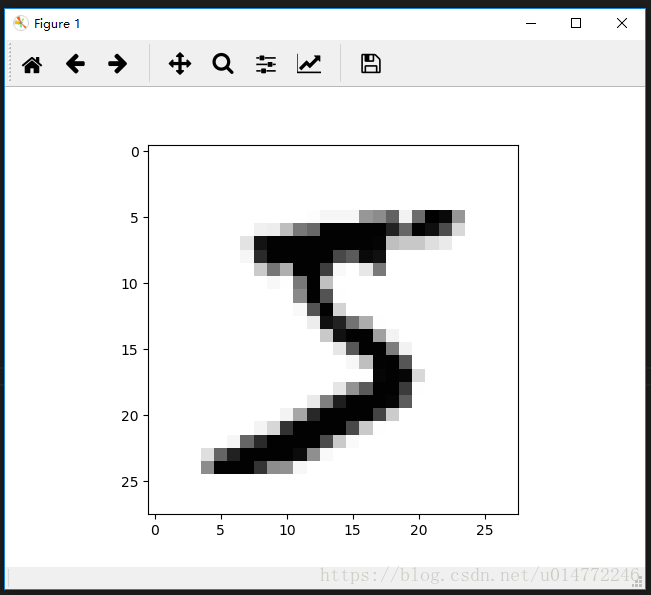
5、使用inshow()函数绘制数字矩阵数组

import numpy
import matplotlib.pyplot
# 训练集有6万条,测试集有1万条
# 读文件,open函数的参数列表,第一个是要打开的文件,第二个是打开方式,这里r代表只读方式
data_file = open("mnist_dataset/mnist_train.csv", 'r')
# readlines()函数的意思是读取整个文件所有的内容,生成一个字符串数组,每行是一个字符串
data_list = data_file.readlines()
# 打开的文件必须close()掉,否则可能会出现各种问题。
data_file.close()
# 输出第1行内容
# print(data_list[0])
# 用逗号分隔字符串,将长的文本字符串拆分成单个的值
all_values = data_list[0].split(',')
# 忽略第一个值,从第二个开始,asfarray()将文本字符串转换成数字形式的
# reshape()将剩余的28*28=784个数据转换成28行28列的数组
image_array = numpy.asfarray(all_values[1:]).reshape((28, 28))
# 绘制数组,第一个参数是数组,第二个参数是绘制方式,Greys是灰度调色板
matplotlib.pyplot.imshow(image_array, cmap='Greys', interpolation='None')
# 显示上面的画的图像
matplotlib.pyplot.show()
6、优化输入数据
前面说过,输入值应控制在0.0到1.0之间,不包含0.0,因为使用非常小或者非常大的输入可能会丧失精度。
所以,我们将0~255的数据映射到0.01~1.00之间,代码如下:
7、目标输出的方案
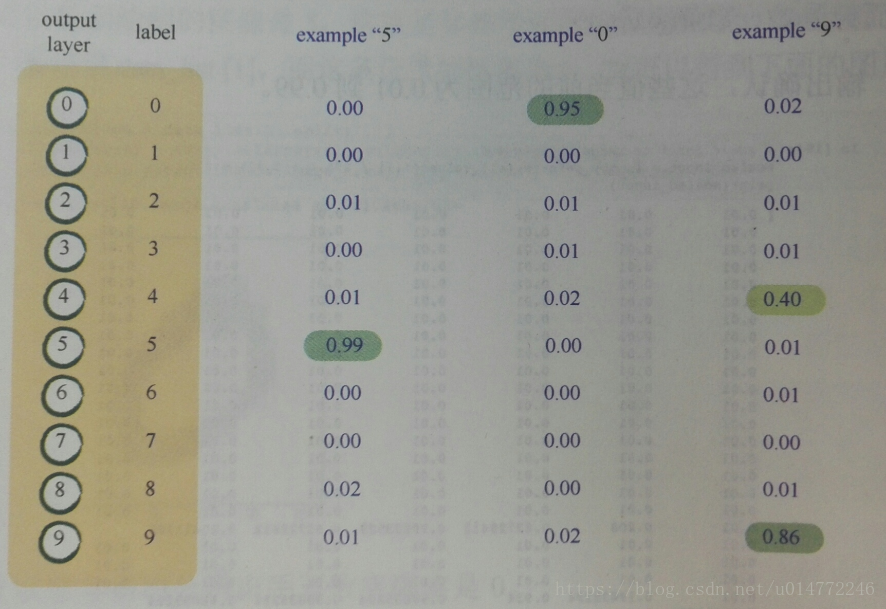
目标输出这种为10个结点,每个结点对应一种可能的答案或者标签,如果答案是0,第一个结点激发,其余结点则保持一致状态。如下图所示,是可能的情况:
因为前面说过,定义的目标输出在0.0~1.0之间,而且不包含0.0和1.0,所以,我们定义的0应该为0.01,1.0应该为0.99,比如标签为5的,目标输出应为[0.01, 0.01, 0.01, 0.01, 0.01, 0.99, 0.01, 0.01, 0.01, 0.01]
如下代码可以为某一条数据设置目标输出:
# 整理文件输出
import numpy
import matplotlib.pyplot
# 训练集有6万条,测试集有1万条
# 读文件,open函数的参数列表,第一个是要打开的文件,第二个是打开方式,这里r代表只读方式
data_file = open("mnist_dataset/mnist_train.csv", 'r')
# readlines()函数的意思是读取整个文件所有的内容,生成一个字符串数组,每行是一个字符串
data_list = data_file.readlines()
# 打开的文件必须close()掉,否则可能会出现各种问题。
data_file.close()
# 用逗号分隔字符串,将长的文本字符串拆分成单个的值
all_values = data_list[0].split(',')
# 整理输入数据
scaled_input = (numpy.asfarray(all_values[1:])/255.0*0.99)+0.01
# output nodes is 10(example)
onodes = 10
# 生成一个长度为10的数组,然后都加0.01,这样就10个都是0.01了
targets = numpy.zeros(onodes)+0.01
# 然后再将标签所指的那个点设成0.99即可
targets[int(all_values[0])] = 0.99
# 输出
print(targets)
8、截止到目前的代码:

# make your own neural network
# code for a 3-layer neural network, and code for learning the MNIST dataset
import numpy
# scipy.special for the sigmoid function expit()
import scipy.special
# library for plotting arrays
import matplotlib.pyplot
# neural network class definition
class neuralNetwork:
# initialise the neural network
# 初始化神经网络
# inputnodes,hiddennodes,outputnodes分别是输入层,隐藏层和输出层网络节点的个数
# learningrate是学习率
def __init__(self, inputnodes, hiddennodes, outputnodes, learningrate):
# set number of nodes in each input, hidden, output layer
# 设置输入,隐藏和输出层节点的数量
self.inodes = inputnodes
self.hnodes = hiddennodes
self.onodes = outputnodes
# link weight matrices, wih an who
# 链接权重矩阵
# wih是输入层和隐藏层之间的链接权重矩阵W_input_hidden
# who是输入层和隐藏层之间的链接权重矩阵W_hidden_output
# weights inside the arrays are w_i_j, where link is from node i to node j in the next layer
# 数组里的权重是wij,其中链接是从节点i到节点j的下一层
# w11 w21
# numpy.random.normal(a,b,(X,Y))的意思是生成一个随机数组,数组大小为X*Y,内容服从中心值为a,方差为b
self.wih = numpy.random.normal(
0.0, pow(self.inodes, -0.5), (self.hnodes, self.inodes))
self.who = numpy.random.normal(
0.0, pow(self.inodes, -0.5), (self.onodes, self.hnodes))
# learning rate
# 设置学习率
self.lr = learningrate
# activation function is the sigmod function
self.activation_function = lambda x: scipy.special.expit(x)
pass
# train the neural network
def train(self, inputs_list, targets_list):
# vonvert inputs list to 2d array
inputs = numpy.array(inputs_list, ndmin=2).T
targets = numpy.array(targets_list, ndmin=2).T
# calculate signals into hidden layer
# 计算隐藏层的输入
# numpy.dot(X,Y)的意思是两个数组的点乘
hidden_inputs = numpy.dot(self.wih, inputs)
# calculate the signals emerging from hidden layer
# 计算隐藏层的输出
hidden_outputs = self.activation_function(hidden_inputs)
# calculate signals into final output layer
# 计算输出层的输入
final_inputs = numpy.dot(self.who, hidden_outputs)
# calculate the signals emerging from final output layer
# 计算输出层的输出
final_outputs = self.activation_function(final_inputs)
# output layer error is the (target-actual)
# 计算输出层的误差
output_error = targets-final_outputs
# hidden layer error is the output_error, split by weight,recombined at hidden nodes
# 计算隐藏层的误差
hidden_error = numpy.dot(self.who.T, output_error)
# update the weights for the links between the hidden and output layers
# 更新隐藏层到输出层的权重
# 下面行末尾加的反斜杠\的意思是编译的时候忽略换行符
# 如果一行写不下,在代码末尾加上“\”即可
# 另外,在括号() {} [] 中的代码不需要换行符“\”,直接换行即可达到同样的效果
self.who += self.lr * \
numpy.dot((output_error*final_outputs*(1.0-final_outputs)),
