写在前面
从优达DLND毕业后,一直想自己动手做点什么来着,互助班的导师也鼓励自己动手写点心得体验啥的。之前一直没怎么观看Youtube网红Siraj老师的课程视频,他每个视频最后都会有一个编程挑战。于是,想着先从自己熟悉的内容着手吧,Siraj老师第三周的编程挑战是做一个多类别的文本分类器,链接在此:Github,那就来试试吧。除了想自己练练手外,也顺便把模型都好好梳理一遍。为了给自己增加些难度,是否有可能把过去几年内那些大牛们论文中的模型复现出来呢?阅读这篇文章,需要你对自然语言处理和深度学习的模型有一个基础的了解哦!
另外,需要声明的是,本文在写作过程中或多或少参考了如下大牛们的博客:
- 用深度学习(CNN RNN Attention)解决大规模文本分类问题 - 综述和实践
- 卷积神经网络(CNN)在句子建模上的应用
- 深度学习在文本分类中的应用
- 深度学习与文本分类总结第一篇--常用模型总结
- 优达学城深度学习基石纳米学位课程
文本多分类
首先我们来看下数据集长什么样子吧 :P Let‘s get started!
我们使用pandas来加载数据,数据集来自http://IGN.com,收集了过去20年各大游戏厂商发布的游戏数据,如发布日期,发布平台,游戏评价等变量,这里有一篇关于这个数据集很不错的分析教程 Kaggle 。而我们现在想分析下游戏名与用户评价之间的关系,看上去并不合理,我们姑且按照Siraj老师的任务来试试。于是,游戏名作为文本变量将作为模型的输入X,而用户评价词作为文本类别Y。然后来看看各个类别的数量,为了避免类别样本数的不平衡,我们这里把关于评价为Disaster的游戏去除。
df = pd.read_csv('ign.csv').iloc[:, 1:3]
df.score_phrase.value_counts()
df = df[df.score_phrase != 'Disaster']
首先我们先来试试传统机器学习模型对文本分类任务常见的做法吧
传统文本分类方法
词袋模型
由于计算机只能处理数字型的变量,并不能直接把文本丢给计算机然后让它告诉我们这段文字的类别。于是,我们需要对词进行one-hot编码。假设我们总共有N个词,然后对词进行索引编码并构造一个N维零向量,如果这个文本中的某些词出现,就在该词索引值位置标记为1,表示这个文本包含这个词。于是,我们会得到如下类似的向量
( 0, 0, 1, 0, .... , 1, ... 0, 0, 1, 0)
但是,一般来说词库量至少都是百万级别,因此词袋模型有个两个最大的问题:高维度、高稀疏性。这种表示方法还存在一个重要的问题就是”词汇鸿沟”现象:任意两个词之间都是孤立的。光从这两个向量中看不出两个词是否有关系。
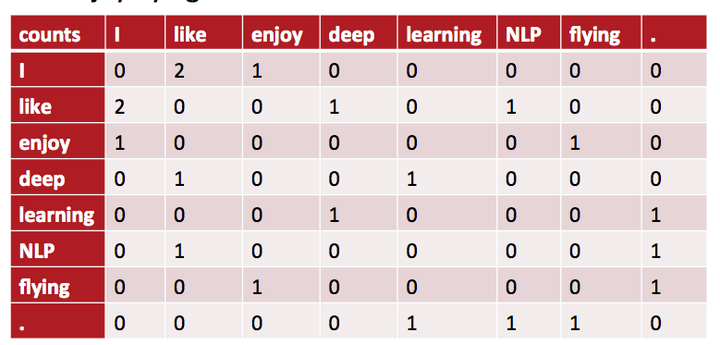
共现矩阵
为了使用上下文来表示单词间的关系,也有人提出使用基于窗口大小的共现矩阵,但仍然存在数据维度大稀疏的问题。
TF-IDF
TF-IDF 用以评估一字词对于一个文档集或一个语料库中的其中一份文档的重要程度,是一种计算特征权重的方法。核心思想即,字词的重要性随着它在文档中出现的次数成正比增加,但同时会随着它在语料库中出现的频率成反比下降。有效地规避了那些高频却包含很少信息量的词。我们这里也是用TF-IDF 对文本变量进行特征提取。
分类器
分类器就是常见的机器学习分类模型了,常用的有以下两种,这里我不再赘述这两个模型的原理了。
- 朴素贝叶斯:从垃圾邮件识别应用开始被广泛使用
- 支持向量机:这篇文章 很通俗地解释了SVM的工作原理
使用Scikit-Learn库能够傻瓜似的来实现你的机器学习模型,我们这里使用TfidfVectorizer函数对文本进行特征处理,并去除停用词,模型有多类别朴素贝叶斯和线性SVM分类器。结果很不令人满意,NB模型结果稍好,准确率为28%,领先SVM 1%。下面我们来看看深度学习模型强大的性能。
vect = TfidfVectorizer(stop_words='english', token_pattern=r'\b\w{2,}\b',
min_df=1, max_df=0.1, ngram_range=(1,2))
mnb = MultinomialNB(alpha=2)
svm = SGDClassifier(loss='hinge', penalty='l2', alpha=1e-3, max_iter=5, random_state=42)
mnb_pipeline = make_pipeline(vect, mnb)
svm_pipeline = make_pipeline(vect, svm)
mnb_cv = cross_val_score(mnb_pipeline, title, label, scoring='accuracy', cv=10, n_jobs=-1)
svm_cv = cross_val_score(svm_pipeline, title, label, scoring='accuracy', cv=10, n_jobs=-1)
print('\nMultinomialNB Classifier\'s Accuracy: %0.5f\n' % mnb_cv.mean())
print('\nSVM Classifier\'s Accuracy: %0.5f\n' % svm_cv.mean())
走进NLP和DL
传统方法对于文本的特征表达能力很弱,神经网络同样不擅长处理这样高维度高稀疏性的数据,因此我们需要对文本做进一步的特征处理,这里就要讲到词嵌入的概念了。深度学习模型中,一个单词常常用一个低维且稠密的向量来表示,如下所示:
( 0.286, 0.792, -0.177, -0.107, .... , 0.109, ... 0.349, 0.271, -0.642)
词向量
主流的词嵌入实现方法有Mikolov的Word2Vec和斯坦福大学的Glove,也有人做过实验来比较这两种方法的优劣,并没有多大的差异。Word2Vec是基于预测的词向量模型,简单来说,就是给定一个词,去预测这个词周围可能出现的词,或者给定一些词来确定位于中心位置的词。而Glove是基于统计方法的,通过对词-词共现矩阵里的非零元素进行训练。总体来说,Word2Vec使用的是局部信息,而Glove使用的是全局信息,因此前者训练起来更慢但不占用内存,而Glove通过更多的计算资源换取训练速度上的提升。具体的实现细节可以参考这两篇论文。本文中将使用预训练的Glove300维词向量和由自己文本生成的词向量。
为了快速实现模型,这篇文章中将使用Keras(TensorFlow的高级API)来完成。要使用Keras前,你必须安装TensorFlow作为其后端,Keras目前支持Tensorflow、Theano和CNTK作为后端,不过我还是推荐大家使用TensorFlow。Keras的中文文档能够帮助大家无坑完成安装过程。
我们先来了解一些基础的深度学习模型吧!
