全文检索
数据分类:
- 结构化数据:格式、长度、类型等固定,如数据库中的数据
- 非结构化数据:格式、长度、类型等不固定,如pdf、html文件
数据查询: - 结构化数据:sql语句
- 非结构化数据:将非结构化数据转换为结构化数据,建立索引然后查询
全文检索就是先创建索引然后查询索引的过程
全文检索的应用场景:
- 搜索引擎,如百度、谷歌
- 站内搜索,如微博、csdn文章
- 电商搜索,如淘宝、京东
- 等等
Lucene简介
Lucene是一个基于Java开发的开源全文检索引擎工具包,但它不是一个完整的全文检索引擎,而是一个全文检索引擎的架构,提供了完整的查询引擎和索引引擎,部分文本分析引擎。
Lucene的目的是为软件开发人员提供一个简单易用的工具包,以方便的在目标系统中实现全文检索的功能,或者是以此为基础建立起完整的全文检索引擎。
Lucene提供了一个简单却强大的应用程式接口,能够做全文索引和搜寻。
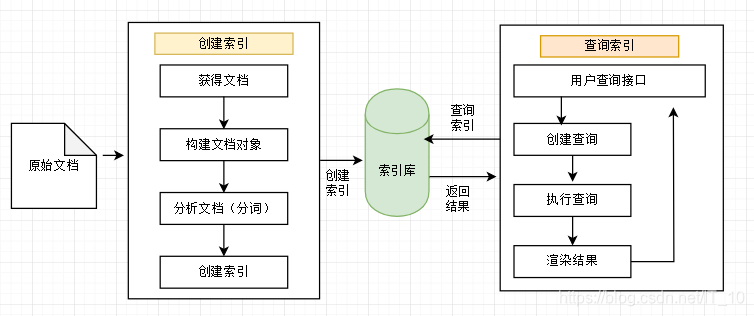
Lucene实现全文检索流程
上面说到全文检索就是先创建索引然后查询索引的过程,Lucene实现全文检索就是需要创建索引和查询索引。
使用Lucene
创建索引
需要的jar包:
- commons-io-2.6.jar
- junit-4.10.jar
- lucene-analyzers-common-7.4.0.jar
- lucene-core-7.4.0.jar
测试用的原始文档D:\java\project\searchsource:
//test1.txt
I want to learn Spring Framework.
//test2.txt
hi 我想学spring框架
//test3.txt
结构化数据:指具有固定格式或有限长度的数据,如数据库元数据等
非结构化数据:指不定长或无固定格式的数据,如邮件,word文档等
//test4.txt
Lucene Change Log
For more information on past and future Lucene versions, please see:
http://s.apache.org/luceneversions
======================= Lucene 4.10.3 ======================
测试程序,生成索引:
public class LuceneTest1 {
@Test
public void createIndex() throws IOException {
//1.创建一个Director对象,指定索引库保存的位置
//把索引保存在内存中
//Directory directory = new RAMDirectory();
//或者把索引保存在磁盘上
Directory directory = FSDirectory.open(new File("D:\\java\\project\\index").toPath());
//2.基于Directory对象创建一个IndexWrite对象
IndexWriter indexWriter = new IndexWriter(directory, new IndexWriterConfig());
//3.读取磁盘上的文件,对应每个文件创建一个文档对象
File dir = new File("D:\\java\\project\\searchsource");
File[] files = dir.listFiles();
assert files != null;
for (File file : files) {
//取文件名
String fileName = file.getName();
//文件的路径
String filePath = file.getPath();
//文件的内容
String fileContent = FileUtils.readFileToString(file, "utf-8");
//文件大小