numpy.transpose(hidden_outputs))
# update the weights for the links between the input and hidden layers
# 更新输入层到隐藏层的权重
self.wih += self.lr * \
numpy.dot((hidden_error*hidden_outputs *
(1.0-hidden_outputs)), numpy.transpose(inputs))
# query the neural network
def query(self, inputs_list):
# convert inputs list to 2d array
inputs = numpy.array(inputs_list, ndmin=2).T
# calculate signals into hidden layer
# 计算隐藏层的输入
# numpy.dot(X,Y)的意思是两个数组的点乘
hidden_inputs = numpy.dot(self.wih, inputs)
# calculate the signals emerging from hidden layer
# 计算隐藏层的输出
hidden_outputs = self.activation_function(hidden_inputs)
# calculate signals into final output layer
# 计算输出层的输入
final_inputs = numpy.dot(self.who, hidden_outputs)
# calculate the signals emerging from final output layer
# 计算输出层的输出
final_outputs = self.activation_function(final_inputs)
return final_outputs
# number of input, hidden and output nodes
# 设置输入,隐藏和输出层节点的数量
# 输出层有28*28=784个数据
input_nodes = 784
# 这个自己随便设的
hidden_nodes = 100
# 按本例子的的方案,输出有10中,结点有10个
output_nodes = 10
# learning rate is 0.3
# 设置学习率为0.3
learning_rate = 0.3
# create instance of neural network
# 创建一个神经网络的实例
n = neuralNetwork(input_nodes, hidden_nodes, output_nodes, learning_rate)
# load the mnist training data CSV file into a list
# 训练集有6万条,测试集有1万条
# 读文件,open函数的参数列表,第一个是要打开的文件,第二个是打开方式,这里r代表只读方式
training_data_file = open("mnist_dataset/mnist_train.csv", 'r')
# readlines()函数的意思是读取整个文件所有的内容,生成一个字符串数组,每行是一个字符串
training_data_list = training_data_file.readlines()
# 打开的文件必须close()掉,否则可能会出现各种问题。
training_data_file.close()
# train the neural network
# go through all recordes in the training data set
for record in training_data_list:
# split the record by the ',' commas
# 用逗号分隔字符串,将长的文本字符串拆分成单个的值
all_values = record.split(',')
# scale and shift the inputs
# 整理输入数据
inputs = (numpy.asfarray(all_values[1:])/255.0*0.99)+0.01
# PS:这里能不能不每次都设置新的target,待改进:提前设置好然后直接调用某个目标输出
# create the target output values (all 0.01, except the desired label which is 0.09)
# 生成一个长度为10的数组,然后都加0.01,这样就10个都是0.01了
targets = numpy.zeros(output_nodes)+0.01
# all_values[0] is the target label for this record
# 然后再将标签所指的那个点设成0.99即可
targets[int(all_values[0])] = 0.99
# 开始训练
n.train(inputs, targets)
pass
2.5.2、测试网络
测试代码主要还是用query函数,之前有写过,现在进行一个改写。
另外就是加了个scorecard变量用来统计准确率。
scorecard_array = numpy.asarray(scorecard)
print("performance = ", scorecard_array.sum()/scorecard_array.size)
最终代码如下:
# make your own neural network
# code for a 3-layer neural network, and code for learning the MNIST dataset
import numpy
# scipy.special for the sigmoid function expit()
import scipy.special
# library for plotting arrays
import matplotlib.pyplot
# neural network class definition
class neuralNetwork:
# initialise the neural network
# 初始化神经网络
# inputnodes,hiddennodes,outputnodes分别是输入层,隐藏层和输出层网络节点的个数
# learningrate是学习率
def __init__(self, inputnodes, hiddennodes, outputnodes, learningrate):
# set number of nodes in each input, hidden, output layer
# 设置输入,隐藏和输出层节点的数量
self.inodes = inputnodes
self.hnodes = hiddennodes
self.onodes = outputnodes
# link weight matrices, wih an who
# 链接权重矩阵
# wih是输入层和隐藏层之间的链接权重矩阵W_input_hidden
# who是输入层和隐藏层之间的链接权重矩阵W_hidden_output
# weights inside the arrays are w_i_j, where link is from node i to node j in the next layer
# 数组里的权重是wij,其中链接是从节点i到节点j的下一层
# w11 w21
# numpy.random.normal(a,b,(X,Y))的意思是生成一个随机数组,数组大小为X*Y,内容服从中心值为a,方差为b
self.wih = numpy.random.normal(
0.0, pow(self.inodes, -0.5), (self.hnodes, self.inodes))
self.who = numpy.random.normal(
0.0, pow(self.inodes, -0.5), (self.onodes, self.hnodes))
# learning rate
# 设置学习率
self.lr = learningrate
# activation function is the sigmod function
self.activation_function = lambda x: scipy.special.expit(x)
pass
# train the neural network
def train(self, inputs_list, targets_list):
# vonvert inputs list to 2d array
inputs = numpy.array(inputs_list, ndmin=2).T
targets = numpy.array(targets_list, ndmin=2).T
# calculate signals into hidden layer
# 计算隐藏层的输入
# numpy.dot(X,Y)的意思是两个数组的点乘
hidden_inputs = numpy.dot(self.wih, inputs)
# calculate the signals emerging from hidden layer
# 计算隐藏层的输出
hidden_outputs = self.activation_function(hidden_inputs)