CNN
深度学习入门必学的两大模型之一卷积神经网络。首先我们来理解下什么是卷积操作?卷积,你可以把它想象成一个应用在矩阵上的滑动窗口函数。下图中左边的矩阵表示的是一张黑白图像。每个方格代表了一个像素,0表示黑色,1表示白色。这个滑动窗口称作kernel或者filter。这里我们使用的是一个3*3的filter,将它的值和与其对应的原图像矩阵进行相乘,然后再将它们相加。这样我们在整个原图矩阵上滑动filter来遍历所有像素后得到一个完整的卷积特征。
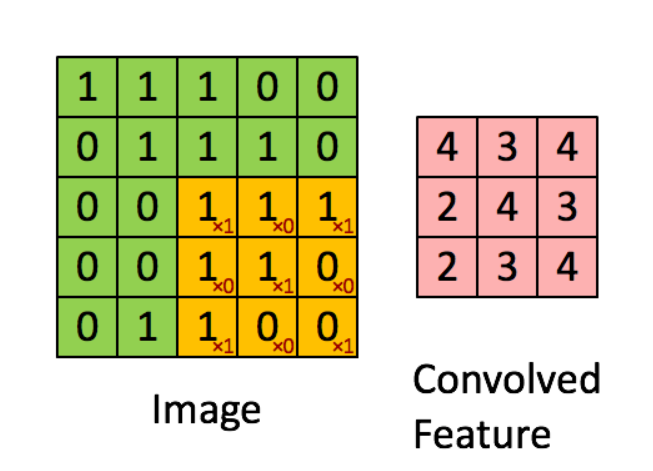
卷积网络也就是对输入样本进行多次卷积操作,提取数据中的局部位置的特征,然后再拼接池化层(图中的Pooling层)做进一步的降维操作,最后与全连接层拼接完成对输入样本的全新的特征构造,将新的特征向量输送给分类器(以图片分类为例)进行预测分类。我们可以把CNN类比N-gram模型,N-gram也是基于词窗范围这种局部的方式对文本进行特征提取,与CNN的做法很类似,在下文中,我们再来看看如何运用CNN对文本数据进行建模。
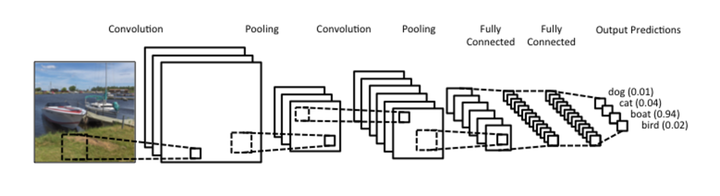
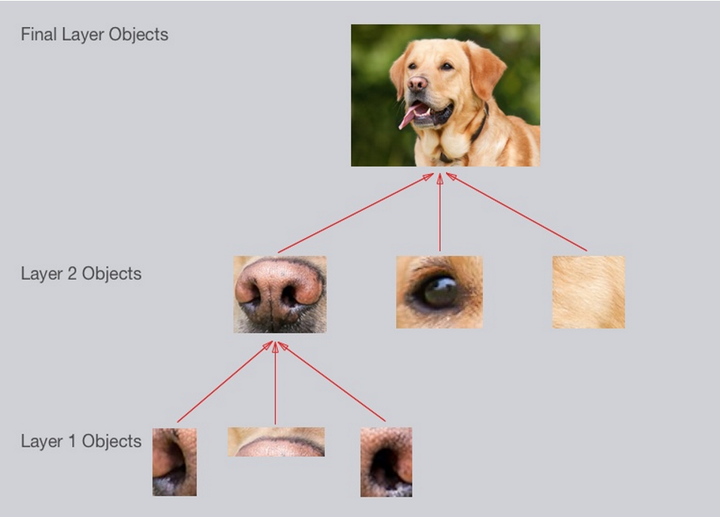
卷积网络开始崭露头角是在CV领域,2012年的ImageNet竞赛中,大大降低了图片分类的错误率。为什么CNN在计算机视觉领域这么厉害呢?直观的感受就是:
- 它能够学习识别基本的直线,曲线,然后是形状,点块,然后是图片中更复杂的物体。最终CNN分类器把这些大的,复杂的物体综合起来识别图片
- 在下图中的例子中,可以看作这样的层级关系:
- 简单的形状,如椭圆,暗色圆圈
- 复杂的物体(简单形状的组合),例如眼睛,鼻子,毛发
- 狗的整体(复杂物体的组合)
RNN
而循环网络与CNN不同的是,CNN学习空间位置上局部位置的特征表示,而RNN学习的是时间顺序上的特征,用来处理序列数据,如股价,文本等。RNN之所以称为循环神经网路,即一个序列当前的输出与前面的输出也有关。具体的表现形式为网络会对前面的信息进行记忆并应用于当前输出的计算中,即隐藏层之间的节点是相互连接的,并且隐藏层的输入不仅包括输入层的输出还包括上一时刻隐藏层的输出。
就像我们说话一样,我们不能把说的话倒过来表示,这样会变得毫无意义,并不会明白你在说什么,也就是说文本中的每个词是包含顺序信息的,由此可以使用RNN对文本数据进行建模。
但是,随着时间的不断增加,你的隐藏层一次又一次地乘以权重W。假如某个权重w是一个接近于0或者大于1的数,随着乘法次数的增加,这个权重值会变得很小或者很大,造成反向传播时梯度计算变得很困难,造成梯度爆炸或者梯度消失的情况,模型难以训练。也就是说一般的RNN模型对于长时间距离的信息记忆很差,比如人老了会忘记某件很久发生的事情一样,于是,LSTM和GRU 应运而生。LSTM与GRU很相似,以LSTM为例。
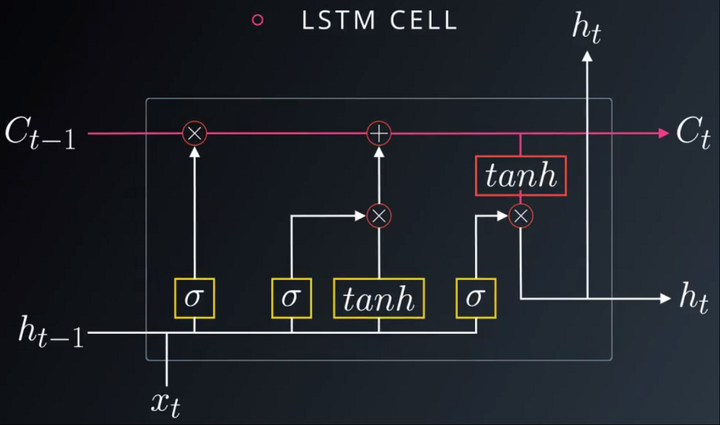
LSTM又称为长短期记忆网络,LSTM 单元乍看起来很复杂。关键的新增部分就在于标记为 C 的单元状态。在这个单元中,有四个显示为黄色框的网络层,每个层都有自己的权重,如以 σ 标记的层是 sigmoid 层。这些红圈表示逐点或逐元素操作。单元状态在通过 LSTM 单元时几乎没有交互,使得大部分信息得以保留,单元状态仅通过这些控制门(gate)进行修改。第一个控制门是遗忘门,用来决定我们会从单元状态中丢弃什么信息。第二个门是更新们,用以确定什么样的新信息被存放到单元状态中。最后一个门是输出门,我们需要确定输出什么样的值。总结来说 LSTM 单元由单元状态和一堆用于更新信息的控制门组成,让信息部分传递到隐藏层状态。更直观的来讲,把LSTM看作是一部电影,可以把单元状态看作是剧情主线,而随着剧情的发展,有些不必要的事件会被遗忘,而一些更加影响主线的剧情会被加入到单元状态中来,不断更新剧情然后输出新的剧情发展。
Attention机制
基于Attention的模型在NLP领域首先被应用于自然语言生成问题中,用于改进机器翻译任务的性能。我们这里也以机器翻译为例来解释下注意力机制的原理。我们可以把翻译任务是一个序列向另一个序列转换的过程。
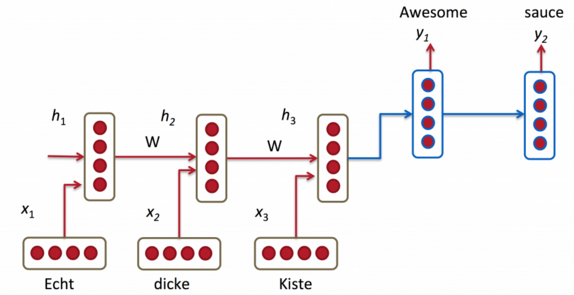
