HSQL之窗口, 聚合和分析函数
HSQL是大数据面试中必须具备的能力, 这里将用一个案例串通这三个常用且难点函数. 学习Hsql, 多敲多练, 方能熟能生巧.
1.创建hive表:
create table window_function_temp(uname string, create_time string,pv string);
2.初始化测试数据:
insert overwrite table dw_tmp.window_function_temp
select
split(detail,',')[0] as uname
,split(detail,',')[1] as create_time
,split(detail,',')[2] as pv
from
(
select
concat('测试用户,2019-10-02,7
#测试用户,2019-10-05,4
#测试用户,2019-10-07,5
#测试用户,2019-10-03,6
#测试用户,2019-10-04,3
#测试用户,2019-10-01,3
#测试用户,2019-10-06,4') as ct_str
) t
lateral view explode(split(ct_str,'#')) t2 as detail;
这里扩展一下里面的重要函数:
split()函数是用于切分数据,也就是将一串字符串切割成了一个数组 ;
explode()函数用于打散行的函数(将一行的数据拆分成多行,它的参数必须为map或array)。这个函数常和split()并用
lateral view :全连接. 一个select后面只能获得一个explode产生的视图,如果要显示多个列,则需要将多个视图合并。
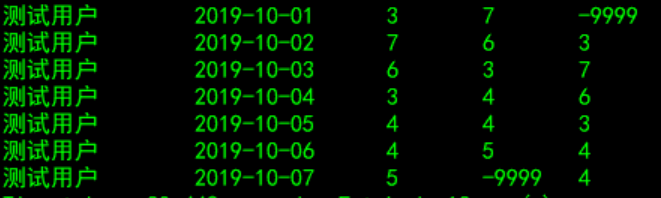
3.窗口函数: lead(col,n,default)和 lag(col,n,default)
lead用于统计窗口内往下第n行值第一个参数为列名,第二个参数为往下第n行(可选,默认为1,不可为负数),第三个参数为默认值(当往下第n行为null时候,取默认值,如不指定,则为null)
lag用于统计窗口内往上第n行值第一个参数为列名,第二个参数为往上第n行(可选,默认为1,不可为负数),第三个参数为默认值(当往上第n行为null时候,取默认值,如不指定,则为null)
select
uname
,create_time
,pv
,lead(pv,1,-9999) over (partition by uname order by create_time) as lead_1_pv
,lag(pv,1,-9999) over (partition by uname order by create_time) as lag_1_pv
from dw_tmp.window_function_temp;
4.first_value和last_value
first_value取分组内排序后,截止到当前行,第一个值,这最多需要两个参数。第一个参数是您想要第一个值的列,第二个(可选)参数必须是false默认为布尔值的布尔值。如果设置为true,则跳过空值。
last_value取分组内排序后,截止到当前行,最后一个值,这最多需要两个参数。第一个参数是您想要第一个值的列,第二个(可选)参数必须是false默认为布尔值的布尔值。如果设置为true,则跳过空值。
following: 往后
current row:当前行
unbounded:起点(一般结合preceding,following使用)
unbounded preceding 表示该窗口最前面的行(起点)
unbounded following:表示该窗口最后面的行(终点)
select
uname
,create_time
,pv
,first_value(pv) over (partition by uname order by create_time rows between unbounded preceding and current row) as first_value_pv
,last_value(pv) over (partition by uname order by create_time rows between unbounded preceding and current row) as last_value_pv
from dw_tmp.window_function_temp;
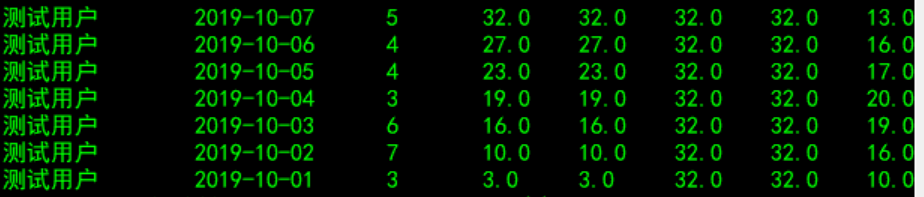
5.聚合函数:count(), sum(), min(), max, avg()
select
uname
,create_time
,pv
,SUM(pv) over (partition by uname order by create_time) as sum_pv_1 --默认情况
,SUM(pv) over (partition by uname order by create_time ROWS BETWEEN UNBOUNDED PRECEDING AND CURRENT ROW) as sum_pv_2 --表示从起点到当前行
,SUM(pv) over (partition by uname) as sum_pv_3 --表示窗口内所有行
,SUM(pv) over (partition by uname order by create_time ROWS BETWEEN UNBOUNDED PRECEDING AND UNBOUNDED FOLLOWING) as sum_pv_4 --表示起点到终点
,SUM(pv) over (partition by uname order by create_time ROWS BETWEEN 2 PRECEDING AND 1 FOLLOWING) as sum_pv_5 --表示前2行到后面1行
from dw_tmp.window_function_temp;
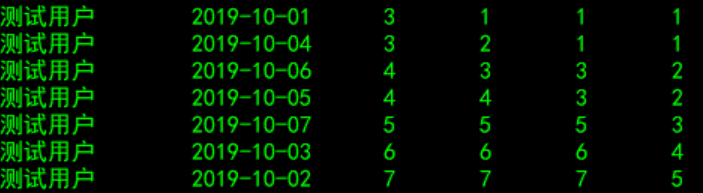
6.分析函数: row_number, rank, dense_rank, cume_dist, percent_rank, ntile
row_number:从1开始,按照顺序,生成分组内记录的序列,row_number()的值不会存在重复,当排序的值相同时,按照表中记录的顺序进行排列;通常用于获取分组内排序第一的记录;
rank: 生成数据项在分组中的排名,排名相等会在名次中留下空位
dense_rank: 生成数据项在分组中的排名,排名相等会在名次中不会留下空位
cume_dist: 小于等于当前值的行数/分组内总行数
percent_rank: 分组内当前行的RANK值-1/分组内总行数-1
ntile: NTILE(n) 用于将分组数据按照顺序切分成n片,返回当前切片值,如果切片不均匀,默认增加第一个切片的分布。ntile不支持rows between
select
uname
,create_time
,pv
,ROW_NUMBER() over (partition by uname order by pv) as row_number_pv_1
,RANK() over (partition by uname order by pv) as row_number_pv_2
,DENSE_RANK() over (partition by uname order by pv) as row_number_pv_3
from dw_tmp.window_function_temp;