# calculate signals into final output layer
# 计算输出层的输入
final_inputs = numpy.dot(self.who, hidden_outputs)
# calculate the signals emerging from final output layer
# 计算输出层的输出
final_outputs = self.activation_function(final_inputs)
# output layer error is the (target-actual)
# 计算输出层的误差
output_error = targets-final_outputs
# hidden layer error is the output_error, split by weight,recombined at hidden nodes
# 计算隐藏层的误差
hidden_error = numpy.dot(self.who.T, output_error)
# update the weights for the links between the hidden and output layers
# 更新隐藏层到输出层的权重
# 下面行末尾加的反斜杠\的意思是编译的时候忽略换行符
# 如果一行写不下,在代码末尾加上“\”即可
# 另外,在括号() {} [] 中的代码不需要换行符“\”,直接换行即可达到同样的效果
self.who += self.lr * \
numpy.dot((output_error*final_outputs*(1.0-final_outputs)),
numpy.transpose(hidden_outputs))
# update the weights for the links between the input and hidden layers
# 更新输入层到隐藏层的权重
self.wih += self.lr * \
numpy.dot((hidden_error*hidden_outputs *
(1.0-hidden_outputs)), numpy.transpose(inputs))
# query the neural network
def query(self, inputs_list):
# convert inputs list to 2d array
inputs = numpy.array(inputs_list, ndmin=2).T
# calculate signals into hidden layer
# 计算隐藏层的输入
# numpy.dot(X,Y)的意思是两个数组的点乘
hidden_inputs = numpy.dot(self.wih, inputs)
# calculate the signals emerging from hidden layer
# 计算隐藏层的输出
hidden_outputs = self.activation_function(hidden_inputs)
# calculate signals into final output layer
# 计算输出层的输入
final_inputs = numpy.dot(self.who, hidden_outputs)
# calculate the signals emerging from final output layer
# 计算输出层的输出
final_outputs = self.activation_function(final_inputs)
return final_outputs
# number of input, hidden and output nodes
# 设置输入,隐藏和输出层节点的数量
# 输出层有28*28=784个数据
input_nodes = 784
# 这个自己随便设的
hidden_nodes = 100
# 按本例子的的方案,输出有10中,结点有10个
output_nodes = 10
# learning rate is 0.3
# 设置学习率为0.3
learning_rate = 0.3
# create instance of neural network
# 创建一个神经网络的实例
n = neuralNetwork(input_nodes, hidden_nodes, output_nodes, learning_rate)
# load the mnist training data CSV file into a list
# 训练集有6万条,测试集有1万条
# 读文件,open函数的参数列表,第一个是要打开的文件,第二个是打开方式,这里r代表只读方式
training_data_file = open("mnist_dataset/mnist_train.csv", 'r')
# readlines()函数的意思是读取整个文件所有的内容,生成一个字符串数组,每行是一个字符串
training_data_list = training_data_file.readlines()
# 打开的文件必须close()掉,否则可能会出现各种问题。
training_data_file.close()
# train the neural network
# go through all recordes in the training data set
for record in training_data_list:
# split the record by the ',' commas
# 用逗号分隔字符串,将长的文本字符串拆分成单个的值
training_all_values = record.split(',')
# scale and shift the inputs
# 整理输入数据
training_inputs = (numpy.asfarray(training_all_values[1:])/255.0*0.99)+0.01
# PS:这里能不能不每次都设置新的target,待改进:提前设置好然后直接调用某个目标输出
# create the target output values (all 0.01, except the desired label which is 0.09)
# 生成一个长度为10的数组,然后都加0.01,这样就10个都是0.01了
training_targets = numpy.zeros(output_nodes)+0.01
# training_all_values[0] is the target label for this record
# 然后再将标签所指的那个点设成0.99即可
training_targets[int(training_all_values[0])] = 0.99
# 开始训练
n.train(training_inputs, training_targets)
pass
# 测试部分代码
# load the mnist test data CSV file into a list
# 读测试数据文件
test_data_file = open("mnist_dataset/mnist_test.csv", 'r')
test_data_list = test_data_file.readlines()
test_data_file.close()
# test the neural network
# scorecard for how well the network perform, initially empty
scorecard = []
# go through all the records in the test data set
for record in test_data_list:
# split the record by the ',' commas
all_values = record.split(',')
# correct answer is first value
correct_label = int(all_values[0])
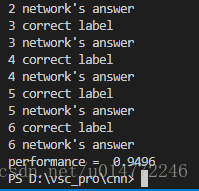
print(correct_label, "correct label")
# scale and shift the inputs
inputs = (numpy.asfarray(all_values[1:])/255.0*0.99)+0.01
# query the network
outputs = n.query(inputs)
# the index of the highest value corresponds to the label
label = numpy.argmax(outputs)
print(label, "network's answer")
# append correct or incorrect to list
if (label == correct_label):
# network's answer matches correct answer, add 1 to scorecard
scorecard.append(1)
else:
# network's answer doesn't match correct answer, add O to scorecard
scorecard.append(0)
pass
pass
# calculate the performance score, the fraction of correct answers
scorecard_array = numpy.asarray(scorecard)
print("performance = ", scorecard_array.sum()/scorecard_array.size)
