今天在看了一下FM算法,就试着用tensorflow实现了一下,数据集用的是sklearn中的iris,我将target=2的删除掉了,保留了target=0 or 1的做一个二分类的测试.
首先来扯一下FM算法的思路,我感觉FM和MF是完全相反的思路,MF矩阵分解的大体思路是直接用两个矩阵相乘去拟合一个用户-商品的矩阵,然后将这两个矩阵作为用户和商品的特征矩阵,想要预测用户是否喜欢某个商品的时候就将这用户和商品的特征矩阵相乘,之后的话就是不断的细化这个模型,例如SVD,SVD++,通过添加时间属性和用户商品偏好去更好的描述出用户和物品的特征.当然MF缺点也很致命,数据稀疏导致的效果不好或者矩阵太大运行起来内存吃不消(实验室的硬件一直都折磨着我~.~)
相比之下,FM走的我更熟悉的机器学习方法,根据特征制作一个模型得到结果,比如给出一个常用的商品购买表,将是否购买这些商品作为用户特征,然后预测用户是否会点击这个商品的广告或者购买商品.好吧,扯得有的远了,先上波公式,普通的线性回归
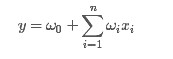
从上面的式子很容易看出,一般的线性模型压根没有考虑特征间的关联(组合)。在生活中,这个可以说影响很大,例如一个男人和女人都是30岁,那么他们喜欢购买的东西可能有很大的区别,然而年龄这个特征都是30,普通的线性回归完全忽视了这种组合
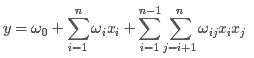
为了求出ωij,我们对每一个特征分量xi引入辅助向量Vi=(vi1,vi2,⋯,vik)。然后,利用vivTj对ωij进行求解。对k值的限定,反映了FM模型的表达能力。
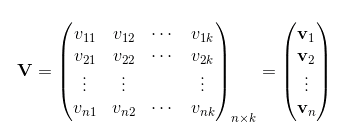
那么ωij组成的矩阵可以表示为:
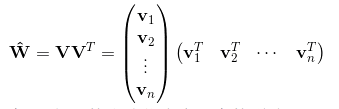
则FM的模型方程为:
FM算法的求解过程
公式部分引用了一下这个博客:http://www.cnblogs.com/ljygoodgoodstudydaydayup/p/6340129.html
多的不说,直接上代码
- # -*- coding: utf-8 -*-
- """
- Created on Sun Apr 16 10:40:12 2017
- @author: hyj
- """
- import tensorflow as tf
- from sklearn.datasets import load_iris
- from sklearn.cross_validation import train_test_split
- #data load
- iris=load_iris()
- x=iris["data"]
- y=iris["target"]
- x,y=x[y!=2],y[y!=2]
- for i in range(len(y)):
- if y[i]==0:
- y[i]=-1
- x_train,x_test,y_train,y_test=train_test_split(x,y,test_size=0.3,random_state=9415)
- n=4
- k=4
- #write fm algorithm
- w0=tf.Variable(0.1)
- w1=tf.Variable(tf.truncated_normal([n]))
- w2=tf.Variable(tf.truncated_normal([n,k]))
- x_=tf.placeholder(tf.float32,[None,n])
- y_=tf.placeholder(tf.float32,[None])
- batch=tf.placeholder(tf.int32)
- w2_new=tf.reshape(tf.tile(w2,[batch,1]),[-1,4,k])
- board_x=tf.reshape(tf.tile(x_,[1,k]),[-1,4,k])
- board_x2=tf.square(board_x)
- q=tf.square(tf.reduce_sum(tf.multiply(w2_new,board_x),axis=1))
- h=tf.reduce_sum(tf.multiply(tf.square(w2_new),board_x),axis=1)
- y_fm=w0+tf.reduce_sum(tf.multiply(x_,w1),axis=1)+\
- 1/2*tf.reduce_sum(q-h,axis=1)
- cost=tf.reduce_sum(0.5*tf.square(y_fm-y_))#+tf.contrib.layers.l2_regularizer(0.1)(w0)\
- #+tf.contrib.layers.l2_regularizer(0.1)(w1)+tf.contrib.layers.l2_regularizer(0.1)(w2)
- batch_fl=tf.cast(batch,tf.float32)
- accury=(batch_fl+tf.reduce_sum(tf.sign(tf.multiply(y_fm,y_))))/(batch_fl*2)
- train_op=tf.train.AdamOptimizer(learning_rate=0.1).minimize(cost)
- with tf.Session() as sess:
- sess.run(tf.global_variables_initializer())
- for i in range(2000):
- sess.run(train_op,feed_dict={x_:x_train,y_:y_train,batch:70})
- print sess.run(cost,feed_dict={x_:x_train,y_:y_train,batch:70})
- print sess.run(accury,feed_dict={x_:x_test,y_:y_test,batch:30})