上图就是Seq2Seq模型的基本结构,由编码器(Encoder)和解码器(Decoder)组成。编码器负责将输入的单词按顺序进行信息提取,在最后一步生成的隐藏状态即固定长度的句子的特征向量。然后解码器从这个句子向量中获取信息对文本进行翻译。由于解码器的主要信息来源就是最后一步的隐藏状态,这个h3向量必须尽可能地包含句子的所有必要的信息。这个向量说白了就是句子嵌入(类比词嵌入)。假如我们需要翻译的文本不是很长,这个模型已经能达到很不错的性能。假如我们现在要翻译一句超过50个单词的句子,似乎这个模型很难再hold住,即使你在训练的时候使用了LSTM去提取句子特征,去尽可能保留过去的记忆,但还是达不到想要的结果。
而注意力机制恰恰是为了解决长距离依赖的问题,我们不再需要固定长度的句子向量,而是让解码器自己去输入文本中寻找想要关注的被翻译文本。比如把”I am learning deep learning model“成中文时,我们让解码器去与输入文本中的词对齐,翻译deep的时候去关注deep这个词,而不是平等对待每个有可能的词,找到与输入文本相对应的相同语义的词,而不再是对句子进行特征提取。
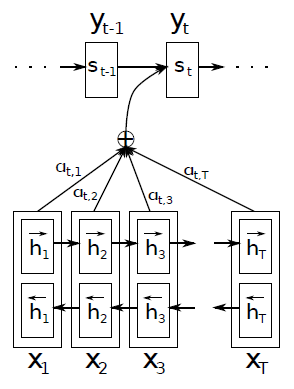
上图我们可以看到,解码器在翻译下一个词时,需要依赖之前已经翻译好的文本和与输入文本相对齐的那个词。简单描述的话,用解码器t时刻的隐藏状态去和输入文本中的每个单词对应的隐藏状态去比对,通过某个函数f去计算带翻译的单词yi与每个输入单词对齐的可能性。而编码器由Bi-LSTM模型组成。不同的语言的f函数可能会有差别,就像中文和英文,语法结构差异很大,很难按顺序单词一一对齐。由此可以得出结论,注意力机制的核心思想是在翻译每个目标词(或对文本进行分类时)所用的上下文是不同的,这样的考虑显然是更合理的。具体实现请见这篇论文。而如何将注意力机制运用到文本分类中来,下文会介绍。
深度学习文本分类模型
TextCNN
这是CNN首次被应用于文本分类任务的开山之作,可以说,之后很多论文都是基于此进行拓展的。它是由Yoon Kim于2014年发表的,你可以在github上找到各种不同深度学习框架对于这个模型的实现。下面我们来细细品读这篇论文吧。
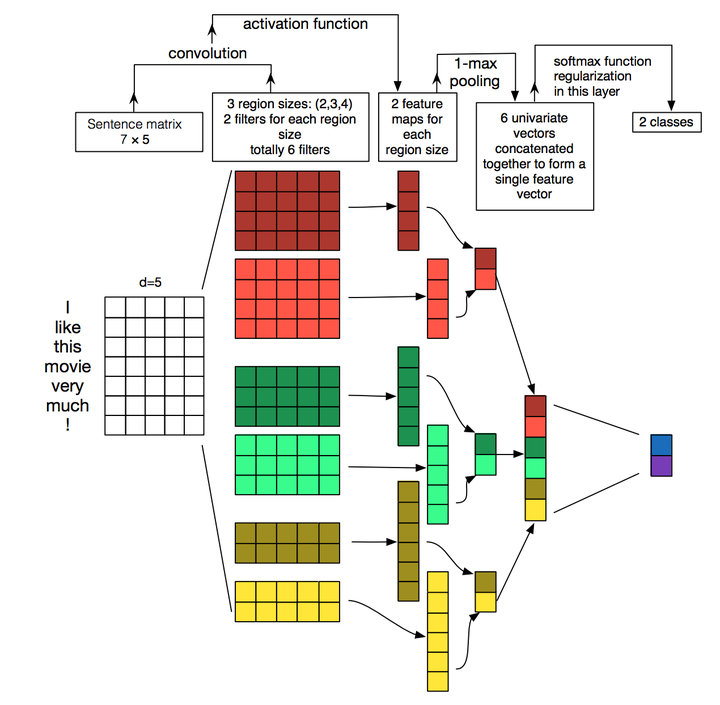
上图很好地诠释了模型的框架。假设我们有一句句子需要对其进行分类。句子中每个词是由n维词向量组成的,也就是说输入矩阵大小为m*n,其中m为句子长度。CNN需要对输入样本进行卷积操作,对于文本数据,filter不再横向滑动,仅仅是向下移动,有点类似于N-gram在提取词与词间的局部相关性。图中共有三种步长策略,分别是2,3,4,每个步长都有两个filter(实际训练时filter数量会很多)。在不同词窗上应用不同filter,最终得到6个卷积后的向量。然后对每一个向量进行最大化池化操作并拼接各个池化值,最终得到这个句子的特征表示,将这个句子向量丢给分类器进行分类,至此完成整个流程。
文中作者还提出了动态的词向量,即将词向量也作为权重变量进行训练,而我们平时常用的产生词向量的方法有从当前数据集中自己产生的词向量和使用预训练好的word2vec或glove词向量,都属于静态词向量范畴,即它们不再网络训练时发生变化。文中实验表明,动态的词向量表现更好。有时间的话之后来尝使用Tensorflow来实现这种动态词向量。另外,这篇论文 A Sensitivity Analysis of (and Practitioners' Guide to) Convolutional Neural Networks for Sentence Classification详细地阐述了关于TextCNN模型的调参心得。
DCNN
这篇论文的亮点在于采用的动态的K-max Pooling,而不是我们常见的Max Pooling层。模型细节主要分为以下几个部分:
- 宽卷积:卷积分为两种,窄卷积和宽卷积。窄卷积即从第一个元素开始卷积操作,这样第一个元素和最后一个元素只能被filter扫过一次。而宽卷积为了弥补这一点,就在第一个元素前和最后一个元素后增加0作为补充,因此宽卷积又叫做补零法。当filter长度相对输入向量的长度较大时,你会发现宽卷积很有用,或者说很有必要。
- 动态的K-Max Pooling:下图中可以看到两个个池化层的K是不确定的,即动态的,具体的取值依赖于输入和网络的其他参数。文中提到,K的取值与输入文本的长度,网络中总共的卷积数,上一层卷积的个数有关,具体可以查看论文(始终没有解决数学公式的显示问题,所以不展开了)。因此文中的pooling的结果不是返回一个最大值,而是返回k组最大值,这些最大值是原输入的一个子序列
- Folding层:图中很清楚地看到,Folding层将词向量的维度缩减一半,即将两行的向量相加,可能考虑相邻两行之前某种未知的联系吧。不确定是否真的有效,第一次看到卷积网络中出现这样缩减维度的层。