2.5.3、使用完整数据集进行训练和测试
这个数据集有一种精简版的,训练集100个,测试集10个,我一开始就用的是完全版的训练集6万个,测试集1万个,所以之前写的都是完整版的。
2.5.2最后的代码就是了。
2.5.4、一些改进:调整学习率
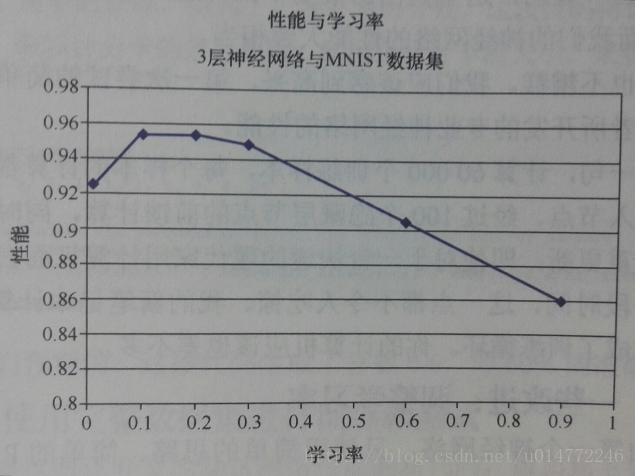
书上作者经过实验,做了不同学习率下的对比实验,画了个图标,如下:
实验的结论是:学习率在0.1和0.3之间可能会有较好的表现,因此将学习率改为0.2,准确率得到了微小的提高。
做了两个改动:
1、把学习率改成0.2
2、把输出的lable注释掉
完整代码如下:
# make your own neural network
# code for a 3-layer neural network, and code for learning the MNIST dataset
import numpy
# scipy.special for the sigmoid function expit()
import scipy.special
# library for plotting arrays
import matplotlib.pyplot
# neural network class definition
class neuralNetwork:
# initialise the neural network
# 初始化神经网络
# inputnodes,hiddennodes,outputnodes分别是输入层,隐藏层和输出层网络节点的个数
# learningrate是学习率
def __init__(self, inputnodes, hiddennodes, outputnodes, learningrate):
# set number of nodes in each input, hidden, output layer
# 设置输入,隐藏和输出层节点的数量
self.inodes = inputnodes
self.hnodes = hiddennodes
self.onodes = outputnodes
# link weight matrices, wih an who
# 链接权重矩阵
# wih是输入层和隐藏层之间的链接权重矩阵W_input_hidden
# who是输入层和隐藏层之间的链接权重矩阵W_hidden_output
# weights inside the arrays are w_i_j, where link is from node i to node j in the next layer
# 数组里的权重是wij,其中链接是从节点i到节点j的下一层
# w11 w21
# numpy.random.normal(a,b,(X,Y))的意思是生成一个随机数组,数组大小为X*Y,内容服从中心值为a,方差为b
self.wih = numpy.random.normal(
0.0, pow(self.inodes, -0.5), (self.hnodes, self.inodes))
self.who = numpy.random.normal(
0.0, pow(self.inodes, -0.5), (self.onodes, self.hnodes))
# learning rate
# 设置学习率
self.lr = learningrate
# activation function is the sigmod function
self.activation_function = lambda x: scipy.special.expit(x)
pass
# train the neural network
def train(self, inputs_list, targets_list):
# vonvert inputs list to 2d array
inputs = numpy.array(inputs_list, ndmin=2).T
targets = numpy.array(targets_list, ndmin=2).T
# calculate signals into hidden layer
# 计算隐藏层的输入
# numpy.dot(X,Y)的意思是两个数组的点乘
hidden_inputs = numpy.dot(self.wih, inputs)
# calculate the signals emerging from hidden layer
# 计算隐藏层的输出
hidden_outputs = self.activation_function(hidden_inputs)
# calculate signals into final output layer
# 计算输出层的输入
final_inputs = numpy.dot(self.who, hidden_outputs)
# calculate the signals emerging from final output layer
# 计算输出层的输出
final_outputs = self.activation_function(final_inputs)
# output layer error is the (target-actual)
# 计算输出层的误差
output_error = targets-final_outputs
# hidden layer error is the output_error, split by weight,recombined at hidden nodes
# 计算隐藏层的误差
hidden_error = numpy.dot(self.who.T, output_error)
# update the weights for the links between the hidden and output layers
# 更新隐藏层到输出层的权重
# 下面行末尾加的反斜杠\的意思是编译的时候忽略换行符
# 如果一行写不下,在代码末尾加上“\”即可
# 另外,在括号() {} [] 中的代码不需要换行符“\”,直接换行即可达到同样的效果
self.who += self.lr * \
numpy.dot((output_error*final_outputs*(1.0-final_outputs)),
numpy.transpose(hidden_outputs))
# update the weights for the links between the input and hidden layers
# 更新输入层到隐藏层的权重
self.wih += self.lr * \
numpy.dot((hidden_error*hidden_outputs *
(1.0-hidden_outputs)), numpy.transpose(inputs))
# query the neural network
def query(self, inputs_list):
# convert inputs list to 2d array
inputs = numpy.array(inputs_list, ndmin=2).T
# calculate signals into hidden layer
# 计算隐藏层的输入
# numpy.dot(X,Y)的意思是两个数组的点乘
hidden_inputs = numpy.dot(self.wih, inputs)
# calculate the signals emerging from hidden layer
# 计算隐藏层的输出
hidden_outputs = self.activation_function(hidden_inputs)
# calculate signals into final output layer
# 计算输出层的输入
final_inputs = numpy.dot(self.who, hidden_outputs)
# calculate the signals emerging from final output layer
# 计算输出层的输出
final_outputs = self.activation_function(final_inputs)
return final_outputs
# number of input, hidden and output nodes
# 设置输入,隐藏和输出层节点的数量
# 输出层有28*28=784个数据
input_nodes = 784
# 这个自己随便设的
hidden_nodes = 100
# 按本例子的的方案,输出有10中,结点有10个
output_nodes = 10
# learning rate is 0.3
# 设置学习率为0.3
learning_rate = 0.2
# create instance of neural network
# 创建一个神经网络的实例
n = neuralNetwork(input_nodes, hidden_nodes, output_nodes, learning_rate)
# load the mnist training data CSV file into a list
# 训练集有6万条,测试集有1万条
# 读文件,open函数的参数列表,第一个是要打开的文件,第二个是打开方式,这里r代表只读方式
training_data_file = open("mnist_dataset/mnist_train.csv", 'r')