long fileSize = FileUtils.sizeOf(file);
//创建文档对象
Field fieldName = new TextField("name", fileName, Field.Store.YES);
Field fieldPath = new TextField("path", filePath, Field.Store.YES);
Field fieldContent = new TextField("content", fileContent, Field.Store.YES);
Field fieldSize = new TextField("size", fileSize + "", Field.Store.YES);
//向文档对象中添加域
Document document = new Document();
document.add(fieldName);
document.add(fieldPath);
document.add(fieldContent);
document.add(fieldSize);
//4.把文档对象写入索引库
indexWriter.addDocument(document);
}
//5.关闭indexwriter对象
indexWriter.close();
}
}
测试通过会生成索引文件D:\java\project\index:
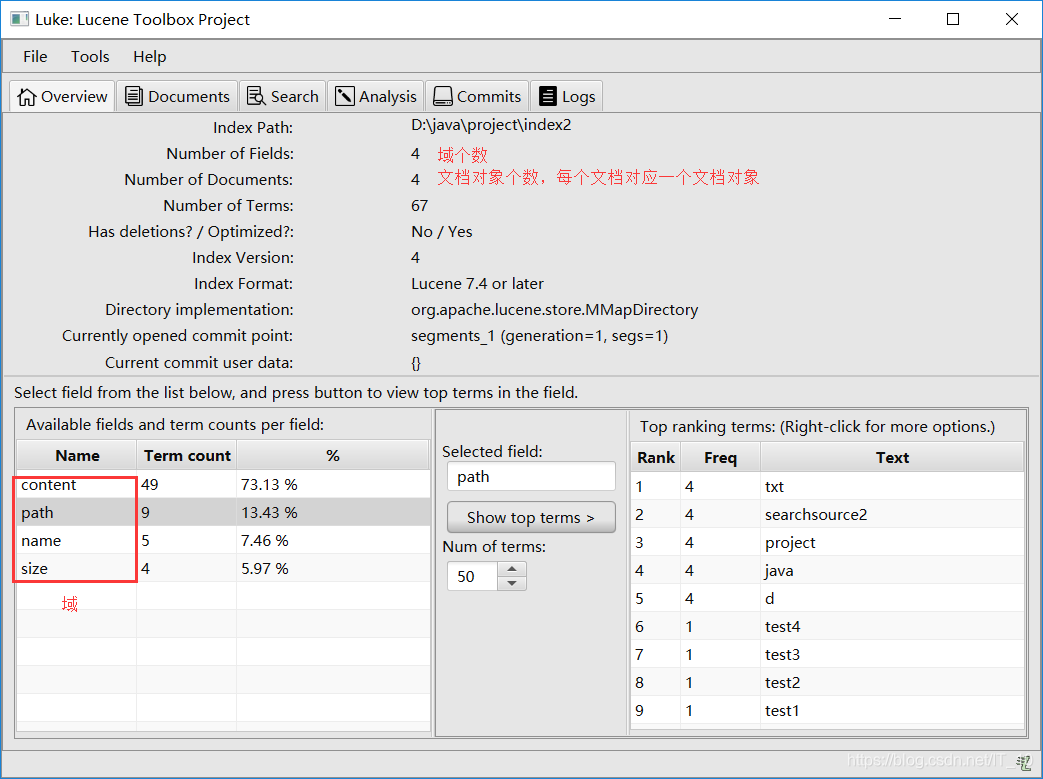
里面是二进制格式,可以使用Luke(下载地址:http://www.getopt.org/luke/)查看:
查询索引库
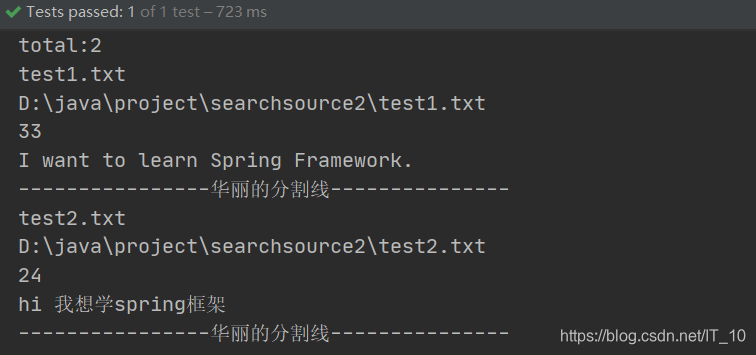
查询上述四个文档中包含有“spring”关键词的文档:
@Test
public void searchIndex() throws IOException {
//1.创建一个Director对象
Directory directory = FSDirectory.open(new File("D:\\java\\project\\index").toPath());
//2.创建一个IndexReader对象
IndexReader indexReader = DirectoryReader.open(directory);
//3.创建一个IndexSearcher对象
IndexSearcher indexSearcher = new IndexSearcher(indexReader);
//4.创建一个Query对象(查找content域中包含"spring"关键字的文档)
Query query = new TermQuery(new Term("content", "spring"));
//5.执行查询,最大返回10条数据
TopDocs topDocs = indexSearcher.search(query, 10);
//6.取查询结果的总记录数
System.out.println("total:" + topDocs.totalHits);
//7.取文档列表
ScoreDoc[] scoreDocs = topDocs.scoreDocs;
//8.打印文档内容
for (ScoreDoc scoreDoc : scoreDocs) {
//取文档id
int docId = scoreDoc.doc;
//根据id取文档对象
Document document = indexSearcher.doc(docId);
System.out.println(document.get("name"));
System.out.println(document.get("path"));
System.out.println(document.get("size"));
System.out.println(document.get("content"));