Bi-LSTM
本篇论文由复旦大学的邱锡鹏教授的团队于2015年发表,文中详细地阐述了RNN模型用于文本分类任务的各种变体模型。最简单的RNN用于文本分类如下图所示,这是LSTM用于网络结构原理示意图,示例中的是利用最后一个词的结果直接接全连接层softmax输出就完成了。详情可见这里的阅读笔记链接

CLSTM
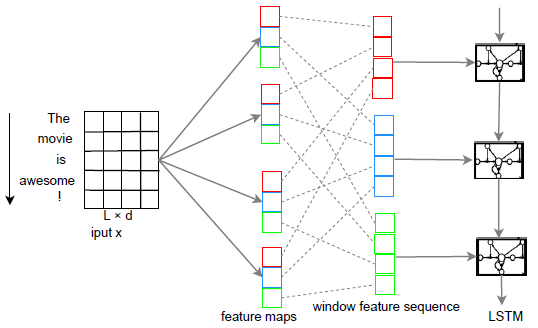
论文A C-LSTM Neural Network for Text Classification中将CNN和RNN混合使用作为文本的分类器。其实就是将CNN训练得到的新的特征作为LSTM的输入,模型的简单描述如下:
- Feature maps指不同词窗经过不同过滤层即卷积操作后得到的特征集合
- Window feature sequence是指CNN不再经过Max-pooling操作,而是将特征集合重新排列,得到同一词窗在经过不同卷积操作后的综合特征向量,即把相同颜色的放在一个序列里面,然后依次排列下来
- 在window feature sequence层的每个序列,其实和原始句子中的序列是对应的,保持了原有的相对顺序,只不过是中间进行了卷积的操作,将这些新的向量作为LSTM的输入变量。
RCNN
这篇Recurrent Convolutional Neural Networks for Text Classification是由中科院与2015年发表在AAAI上的一篇文章。文中将RNN和CNN以另外一种方式呈现。

我们可以发现,这个模型是把CNN模型中的卷积的部分使用RNN代替了,最后加上池化层。而这个RNN层做的事情是,将每一个词分别和左边的词以及右边的词进行融合。每以文本先经过1层双向LSTM,该词的左侧的词正向输入进去得到一个词向量,该词的右侧反向输入进去得到一个词向量。再结合该词的词向量,生成一个 3k维的组合词向量。然后再将这些新的词向量传入全连接层,紧接着是最大化池化层进行特征降维。最后接上全连接层,便完成多分类任务。
FastText
FastText是Facebook于2016年发表的论文中提出的一种简单快速实现的 文本分类模型。可能你已经被前面那些复杂的模型搞得七荤八素了,那么这个模型你很快地理解,令人意外的是,它的性能并不差。输入变量是经过embedding的词向量,这里的隐藏层只是一个简单的平均池化层,然后把这个池化过的向量丢给softmax分类器就完成了。另外,这里的X并不仅仅是单个单词,也可以加入N-gram组合的词作为输入的一部分,文中将2-元和3-元的特征也加入到了模型中。本文的思想在于通过简单的特征线性组合就可以达到不错的分类性能,我们可以把fasttext当作是工业界一种快速实现模型的产物。

Hierarchical Attention Networks(HAN)
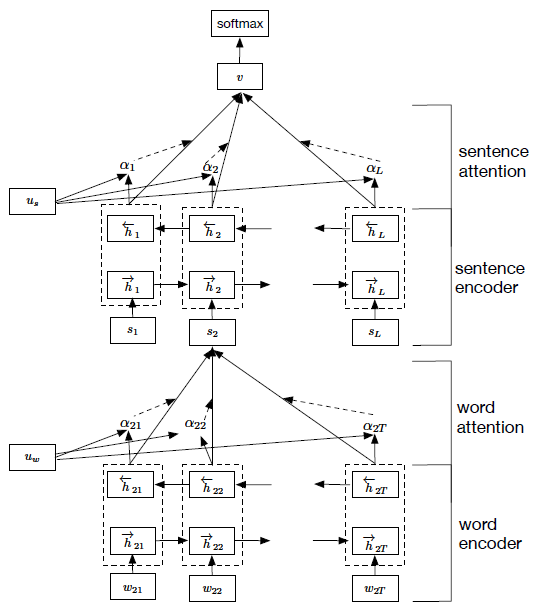
本文最大的特点是结合了注意力机制,并成功运用到文本分类任务中。模型如下图所示,分为两大部分,分别是对句子建模和对文档建模。之前提到的模型基本上都是在对句子进行建模,通过对句子中的词进行特征组合,形成句子向量。本文更进一步的是,对句子的上一级篇章进行建模。我们假设评论中有好几句话,那么我们首先要切分句子然后再切分词,对于长评论的分类是一个不错的选择。
首先,词向量会经过双向LSTM网络完成编码,将隐藏层的输出和注意力机制相结合,形成对句子的特征表示。然后每一个句子相当于一个词,再重复一次前一步词到句子的建模过程,完成句子到文档的建模过程。而注意力机制在这里发挥的作用相当于去寻找这句句子中的核心词或者这篇文档中的核心句子。具体实现的过程可参照我接下来的代码。这里有关于在Keras中完成Attention层的构建的详细讨论。游戏标题只涉及单句,因此构不成文档,只需要 word-level 这一层的注意力即可。加入Attention之后最大的好处自然是能够直观的解释各个句子和词对分类类别的重要性。
Aspect Level Sentiment
首先来介绍先aspect的概念,给定一个句子和句子中出现的某个aspect,aspect-level 情感分析的目标是分析出这个句子在给定aspect上的情感倾向。例如:"Great food but the service was dreadful!" 在“food”这个aspect上,情感倾向为正,而在 “service”这个aspect上情感倾向为负。Aspect level的情感分析相对于文档级别来说粒度更细。
这里有两篇阅读笔记比较详细地描述了两篇相关论文:
实战!