# readlines()函数的意思是读取整个文件所有的内容,生成一个字符串数组,每行是一个字符串
training_data_list = training_data_file.readlines()
# 打开的文件必须close()掉,否则可能会出现各种问题。
training_data_file.close()
# train the neural network
# go through all recordes in the training data set
for record in training_data_list:
# split the record by the ',' commas
# 用逗号分隔字符串,将长的文本字符串拆分成单个的值
training_all_values = record.split(',')
# scale and shift the inputs
# 整理输入数据
training_inputs = (numpy.asfarray(training_all_values[1:])/255.0*0.99)+0.01
# PS:这里能不能不每次都设置新的target,待改进:提前设置好然后直接调用某个目标输出
# create the target output values (all 0.01, except the desired label which is 0.09)
# 生成一个长度为10的数组,然后都加0.01,这样就10个都是0.01了
training_targets = numpy.zeros(output_nodes)+0.01
# training_all_values[0] is the target label for this record
# 然后再将标签所指的那个点设成0.99即可
training_targets[int(training_all_values[0])] = 0.99
# 开始训练
n.train(training_inputs, training_targets)
pass
# 测试部分代码
# load the mnist test data CSV file into a list
# 读测试数据文件
test_data_file = open("mnist_dataset/mnist_test.csv", 'r')
test_data_list = test_data_file.readlines()
test_data_file.close()
# test the neural network
# scorecard for how well the network perform, initially empty
scorecard = []
# go through all the records in the test data set
for record in test_data_list:
# split the record by the ',' commas
all_values = record.split(',')
# correct answer is first value
correct_label = int(all_values[0])
# print(correct_label, "correct label")
# scale and shift the inputs
inputs = (numpy.asfarray(all_values[1:])/255.0*0.99)+0.01
# query the network
outputs = n.query(inputs)
# the index of the highest value corresponds to the label
label = numpy.argmax(outputs)
# print(label, "network's answer")
# append correct or incorrect to list
if (label == correct_label):
# network's answer matches correct answer, add 1 to scorecard
scorecard.append(1)
else:
# network's answer doesn't match correct answer, add O to scorecard
scorecard.append(0)
pass
pass
# calculate the performance score, the fraction of correct answers
scorecard_array = numpy.asarray(scorecard)
print("performance = ", scorecard_array.sum()/scorecard_array.size)
2.5.5、一些改进:多次进行
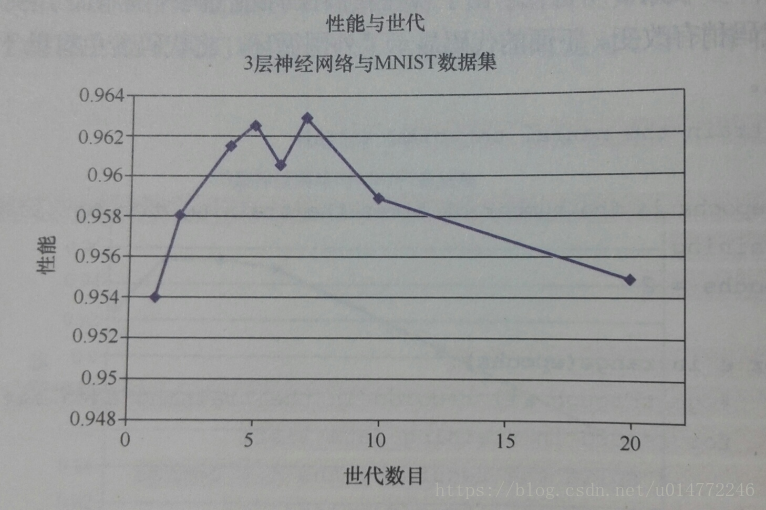
书上作者经过实验,做了不同代次下的对比实验,画了个图表,如下:
实验的结论是:随着代次的提高效果会越来越好,但是超过6次之后就会走下坡路。原因可能是过拟合了,可也能是陷入了局部最优,也可能是学习率过高了。
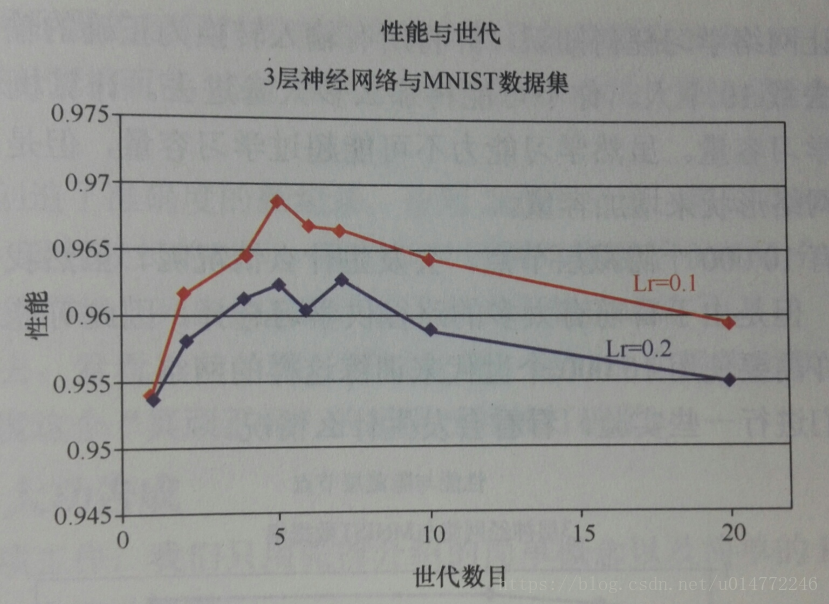
所以作者将学习率改为0.1,做了对比实验,画了个图表,如下:
实验的结论是:在较大的代数的情况下,较小的学习率表现比较好。
我的代码做了改动,加了代次的代码,让训练整个文件的数据重复执行多次,代次设定为2。
完整代码如下:
# make your own neural network
# code for a 3-layer neural network, and code for learning the MNIST dataset
import numpy
# scipy.special for the sigmoid function expit()
import scipy.special
# library for plotting arrays
import matplotlib.pyplot
# neural network class definition
class neuralNetwork:
# initialise the neural network
# 初始化神经网络
# inputnodes,hiddennodes,outputnodes分别是输入层,隐藏层和输出层网络节点的个数
# learningrate是学习率
def __init__(self, inputnodes, hiddennodes, outputnodes, learningrate):
# set number of nodes in each input, hidden, output layer
# 设置输入,隐藏和输出层节点的数量
self.inodes = inputnodes
self.hnodes = hiddennodes
self.onodes = outputnodes
# link weight matrices, wih an who
# 链接权重矩阵
# wih是输入层和隐藏层之间的链接权重矩阵W_input_hidden
# who是输入层和隐藏层之间的链接权重矩阵W_hidden_output
# weights inside the arrays are w_i_j, where link is from node i to node j in the next layer
# 数组里的权重是wij,其中链接是从节点i到节点j的下一层
# w11 w21
# numpy.random.normal(a,b,(X,Y))的意思是生成一个随机数组,数组大小为X*Y,内容服从中心值为a,方差为b
self.wih = numpy.random.normal(
0.0, pow(self.inodes, -0.5), (self.hnodes, self.inodes))
self.who = numpy.random.normal(
0.0, pow(self.inodes, -0.5), (self.onodes, self.hnodes))
# learning rate
# 设置学习率
self.lr = learningrate
# activation function is the sigmod function
self.activation_function = lambda x: scipy.special.expit(x)
pass
# train the neural network
def train(self, inputs_list, targets_list):
# vonvert inputs list to 2d array
inputs = numpy.array(inputs_list, ndmin=2).T
targets = numpy.array(targets_list, ndmin=2).T
# calculate signals into hidden layer
# 计算隐藏层的输入
# numpy.dot(X,Y)的意思是两个数组的点乘
hidden_inputs = numpy.dot(self.wih, inputs)
# calculate the signals emerging from hidden layer
# 计算隐藏层的输出
hidden_outputs = self.activation_function(hidden_inputs)
# calculate signals into final output layer
# 计算输出层的输入
final_inputs = numpy.dot(self.who, hidden_outputs)
