从这篇博客开始,我将比较系统的讲解机器学习的相关知识,博客内容来自本人看过的书籍,视频教程(占大多数),其它博客,以及自己在实际项目过程中的思考和总结。写博客的初衷是与大家一起交流技术,共同进步。因为本人水平有限,可能部分理解会有错误,还请读者发现之后可以及时告知,另外机器学习是一个比较大的领域,因此本系列博客会不断更新,欢迎参考阅读。
涉及内容
机器学习相关概念
机器学习过程
输入大量的学习资料(数据) 到机器学习算法中,产生一个模型,模型可以对输入的样例进行预测,得到预测的结果。图示如下:
数据相关
-
数据集:数据的整体叫做数据集 (dataset)
-
样本: 每一行数据称为一个样本(sample)
-
特征:样本中每一项代表样本的一个特征 (feature)
-
示例:
上面是一个成绩评定标准表格,表格整体就是一个数据集,每一行代表一个样本,除了最后的级别列,每一列代表一个特征。最后一列通常称为标记(label) 。数学 语文 英语 级别 100 95 100 学神 90 90 90 学霸 85 85 85 优秀 80 75 70 普通 60 60 60 学渣
通常将除了 最后的级别列的数据集用一个矩阵 X 表示 ,而标记列(本例中就是级别列)用y 表示。(通常用大写字母表示矩阵,用小写字母表示向量)第i 个样本写作 ,第i 个样本的第j 个特征值为 。第i个样本的标记为 。 -
特征空间:每一个样本 都是由特征组成的空间的一个点,这个空间就是特征空间。
-
注意事项:
在上面的例子中,每一个样本的特征都有具体的语义(代表着各个科目的成绩信息),其实特征可以很抽象,例如图像数据,每一个像素点都可以作为一个特征,比如 28 × 28 大小的手写数字黑白图片,一共有 784 个特征(彩色图像特征会更多)。直观上,图片上某一位置的像素值大小与最终图像绘制的是数字几好像没有什么关系,但是机器学习的神奇之处就是可以通过一些方法来学到某种关系,这在人类看来是不好解释的。
机器学习的基本任务
分类任务
例如判断一张图像是猫还是狗,手写数字图像上的数字是几,一封邮件是否是垃圾邮件等
-
二分类任务
就是二选一的分类,最终的类别只有两个,例如垃圾邮件识别,猫狗识别,肿瘤良性还是恶性,预测股票涨还是跌等。 -
多分类任务
最终的列别不是简单的两个,而是有多个,最典型的就是手写数字识别,最终的类别有 10 个,0-9 。复杂图像识别,成绩评级(A-D)等。 -
多标签分类
简单的分类任务只能将一张图像分类到一个类别中。目前比较前沿的研究方向是多标签分类,可以将一张图像分类到多个类别中,例如一张有猫和狗的图像,既可以分类到猫类,也可以分类到狗类;一张人打网球的图片可以提取出 网球,人,网球衣,网球场地等类别,这种多标签分类可以提取出图片的语义信息。
回归任务
- 结果是一个连续数字的值,并非一个类别。例如房屋价格预测,市场分析预测,学生成绩预测,股票价格预测。
- 一些回归任务可以简化为分类任务,例如预测学生成绩,简化为预测学生成绩的级别,是A,B,还是C等。
机器学习算法的分类
在机器学习算法方面,可以将来机器学习分为四类:监督学习,非监督学习,半监督学习,增强学习
-
监督学习:
给机器的训练数据拥有标记或者答案。例如手写数字图片,猫狗识别等。
- 例子:图像拥有标记信息,银行积累了一定的客户信息和他们的信用卡信用情况,医院已经积累了一定的病人信息和他们最终是否患病的情况,市场积累了房屋的基本信息和最终成交的金额信息。
- 监督主要用于分类任务和回归任务
-
非监督学习
给机器的训练数据没有标记信息。
- 通常用于对没有标记的数据进行分类-聚类分析。例如电商网站在初次访问的时候用户是没有标记的,但是随着购买记录的增加,后台可以使用非监督聚类分析来将用户分类到某一群体,这一群体具有相似的购物需求或者习惯,方便后续的推荐促销等。
- 另外一个非常重要的工作是对数据进行降维。主要包含两方面内容,首先是特征提取,(输入数据可能有很多的特征,但是并不是所有特征都对最终预测结果有用,比如一个预测学生学习成绩的模型, 人的高矮胖瘦显然与最终成绩无关,舍弃掉这些无用特征,保留有用特征的过程就是特征提取。) 然后是特征压缩,并不扔掉特征,利用特征之前的相关性,在尽可能不损失的情况下将高维特征用低维特征表示。典型方法是 PCA。
- 除此之外,非监督方法还可以进行异常检测,检测出训练数据中对于提取一般特征无用的异常点,予以去除,利于训练(但是会有一些由于特殊点存在造成的准确度损失)
-
半监督学习
一部分数据有标记或者答案,另一部分数据没有。这种情况更加常见
- 通常使用无监督学习手段对数据做处理,之后使用监督学习手段做模型的训练和预测。
-
增强学习
根据周围环境的情况,采取行动,根据采取行动的结果,学习行动方式。
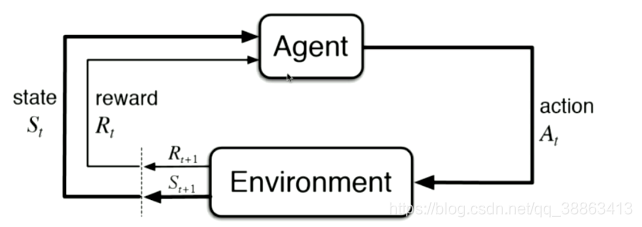
增强学习非常适合于机器人,无人驾驶等领域,是比较前沿的研究方向。
机器学习算法的其它分类
批量学习和在线学习
-
批量学习 Batch Learning
又称为离线学习,事先收集一批训练数据,训练出一个模型,然后应用模型,虽然在应用的过程中又会有新的数据加入,但是模型不使用新数据来优化模型。- 优点: 简单。
- 问题:无法适应环境的变化。 解决方案:如果数据变化不算太快,可以使用定时重新批量学习,过一段时间就使用新增加的数据和原来的数据重新进行批量学习。但是这样运算量巨大,同时,如果环境变化非常快, 这种也变得不可能(例如股市的预测)。
-
在线学习 Online Learning
输入样例得到准确结果之后反馈到模型的训练过程中,从而可以使用输入样例来继续优化模型。- 优点:及时反应新的环境变化
- 缺点:新的数据带来不好的变化,解决方案通常是对数据进行监控(例如使用非监督学习来检测异常点等等)