System.out.println("----------------华丽的分割线---------------");
}
//9.关闭indexReader
indexReader.close();
}
Lucene流程再分析
构建文档对象
将原始内容创建成文档(Document),文档中包括一个一个的域(Field),域中存储内容。可以将磁盘上的一个文件当成一个document,Document中包括一些Field(file_name文件名称、file_path文件路径、file_size文件大小、file_content文件内容),如下图:

文档分析
- 如果是英文,则以空格分隔,如果是汉字,则以一个汉字分隔(标准分析器StandardAnalyzer的分词方法,后面还会讲到专门的中文分析器)
- 去除无用词(如下面测试文档中的
“*-/) - 去除标点符号
- 英文字母大写转小写
@Test
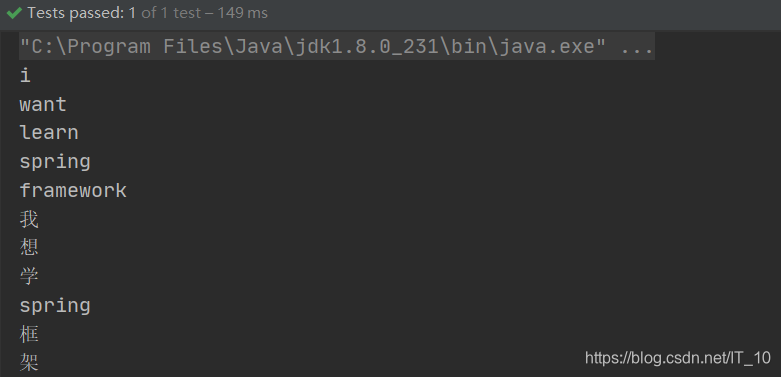
public void testTokenStream() throws Exception {
//1)创建一个Analyzer对象,StandardAnalyzer对象
Analyzer analyzer = new StandardAnalyzer();
//2)使用分析器对象的tokenStream方法获得一个TokenStream对象
TokenStream tokenStream = analyzer.tokenStream("", "I want to learn Spring Framework. 我想学spring框架, “*-/");
//3)向TokenStream对象中设置一个引用,相当于数一个指针
CharTermAttribute charTermAttribute = tokenStream.addAttribute(CharTermAttribute.class);
//4)调用TokenStream对象的rest方法。如果不调用抛异常
tokenStream.reset();
//5)使用while循环遍历TokenStream对象
while(tokenStream.incrementToken()) {
System.out.println(charTermAttribute.toString());
}
//6)关闭TokenStream对象
tokenStream.close();
}
创建索引
对所有文档分析得出的语汇单元进行索引,索引的目的是为了搜索,最终要实现只搜索被索引的语汇单元从而找到Document(文档)。
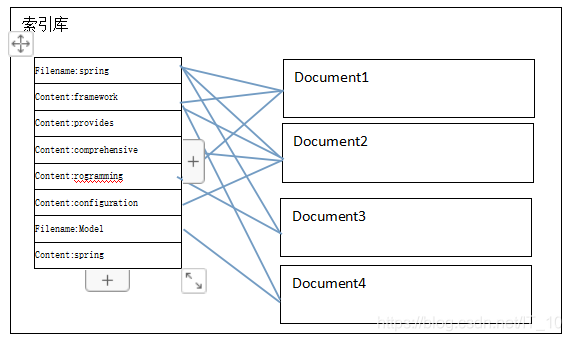
倒排索引结构是根据内容(词语)找文档。倒排索引结构也叫反向索引结构,包括索引和文档两部分,索引即词汇表,它的规模较小,而文档集合较大。如下图,包含“handoop”关键词的文档有35,77,100(生成文档时就生成的文档id),通过查询文档词汇表就能查询到那些文档包含了我们需要搜索的关键词。

中文分析器
上面分析器的实例代码中,使用的是标准的分析器StandardAnalyzer,可以看到有一个缺点是中文被按照一个汉字分割的,这显然不符合我们的需求,比如将searchIndex()测试方法中的搜索“spring”改为“框架”,得到的结果数为0。这时候就需要使用“中文分析器”,这里使用IKAnalyzer中文分析器:
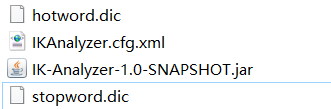
hotword.dic中保存了一些新词、热词
stopword.dic中保存了一些停用词(无用词,分词的时候会忽略掉这些词)、敏感词
将dic、xml三个文件放到类路径下,并引入jar包,将testTokenStream()方法中的Analyzer analyzer = new StandardAnalyzer()替换成Analyzer analyzer = new IKAnalyzer();。分析的文档内容为"我想学spring框架, “*-/"