# calculate the signals emerging from final output layer
# 计算输出层的输出
final_outputs = self.activation_function(final_inputs)
# output layer error is the (target-actual)
# 计算输出层的误差
output_error = targets-final_outputs
# hidden layer error is the output_error, split by weight,recombined at hidden nodes
# 计算隐藏层的误差
hidden_error = numpy.dot(self.who.T, output_error)
# update the weights for the links between the hidden and output layers
# 更新隐藏层到输出层的权重
# 下面行末尾加的反斜杠\的意思是编译的时候忽略换行符
# 如果一行写不下,在代码末尾加上“\”即可
# 另外,在括号() {} [] 中的代码不需要换行符“\”,直接换行即可达到同样的效果
self.who += self.lr * \
numpy.dot((output_error*final_outputs*(1.0-final_outputs)),
numpy.transpose(hidden_outputs))
# update the weights for the links between the input and hidden layers
# 更新输入层到隐藏层的权重
self.wih += self.lr * \
numpy.dot((hidden_error*hidden_outputs *
(1.0-hidden_outputs)), numpy.transpose(inputs))
# query the neural network
def query(self, inputs_list):
# convert inputs list to 2d array
inputs = numpy.array(inputs_list, ndmin=2).T
# calculate signals into hidden layer
# 计算隐藏层的输入
# numpy.dot(X,Y)的意思是两个数组的点乘
hidden_inputs = numpy.dot(self.wih, inputs)
# calculate the signals emerging from hidden layer
# 计算隐藏层的输出
hidden_outputs = self.activation_function(hidden_inputs)
# calculate signals into final output layer
# 计算输出层的输入
final_inputs = numpy.dot(self.who, hidden_outputs)
# calculate the signals emerging from final output layer
# 计算输出层的输出
final_outputs = self.activation_function(final_inputs)
return final_outputs
# number of input, hidden and output nodes
# 设置输入,隐藏和输出层节点的数量
# 输出层有28*28=784个数据
input_nodes = 784
# 这个自己随便设的
hidden_nodes = 100
# 按本例子的的方案,输出有10中,结点有10个
output_nodes = 10
# learning rate is 0.3
# 设置学习率为0.3
learning_rate = 0.3
# create instance of neural network
# 创建一个神经网络的实例
n = neuralNetwork(input_nodes, hidden_nodes, output_nodes, learning_rate)
# load the mnist training data CSV file into a list
# 训练集有6万条,测试集有1万条
# 读文件,open函数的参数列表,第一个是要打开的文件,第二个是打开方式,这里r代表只读方式
training_data_file = open("mnist_dataset/mnist_train.csv", 'r')
# readlines()函数的意思是读取整个文件所有的内容,生成一个字符串数组,每行是一个字符串
training_data_list = training_data_file.readlines()
# 打开的文件必须close()掉,否则可能会出现各种问题。
training_data_file.close()
epochs = 2
# train the neural network
for e in range(epochs):
# go through all recordes in the training data set
for record in training_data_list:
# split the record by the ',' commas
# 用逗号分隔字符串,将长的文本字符串拆分成单个的值
training_all_values = record.split(',')
# scale and shift the inputs
# 整理输入数据
training_inputs = (numpy.asfarray(
training_all_values[1:])/255.0*0.99)+0.01
# PS:这里能不能不每次都设置新的target,待改进:提前设置好然后直接调用某个目标输出
# create the target output values (all 0.01, except the desired label which is 0.09)
# 生成一个长度为10的数组,然后都加0.01,这样就10个都是0.01了
training_targets = numpy.zeros(output_nodes)+0.01
# training_all_values[0] is the target label for this record
# 然后再将标签所指的那个点设成0.99即可
training_targets[int(training_all_values[0])] = 0.99
# 开始训练
n.train(training_inputs, training_targets)
pass
pass
# 测试部分代码
# load the mnist test data CSV file into a list
# 读测试数据文件
test_data_file = open("mnist_dataset/mnist_test.csv", 'r')
test_data_list = test_data_file.readlines()
test_data_file.close()
# test the neural network
# scorecard for how well the network perform, initially empty
scorecard = []
# go through all the records in the test data set
for record in test_data_list:
# split the record by the ',' commas
all_values = record.split(',')
# correct answer is first value
correct_label = int(all_values[0])
print(correct_label, "correct label")
# scale and shift the inputs
inputs = (numpy.asfarray(all_values[1:])/255.0*0.99)+0.01
# query the network
outputs = n.query(inputs)
# the index of the highest value corresponds to the label
label = numpy.argmax(outputs)
print(label, "network's answer")
# append correct or incorrect to list
if (label == correct_label):
# network's answer matches correct answer, add 1 to scorecard
scorecard.append(1)
else:
# network's answer doesn't match correct answer, add O to scorecard
scorecard.append(0)
pass
pass
# calculate the performance score, the fraction of correct answers
scorecard_array = numpy.asarray(scorecard)
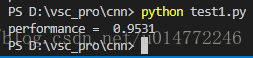