首先我们先要对文本数据进行编码,因为模型只能接受数值型的数据。常见的编码之前有提到过有One-Hot和词嵌入。第一步,来划分训练样本和测试样本。如果需要将你的模型部署到产品中去,则需要更加复杂的划分,详情请见吴恩达最新的AI课程中提及的机器学习项目中必须注意的一些问题。这里,我们不需要考虑太多的细节,就简单划分训练集和测试集即可。
# 导入使用到的库
from keras.preprocessing.sequence import pad_sequences
from keras.preprocessing.text import Tokenizer
from keras.layers.merge import concatenate
from keras.models import Sequential, Model
from keras.layers import Dense, Embedding, Activation, merge, Input, Lambda, Reshape
from keras.layers import Convolution1D, Flatten, Dropout, MaxPool1D, GlobalAveragePooling1D
from keras.layers import LSTM, GRU, TimeDistributed, Bidirectional
from keras.utils.np_utils import to_categorical
from keras import initializers
from keras import backend as K
from keras.engine.topology import Layer
from sklearn.naive_bayes import MultinomialNB
from sklearn.linear_model import SGDClassifier
from sklearn.feature_extraction.text import TfidfVectorizer
import pandas as pd
import numpy as np
# 划分训练/测试集
X_train, X_test, y_train, y_test = train_test_split(title, label, test_size=0.1, random_state=42)
# 对类别变量进行编码,共10类
y_labels = list(y_train.value_counts().index)
le = preprocessing.LabelEncoder()
le.fit(y_labels)
num_labels = len(y_labels)
y_train = to_categorical(y_train.map(lambda x: le.transform([x])[0]), num_labels)
y_test = to_categorical(y_test.map(lambda x: le.transform([x])[0]), num_labels)
# 分词,构建单词-id词典
tokenizer = Tokenizer(filters='!"#$%&()*+,-./:;<=>?@[\\]^_`{|}~\t\n',lower=True,split=" ")
tokenizer.fit_on_texts(title)
vocab = tokenizer.word_index
# 将每个词用词典中的数值代替
X_train_word_ids = tokenizer.texts_to_sequences(X_train)
X_test_word_ids = tokenizer.texts_to_sequences(X_test)
# One-hot
x_train = tokenizer.sequences_to_matrix(X_train_word_ids, mode='binary')
x_test = tokenizer.sequences_to_matrix(X_test_word_ids, mode='binary')
# 序列模式
x_train = pad_sequences(X_train_word_ids, maxlen=20)
x_test = pad_sequences(X_test_word_ids, maxlen=20)
Keras提供两大类模型框架。第一种是Sequential模式,就像搭积木一样,将你想要的网络层拼接起来,可以理解为串联。而另外一种是Model模式,需要你指定模型的输入和输出格式,更加灵活地组合你的网络层,可以理解为串联加并联。搭建完模型结构后,你需要对模型进行编译,这一步你需要指定模型的损失函数,本文是文本多分类任务,所以损失函数是多类别的交叉熵函数。另外, 需要确定损失函数的优化算法和模型评估指标。Adam优化器是目前公认的各项任务中性能最优的,所以本文将全部使用Adam作为优化器。这里有一篇实战教程对不同优化器做了性能评估。接着就是模型的训练,使用fit函数,这里需要指定的参数有输入数据,批量大小,迭代轮数,验证数据集等。然后,你就能看到你的模型开始愉快地运行起来了。Keras作为Tensforflow的高级API,对很多细节进行了封装,可以让深度学习小白快速上手,如果你需要实现更加复杂的模型的话,就需要去好好研究下Tensorflow了。下一篇博文目标是用Tensorflow来实现简单的机器翻译任务,也为接下来准备参加的AI Challenger比赛做准备!
One-Hot + MLP
MLP翻译过来叫多层感知机,其实就是多隐藏层的网络。如此简单的模型,结果居然出奇的好!卖个关子,最后看看各个模型的最终准确率排名 = =
model = Sequential()
# 全连接层
model.add(Dense(512, input_shape=(len(vocab)+1,), activation='relu'))
# DropOut层
model.add(Dropout(0.5))
# 全连接层+分类器
model.add(Dense(num_labels,activation='softmax'))
model.compile(loss='categorical_crossentropy',
optimizer='adam',
metrics=['accuracy'])
model.fit(x_train, y_train,
batch_size=32,
epochs=15,
validation_data=(x_test, y_test))
CNN
模仿LeNet-5
LeNet-5是卷积神经网络的作者Yann LeCun用于MNIST识别任务提出的模型。模型很简单,就是卷积池化层的堆叠,最后加上几层全连接层。我们依样画葫芦,将它运用在文本分类任务中,只是模型的输入不同。
# 模型结构:嵌入-卷积池化*2-dropout-BN-全连接-dropout-全连接
model.add(Embedding(len(vocab)+1, 300, input_length=20))
model.add(Convolution1D(256, 3, padding='same'))
model.add(MaxPool1D(3,3,padding='same'))
model.add(Convolution1D(128, 3, padding='same'))
model.add(MaxPool1D(3,3,padding='same'))
model.add(Convolution1D(64, 3, padding='same'))
model.add(Flatten())
model.add(Dropout(0.1))
model.add(BatchNormalization()) # (批)规范化层
model.add(Dense(256,activation='relu'))
model.add(Dropout(0.1))
model.add(Dense(num_labels,activation='softmax'))
model.compile(loss='categorical_crossentropy',
optimizer='adam',
metrics=['accuracy'])
model.fit(X_train_padded_seqs, y_train,
batch_size=32,
epochs=15,
validation_data=(X_test_padded_seqs, y_test))
TextCNN(这里需要使用Model模式)
# 模型结构:词嵌入-卷积池化*3-拼接-全连接-dropout-全连接
main_input = Input(shape=(20,), dtype='float64')
# 词嵌入(使用预训练的词向量)
embedder = Embedding(len(vocab) + 1, 300, input_length = 20, weights = [embedding_matrix], trainable = False)
embed = embedder(main_input)
# 词窗大小分别为3,4,5
cnn1 = Convolution1D(256, 3, padding='same', strides = 1, activation='relu')(embed)
cnn1 = MaxPool1D(pool_size=4)(cnn1)
cnn2 = Convolution1D(256, 4, padding='same', strides = 1, activation='relu')(embed)
cnn2 = MaxPool1D(pool_size=4)(cnn2)
cnn3 = Convolution1D(256, 5, padding='same', strides = 1, activation='relu')(embed)
cnn3 = MaxPool1D(pool_size=4)(cnn3)
# 合并三个模型的输出向量
cnn = concatenate([cnn1,cnn2,cnn3], axis=-1)
flat = Flatten()(cnn)
drop = Dropout(0.2)(flat)
main_output = Dense(num_labels, activation='softmax')(drop)
model = Model(inputs = main_input, outputs = main_output)
DCNN(占坑)
RNN
LSTM(你也可以换成GRU,经过多次试验GRU的性能较LSTM稍好)
GRU采用与LSTM相似的单元结构用于控制信息的更新与保存,它将遗忘门和输入门合成了一个单一的更新门,最终的模型比标准的 LSTM 模型要简单,也是非常流行的变体。