print("performance = ", scorecard_array.sum()/scorecard_array.size)
2.5.6、改变网络形状
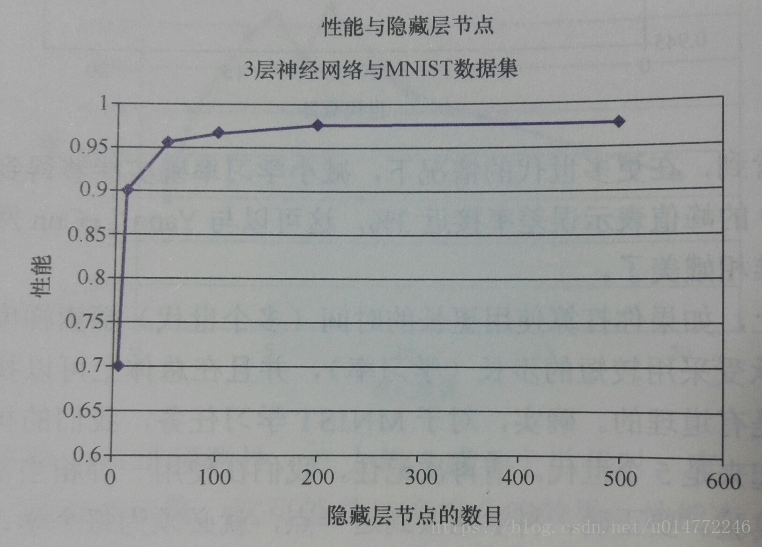
书上作者经过实验,对隐藏节点的不同做了对比实验,画了个图表,如下:
实验的结论是:随着隐藏层节点数量的增加,实验的准确率有了一些提高,但是效果不显著,而且产生了很多额外的计算量,因此训练的时间也显著增加了。
因此,必须在我们可以容忍的时间内选择某个数目的隐藏层节点。
我把隐藏层节点改成200,代码就不贴了,运行结果如下:
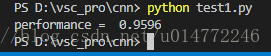
2.5.7、大功告成
回顾这项工作,当遇到不同问题时,我们可以做如下改动,来达到期望的效果:
1、改变神经网络的层数
2、改变中间层节点的数目
3、用不同的激活函数
4、用不同的学习率
5、甚至用变化的学习率,将学习率和某些参数联系起来
6、多次训练
7、改变每次训练的数量(每批个数)
8、改变数据集
或者:
1、更换配置更好的电脑(我已经做了。。。)
2、使用GPU加速(计划搞一搞,用NVIDIA的cube来做,具体的还没搞)
2.5.8、最终代码
最终的代码上上一节的末尾已经给出,这里就不再写了。
另外,这一节我发现在每次训练的时候,都得重新训练各个权重,能不能把每次训练好的各个权重都线起来,然后下次训练的时候调用,以便接着训练,或者测试的时候,直接调用这些链接权重,就免去了在此训练的时间。
1、存入csv
工作的主要内容是讲两个权重数组在训练的过程中存入csv文件中:
numpy.savetxt("who.csv", n.who,delimiter = ',')
numpy.savetxt("wih.csv", n.wih,delimiter = ',')
2、改进的存入
本来这里写的是每次训练一个就存一次,后来发现对硬盘的读写耗费太大,遂作罢。
然后,在整个循环外加了个no变量,用来记录次数,然后每训练3000次给权重文件更新一次数据。
if (no % 3000) == 0:
numpy.savetxt("who.csv", n.who,delimiter = ',')
numpy.savetxt("wih.csv", n.wih,delimiter = ',')
print(no)
no += 1
3、从csv文件中取出数据
self.wih = numpy.loadtxt(open("wih.csv","rb"),delimiter=",",skiprows=0)
self.who = numpy.loadtxt(open("who.csv","rb"),delimiter=",",skiprows=0)
4、但是本来就没有这个文件,也没有这个数据,所以得线判断一下是否存在,如果不存在,还是按照原来的随机化一个数组出来
# 如果有存入文件的权值,就使用,否自初始化一个
if os.access("wih.csv", os.F_OK):
self.wih = numpy.loadtxt(open("wih.csv","rb"),delimiter=",",skiprows=0)
else:
self.wih = numpy.random.normal(
0.0, pow(self.inodes, -0.5), (self.hnodes, self.inodes))
if os.access("who.csv", os.F_OK):
self.who = numpy.loadtxt(open("who.csv","rb"),delimiter=",",skiprows=0)
else:
self.who = numpy.random.normal(
0.0, pow(self.inodes, -0.5), (self.onodes, self.hnodes))
5、上面的取参数的代码当然是放在类初始化的函数里。
完整代码如下:
# 第二章结束后自己修改了作者的完整的代码后最终的代码
# make your own neural network
# code for a 3-layer neural network, and code for learning the MNIST dataset
import numpy
# scipy.special for the sigmoid function expit()
import scipy.special
# library for plotting arrays
import matplotlib.pyplot
# 这个用于判读文件是否存在
import os
# neural network class definition
class neuralNetwork:
# initialise the neural network
# 初始化神经网络
# inputnodes,hiddennodes,outputnodes分别是输入层,隐藏层和输出层网络节点的个数
# learningrate是学习率
def __init__(self, inputnodes, hiddennodes, outputnodes, learningrate):
# set number of nodes in each input, hidden, output layer
# 设置输入,隐藏和输出层节点的数量
self.inodes = inputnodes
self.hnodes = hiddennodes
self.onodes = outputnodes
# link weight matrices, wih an who
# 链接权重矩阵
# wih是输入层和隐藏层之间的链接权重矩阵W_input_hidden
# who是输入层和隐藏层之间的链接权重矩阵W_hidden_output
# weights inside the arrays are w_i_j, where link is from node i to node j in the next layer
# 数组里的权重是wij,其中链接是从节点i到节点j的下一层
# w11 w21
# numpy.random.normal(a,b,(X,Y))的意思是生成一个随机数组,数组大小为X*Y,内容服从中心值为a,方差为b
# 如果有存入文件的权值,就使用,否自初始化一个
if os.access("wih.csv", os.F_OK):
self.wih = numpy.loadtxt(open("wih.csv","rb"),delimiter=",",skiprows=0)
else:
self.wih = numpy.random.normal(
0.0, pow(self.inodes, -0.5), (self.hnodes, self.inodes))
if os.access("who.csv", os.F_OK):
self.who = numpy.loadtxt(open("who.csv","rb"),delimiter=",",skiprows=0)
else:
self.who = numpy.random.normal(
0.0, pow(self.inodes, -0.5), (self.onodes, self.hnodes))
# learning rate
# 设置学习率
self.lr = learningrate
# activation function is the sigmod function
self.activation_function = lambda x: scipy.special.expit(x)
pass
# train the neural network
def train(self, inputs_list, targets_list):
# vonvert inputs list to 2d array
inputs = numpy.array(inputs_list, ndmin=2).T
targets = numpy.array(targets_list, ndmin=2).T
# calculate signals into hidden layer
# 计算隐藏层的输入
# numpy.dot(X,Y)的意思是两个数组的点乘
hidden_inputs = numpy.dot(self.wih, inputs)
# calculate the signals emerging from hidden layer
# 计算隐藏层的输出
hidden_outputs = self.activation_function(hidden_inputs)
# calculate signals into final output layer
# 计算输出层的输入
final_inputs = numpy.dot(self.who, hidden_outputs)
# calculate the signals emerging from final output layer
# 计算输出层的输出
final_outputs = self.activation_function(final_inputs)
# output layer error is the (target-actual)
# 计算输出层的误差
output_error = targets-final_outputs
# hidden layer error is the output_error, split by weight,recombined at hidden nodes
# 计算隐藏层的误差
hidden_error = numpy.dot(self.who.T, output_error)
# update the weights for the links between the hidden and output layers
# 更新隐藏层到输出层的权重
# 下面行末尾加的反斜杠\的意思是编译的时候忽略换行符
# 如果一行写不下,在代码末尾加上“\”即可
# 另外,在括号() {} [] 中的代码不需要换行符“\”,直接换行即可达到同样的效果
self.who += self.lr * \
numpy.dot((output_error*final_outputs*(1.0-final_outputs)),
numpy.transpose(hidden_outputs))
# update the weights for the links between the input and hidden layers
# 更新输入层到隐藏层的权重
self.wih += self.lr * \
numpy.dot((hidden_error*hidden_outputs *
(1.0-hidden_outputs)), numpy.transpose(inputs))
pass
# query the neural network
def query(self, inputs_list):
# convert inputs list to 2d array
inputs = numpy.array(inputs_list, ndmin=2).T
# calculate signals into hidden layer
# 计算隐藏层的输入
# numpy.dot(X,Y)的意思是两个数组的点乘
hidden_inputs = numpy.dot(self.wih, inputs)
# calculate the signals emerging from hidden layer
# 计算隐藏层的输出
hidden_outputs = self.activation_function(hidden_inputs)
# calculate signals into final output layer
# 计算输出层的输入
final_inputs = numpy.dot(self.who, hidden_outputs)
# calculate the signals emerging from final output layer
# 计算输出层的输出
final_outputs = self.activation_function(final_inputs)
return final_outputs
# number of input, hidden and output nodes
# 设置输入,隐藏和输出层节点的数量
# 输出层有28*28=784个数据
input_nodes = 784
# 这个自己随便设的
hidden_nodes = 200
# 按本例子的的方案,输出有10中,结点有10个
output_nodes = 10
# learning rate is 0.2
# 设置学习率为0.2
learning_rate = 0.2
# create instance of neural network
# 创建一个神经网络的实例
n = neuralNetwork(input_nodes, hidden_nodes, output_nodes, learning_rate)
# load the mnist training data CSV file into a list
# 训练集有6万条,测试集有1万条
# 读文件,open函数的参数列表,第一个是要打开的文件,第二个是打开方式,这里r代表只读方式
training_data_file = open("mnist_dataset/mnist_train.csv", 'r')
# readlines()函数的意思是读取整个文件所有的内容,生成一个字符串数组,每行是一个字符串
training_data_list = training_data_file.readlines()
# 打开的文件必须close()掉,否则可能会出现各种问题。
training_data_file.close()
epochs = 3
# train the neural network
for e in range(epochs):
no = 0
# go through all recordes in the training data set
for record in training_data_list:
# split the record by the ',' commas
# 用逗号分隔字符串,将长的文本字符串拆分成单个的值
training_all_values = record.split(',')
# scale and shift the inputs
# 整理输入数据
training_inputs = (numpy.asfarray(
training_all_values[1:])/255.0*0.99)+0.01
# PS:这里能不能不每次都设置新的target,待改进:提前设置好然后直接调用某个目标输出
# create the target output values (all 0.01, except the desired label which is 0.09)
# 生成一个长度为10的数组,然后都加0.01,这样就10个都是0.01了
training_targets = numpy.zeros(output_nodes)+0.01
# training_all_values[0] is the target label for this record
# 然后再将标签所指的那个点设成0.99即可
training_targets[int(training_all_values[0])] = 0.99
# 开始训练
n.train(training_inputs, training_targets)
# 将更新后的权值放入文件中
if (no % 3000) == 0:
numpy.savetxt("who.csv", n.who,delimiter = ',')
numpy.savetxt("wih.csv", n.wih,delimiter = ',')
print(no)
no += 1
pass
pass
# 测试部分代码
# load the mnist test data CSV file into a list
# 读测试数据文件
test_data_file = open("mnist_dataset/mnist_test.csv", 'r')
test_data_list = test_data_file.readlines()
test_data_file.close()
# test the neural network
# scorecard for how well the network perform, initially empty
scorecard = []
# go through all the records in the test data set
for record in test_data_list:
# split the record by the ',' commas
all_values = record.split(',')
# correct answer is first value
correct_label = int(all_values[0])
# print(correct_label, "correct label")
# scale and shift the inputs
inputs = (numpy.asfarray(all_values[1:])/255.0*0.99)+0.01
# query the network
outputs = n.query(inputs)
# the index of the highest value corresponds to the label
label = numpy.argmax(outputs)
# print(label, "network's answer")
# append correct or incorrect to list
if (label == correct_label):
# network's answer matches correct answer, add 1 to scorecard
scorecard.append(1)
else:
# network's answer doesn't match correct answer, add O to scorecard
scorecard.append(0)
pass
pass
# calculate the performance score, the fraction of correct answers
scorecard_array = numpy.asarray(scorecard)
print("performance = ", scorecard_array.sum()/scorecard_array.size)
另:一些说明
1、本博客仅用于学习交流,欢迎大家瞧瞧看看,为了方便大家学习。
2、如果原作者认为侵权,请及时联系我,我的qq是244509154,邮箱是[email protected],我会及时删除侵权文章。
3、我的文章大家如果觉得对您有帮助或者您喜欢,请您在转载的时候请注明来源,不管是我的还是其他原作者,我希望这些有用的文章的作者能被大家记住。
4、最后希望大家多多的交流,提高自己,从而对社会和自己创造更大的价值。