# 模型结构:词嵌入-LSTM-全连接
model = Sequential()
model.add(Embedding(len(vocab)+1, 300, input_length=20))
model.add(LSTM(256, dropout=0.2, recurrent_dropout=0.1))
model.add(Dense(num_labels, activation='softmax'))
Bi-GRU
需要注意的是,你如果需要堆叠多层RNN,需要在前一层返回序列,设置return_sequences参数为True即可。Bi即双向RNN结构,模型会从正向读取文本,也会逆向读取文本,从两个角度去获取文本的顺序信息。
# 模型结构:词嵌入-双向GRU*2-全连接
model = Sequential()
model.add(Embedding(len(vocab)+1, 300, input_length=20))
model.add(Bidirectional(GRU(256, dropout=0.2, recurrent_dropout=0.1, return_sequences=True)))
model.add(Bidirectional(GRU(256, dropout=0.2, recurrent_dropout=0.1)))
model.add(Dense(num_labels, activation='softmax'))
CNN+RNN
C-LSTM串联(将CNN的输出直接拼接上RNN)
# 模型结构:词嵌入-卷积池化-GRU*2-全连接
model = Sequential()
model.add(Embedding(len(vocab)+1, 300, input_length=20))
model.add(Convolution1D(256, 3, padding='same', strides = 1))
model.add(Activation('relu'))
model.add(MaxPool1D(pool_size=2))
model.add(GRU(256, dropout=0.2, recurrent_dropout=0.1, return_sequences = True))
model.add(GRU(256, dropout=0.2, recurrent_dropout=0.1))
model.add(Dense(num_labels, activation='softmax'))
并联(将CNN的输出和RNN的输出合并成一个输出)(论文)
# 模型结构:词嵌入-卷积池化-全连接 ---拼接-全连接
# -双向GRU-全连接
main_input = Input(shape=(20,), dtype='float64')
embed = Embedding(len(vocab)+1, 300, input_length=20)(main_input)
cnn = Convolution1D(256, 3, padding='same', strides = 1, activation='relu')(embed)
cnn = MaxPool1D(pool_size=4)(cnn)
cnn = Flatten()(cnn)
cnn = Dense(256)(cnn)
rnn = Bidirectional(GRU(256, dropout=0.2, recurrent_dropout=0.1))(embed)
rnn = Dense(256)(rnn)
con = concatenate([cnn,rnn], axis=-1)
main_output = Dense(num_labels, activation='softmax')(con)
model = Model(inputs = main_input, outputs = main_output)
RCNN
# 模型结构:词嵌入*3-LSTM*2-拼接-全连接-最大化池化-全连接
# 我们需要重新整理数据集
left_train_word_ids = [[len(vocab)] + x[:-1] for x in X_train_word_ids]
left_test_word_ids = [[len(vocab)] + x[:-1] for x in X_test_word_ids]
right_train_word_ids = [x[1:] + [len(vocab)] for x in X_train_word_ids]
right_test_word_ids = [x[1:] + [len(vocab)] for x in X_test_word_ids]
# 分别对左边和右边的词进行编码
left_train_padded_seqs = pad_sequences(left_train_word_ids, maxlen=20)
left_test_padded_seqs = pad_sequences(left_test_word_ids, maxlen=20)
right_train_padded_seqs = pad_sequences(right_train_word_ids, maxlen=20)
right_test_padded_seqs = pad_sequences(right_test_word_ids, maxlen=20)
# 模型共有三个输入,分别是左词,右词和中心词
document = Input(shape = (None, ), dtype = "int32")
left_context = Input(shape = (None, ), dtype = "int32")
right_context = Input(shape = (None, ), dtype = "int32")
# 构建词向量
embedder = Embedding(len(vocab) + 1, 300, input_length = 20)
doc_embedding = embedder(document)
l_embedding = embedder(left_context)
r_embedding = embedder(right_context)
# 分别对应文中的公式(1)-(7)
forward = LSTM(256, return_sequences = True)(l_embedding) # 等式(1)
# 等式(2)
backward = LSTM(256, return_sequences = True, go_backwards = True)(r_embedding)
together = concatenate([forward, doc_embedding, backward], axis = 2) # 等式(3)
semantic = TimeDistributed(Dense(128, activation = "tanh"))(together) # 等式(4)
# 等式(5)
pool_rnn = Lambda(lambda x: backend.max(x, axis = 1), output_shape = (128, ))(semantic)
output = Dense(10, activation = "softmax")(pool_rnn) # 等式(6)和(7)
model = Model(inputs = [document, left_context, right_context], outputs = output)
model.compile(loss='categorical_crossentropy',
optimizer='adam',
metrics=['accuracy'])
model.fit([X_train_padded_seqs, left_train_padded_seqs, right_train_padded_seqs], y_train,
batch_size=32,
epochs=12,
validation_data=([X_test_padded_seqs, left_test_padded_seqs, right_test_padded_seqs], y_test))
Attention
HAN
由于Keras目前还没有现成的Attention层可以直接使用,我们需要自己来构建一个新的层函数。Keras自定义的函数主要分为四个部分,分别是:
- init:初始化一些需要的参数
- bulid:具体来定义权重是怎么样的
- call:核心部分,定义向量是如何进行运算的
- compute_output_shape:定义该层输出的大小
class Attention(Layer):
def __init__(self, attention_size, **kwargs):
self.attention_size = attention_size
super(Attention, self).__init__(**kwargs)
def build(self, input_shape):
# W: (EMBED_SIZE, ATTENTION_SIZE)
# b: (ATTENTION_SIZE, 1)
# u: (ATTENTION_SIZE, 1)
self.W = self.add_weight(name="W_{:s}".format(self.name),
shape=(input_shape[-1], self.attention_size),
initializer="glorot_normal",
trainable=True)
self.b = self.add_weight(name="b_{:s}".format(self.name),
shape=(input_shape[1], 1),
initializer="zeros",
trainable=True)
self.u = self.add_weight(name="u_{:s}".format(self.name),
shape=(self.attention_size, 1),
initializer="glorot_normal",
trainable=True)
super(Attention, self).build(input_shape)
def call(self, x, mask=None):
# input: (BATCH_SIZE, MAX_TIMESTEPS, EMBED_SIZE)
# et: (BATCH_SIZE, MAX_TIMESTEPS, ATTENTION_SIZE)
et = K.tanh(K.dot(x, self.W) + self.b)
# at: (BATCH_SIZE, MAX_TIMESTEPS)
at = K.softmax(K.squeeze(K.dot(et, self.u), axis=-1))
if mask is not None:
at *= K.cast(mask, K.floatx())
# ot: (BATCH_SIZE, MAX_TIMESTEPS, EMBED_SIZE)
atx = K.expand_dims(at, axis=-1)
ot = atx * x
# output: (BATCH_SIZE, EMBED_SIZE)
output = K.sum(ot, axis=1)
return output
def compute_mask(self, input, input_mask=None):
return None
def compute_output_shape(self, input_shape):
return (input_shape[0], input_shape[-1])
定义好Attention层,直接调用即可,我们来看下:
# 模型结构:词嵌入-双向GRU-Attention-全连接
inputs = Input(shape=(20,), dtype='float64')
embed = Embedding(len(vocab) + 1,300, input_length = 20)(inputs)
gru = Bidirectional(GRU(100, dropout=0.2, return_sequences=True))(embed)
attention = AttLayer()(gru)
output = Dense(num_labels, activation='softmax')(attention)
model = Model(inputs, output)
有知友私信我,如何可视化attention权重,这里给出示例:
# 需要导入两个模型,分别是句子级别的和篇章级别的,以及预处理后的文本序列
def get_attention(sent_model, doc_model, sequences, topN=5):
sent_before_att = K.function([sent_model.layers[0].input, K.learning_phase()],
[sent_model.layers[2].output])
cnt_reviews = sequences.shape[0]
# 导出这个句子每个词的权重
sent_att_w = sent_model.layers[3].get_weights()
sent_all_att = []
for i in range(cnt_reviews):
sent_each_att = sent_before_att([sequences[i], 0])
sent_each_att = cal_att_weights(sent_each_att, sent_att_w, model_name)
sent_each_att = sent_each_att.ravel()
sent_all_att.append(sent_each_att)
sent_all_att = np.array(sent_all_att)
doc_before_att = K.function([doc_model.layers[0].input, K.learning_phase()],
[doc_model.layers[2].output])
# 找到重要的分句
doc_att_w = doc_model.layers[3].get_weights()
doc_sub_att = doc_before_att([sequences, 0])
doc_att = cal_att_weights(doc_sub_att, doc_att_w, model_name)
return sent_all_att, doc_att
# 使用numpy重新计算attention层的结果
def cal_att_weights(output, att_w, model_name):
if model_name == 'HAN':
eij = np.tanh(np.dot(output[0], att_w[0]) + att_w[1])
eij = np.dot(eij, att_w[2])
eij = eij.reshape((eij.shape[0], eij.shape[1]))
ai = np.exp(eij)
weights = ai / np.sum(ai)
return weights
这样我们就得到经过attention层后的权重了, 具体如何可视化可参考plotly包中的热力图,需要自定义热力图的展示方式,这里贴下我导出的热力图。

FastText(模型很简单,比较复杂的是构造输入数据)
# 模型结构:词嵌入(n-gram)-最大化池化-全连接
# 生成n-gram组合的词(以3为例)
ngram = 3
# 将n-gram词加入到词表
def create_ngram(sent, ngram_value):
return set(zip(*[sent[i:] for i in range(ngram_value)]))
ngram_set = set()
for sentence in X_train_padded_seqs:
for i in range(2, ngram+1):
set_of_ngram = create_ngram(sentence, i)
ngram_set.update(set_of_ngram)
# 给n-gram词汇编码
start_index = len(vocab) + 2
token_indice = {v: k + start_index for k, v in enumerate(ngram_set)} # 给n-gram词汇编码
indice_token = {token_indice[k]: k for k in token_indice}
max_features = np.max(list(indice_token.keys())) + 1
# 将n-gram词加入到输入文本的末端
def add_ngram(sequences, token_indice, ngram_range):
new_sequences = []
for sent in sequences:
new_list = sent[:]
for i in range(len(new_list) - ngram_range + 1):
for ngram_value in range(2, ngram_range + 1):
ngram = tuple(new_list[i:i + ngram_value])
if ngram in token_indice:
new_list.append(token_indice[ngram])
new_sequences.append(new_list)
return new_sequences
x_train = add_ngram(X_train_word_ids, token_indice, ngram)
x_test = add_ngram(X_test_word_ids, token_indice, ngram)
x_train = pad_sequences(x_train, maxlen=25)
x_test = pad_sequences(x_test, maxlen=25)
model = Sequential()
model.add(Embedding(max_features, 300, input_length=25))
model.add(GlobalAveragePooling1D())
model.add(Dense(num_labels, activation='softmax'))
Char-Level
我分别测试了TextCNN和RNN模型采用字符作为输入时的模型性能,发现不尽如人意,究其原因,可能是字级别粒度太细,而且文本是短文本,并不能反映出什么有效的信息。前者能达到0.4勉强及格的准确率,而后者只能达到0.28的准确率。因此,不再尝试对短文本进行字粒度的考证。这里想简单应用字符级别的输入,只需对原始文本稍作改变即可。
all_sent = [] # 用于存放新的文本 如 A m y ' s J i g s a w S c r a p b o o k
for sent in title.tolist():
new = []
for word in sent:
for char in word:
new.append(word)
new_sent = " ".join(new)
all_sent.append(new_sent)
To-do list
还有一些论文还没有实现,接下来我会继续更新,敬请期待。。。
- Aspect Level Sentiment
- Dynamic K-max Pooling
模型结果比较
每个模型我都尝试了使用预训练的Glove词向量,效果都不如直接从原文本训练来的好,可能的原因是,文本内容比较简单,而300维的Glove词向量是根据海量语料训练的,看来并不能简单使用Word2Vec和Glove的训练好的向量。需要注意的是,我将最后一个epoch(总共12个epoch)的结果最为模型最终的准确率而且并没有做交叉验证,这样的做法不太合理,可能存在有的模型过拟合了,有的还是欠拟合状态的,简单粗暴吧。每个模型的训练时间和准确率如下图:
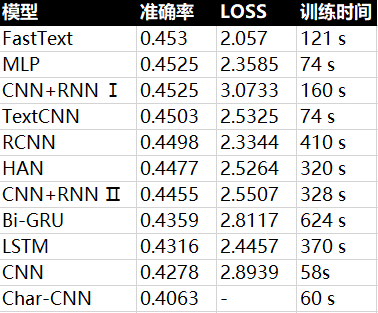
我们可以看到CNN模型的训练一般都比较快,性能也不算太差。可能是由于语料相对简单,简单的模型如FastText和MLP在准确率上名列前茅,精心设计的模型反而不如简单的模型,有点小题大作的意思。接下来,我们看看更加复杂的推特语料,这些复杂的模型会不会给我们带来一些惊喜呢?
推文情感分析
之前我提到其实,这个游戏标题分类任务并没有什么实际的意义,只是为了熟悉模型,小试牛刀,接下来我们来试试更大的数据集,比如推文的情感分析任务。标注好的情感分析任务可以当做文本分任务来处理。数据集来自密歇根大学的课程作业SI650 - Sentiment Classification 和由Niek Sanders收集的推文数据集,总共有大约157W条推文,目标变量为0或1,表示消极和积极的情感,是一个大数据集的二分类任务。文中提到使用朴素贝叶斯分类器可以达到75%的准确率,为了验证,我分别使用NB和SVM模型对全部数据集做了测试,NB的准确率在77.5%,SVM为73%。我们来看看深度学习模型是否会有大幅度的提升呢?
数据读入
# 导入要使用到的库
import csv
import pandas as pd
from nltk.tokenize import TweetTokenizer # a tweet tokenizer from nltk.
from sklearn.feature_extraction.text import CountVectorizer
from sklearn.feature_selection import SelectKBest, chi2
from sklearn.linear_model import LogisticRegressionCV
from sklearn.pipeline import Pipeline
from sklearn.model_selection import train_test_split
from keras.preprocessing.sequence import pad_sequences
from keras.preprocessing.text import Tokenizer
from keras.utils.np_utils import to_categorical
from keras.models import Sequential, Model
from keras.layers import Dense, Embedding, Activation, merge, Input, Lambda, Reshape
from keras.layers import Convolution1D, Flatten, Dropout, MaxPool1D, GlobalAveragePooling1D
from keras.layers import BatchNormalization
# 出师不利 碰到推文中有逗号,pandas无法解析
with open("tweets.csv", "r") as infile, open("quoted.csv", "wb") as outfile:
reader = csv.reader(infile)
writer = csv.writer(outfile)
for line in reader:
newline = [','.join(line[:-3])] + line[-3:]
writer.writerow(newline)
df = pd.read_csv('quoted.csv')
# 发现两个没有正确解析的样本,直接忽略好了
df = df.drop(df.index[[8834,535880]])
df['Sentiment'] = df['Sentiment'].map(int)
df.reset_index(inplace=True, drop=True)
# 为了之后读取方便,建议保存成python特有的pkl格式的文件
# 去除无效的列
df.drop(['ItemID', 'SentimentSource'], axis=1, inplace=True)
pd.to_pickle(df, 'tweet_dataset.pkl')
输入文本处理
# 刚开始想直接应用之前的处理方法,发现渣本由于显存太小,根本跑不起来
# 于是减少一些词汇量和输入文本的大小
# 随机抽取10W条推文
df = df.sample(100000)
# 先处理目标变量
Y = df.Sentiment.values
Y = to_categorical(Y)
# 分词
# 另外,nltk包还有一个内置的专门处理推特文本的分词器
tokenizer = Tokenizer(filters='!"#$%&()*+,-./:;<=>?@[\\]^_`{|}~\t\n',lower=True,split=" ")
tokenizer.fit_on_texts(df.SentimentText)
vocab = tokenizer.word_index
# 划分train/test set
x_train, x_test, y_train, y_test = train_test_split(df.SentimentText, Y, test_size=0.2, random_state=2017)
# 对文本进行编码(40是所有文本的90%左右的长度,超过的部分直接截去,不足的以0补足)
x_train_word_ids = tokenizer.texts_to_sequences(x_train)
x_test_word_ids = tokenizer.texts_to_sequences(x_test)
x_train_padded_seqs = pad_sequences(x_train_word_ids, maxlen=64)
x_test_padded_seqs = pad_sequences(x_test_word_ids, maxlen=64)
跑模型(以TextCNN为例)
这里我参照的是知乎看山杯比赛第一名的模型,是TextCNN的扩展版本。他在原先模型的基础上
- 使用两层卷积
- 使用更多的卷积核,更多尺度的卷积核
- 使用了BatchNorm
- 分类的时候使用了两层的全连接
总之就是更深更复杂,所以我也来试试,依样画葫芦。
main_input = Input(shape=(64,), dtype='float64')
embedder = Embedding(len(vocab) + 1, 256, input_length = 64)
embed = embedder(main_input)
# cnn1模块,kernel_size = 3
conv1_1 = Convolution1D(256, 3, padding='same')(embed)
bn1_1 = BatchNormalization()(conv1_1)
relu1_1 = Activation('relu')(bn1_1)
conv1_2 = Convolution1D(128, 3, padding='same')(relu1_1)
bn1_2 = BatchNormalization()(conv1_2)
relu1_2 = Activation('relu')(bn1_2)
cnn1 = MaxPool1D(pool_size=4)(relu1_2)
# cnn2模块,kernel_size = 4
conv2_1 = Convolution1D(256, 4, padding='same')(embed)
bn2_1 = BatchNormalization()(conv2_1)
relu2_1 = Activation('relu')(bn2_1)
conv2_2 = Convolution1D(128, 4, padding='same')(relu2_1)
bn2_2 = BatchNormalization()(conv2_2)
relu2_2 = Activation('relu')(bn2_2)
cnn2 = MaxPool1D(pool_size=4)(relu2_2)
# cnn3模块,kernel_size = 5
conv3_1 = Convolution1D(256, 5, padding='same')(embed)
bn3_1 = BatchNormalization()(conv3_1)
relu3_1 = Activation('relu')(bn3_1)
conv3_2 = Convolution1D(128, 5, padding='same')(relu3_1)
bn3_2 = BatchNormalization()(conv3_2)
relu3_2 = Activation('relu')(bn3_2)
cnn3 = MaxPool1D(pool_size=4)(relu3_2)
# 拼接三个模块
cnn = concatenate([cnn1,cnn2,cnn3], axis=-1)
flat = Flatten()(cnn)
drop = Dropout(0.5)(flat)
fc = Dense(512)(drop)
bn = BatchNormalization()(fc)
main_output = Dense(2, activation='sigmoid')(bn)
model = Model(inputs = main_input, outputs = main_output)
model.compile(loss='binary_crossentropy',
optimizer='adam',
metrics=['accuracy'])
history = model.fit(x_train_padded_seqs, y_train,
batch_size=32,
epochs=5,
validation_data=(x_test_padded_seqs, y_test))
可视化loss和准确率(更高级的可视化工具是Tensorflow的Tensorboard工具,这里只是简单看下)
import matplotlib.pyplot as plt
plt.subplot(211)
plt.title("Accuracy")
plt.plot(history.history["acc"], color="g", label="Train")
plt.plot(history.history["val_acc"], color="b", label="Test")
plt.legend(loc="best")
plt.subplot(212)
plt.title("Loss")
plt.plot(history.history["loss"], color="g", label="Train")
plt.plot(history.history["val_loss"], color="b", label="Test")
plt.legend(loc="best")
plt.tight_layout()
plt.show()
但是结果却不尽如人意,出现了严重的过拟合,最终取第二个batch结束后的准确率为76.75%,训练时间为520秒。由于这个模型比之前的模型都要复杂,即使使用了BN技术加速训练,仍旧需要10分钟左右的训练时间。本文使用的GPU为GTX1060(3GB)。什么时候能够拥有一台跑模型的服务器啊? T T
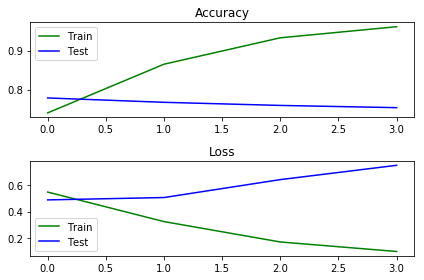
我们使用了复杂的模型和Adam优化器使得模型在训练集上表现出色,准确率不断提升。但是却在测试集上出现了过拟合。过拟合的解决思路一般有以下三点:
- 加入正则化技术,如L2正则项,dropout,BatchNormalization等
- 更多的训练数据,这里我们只使用了10%不到的数据,就已经超越了朴素贝叶斯使用全部数据集的准确率
- 调整超参数,这个是玄学,凭经验吧 - -
之前由于对几乎没有语义的游戏标题短文本,预训练的Glove词向量,并没有发挥作用。这次,我们再来看看是否有效?
读入Glove词向量
# 打开词向量文件,每一行的第一个变量是词,后面的一串数字是对应的词向量
GLOVE_DIR = "D:\python\kaggle\game_reviews\glove"
embeddings_index = {}
f = open(os.path.join(GLOVE_DIR, 'glove.6B.200d.txt'), encoding = 'utf-8')
for line in f:
values = line.split()
word = values[0]
coefs = np.asarray(values[1:], dtype='float32')
embeddings_index[word] = coefs
f.close()
# 预训练的词向量中没有出现的词用0向量表示
embedding_matrix = np.zeros((len(vocab) + 1, 200))
for word, i in vocab.items():
embedding_vector = embeddings_index.get(word)
if embedding_vector is not None:
embedding_matrix[i] = embedding_vector
# 模型中需要修改的仅仅是这里
embedder = Embedding(len(vocab) + 1, 200, input_length = 64, weights = [embedding_matrix], trainable = False)
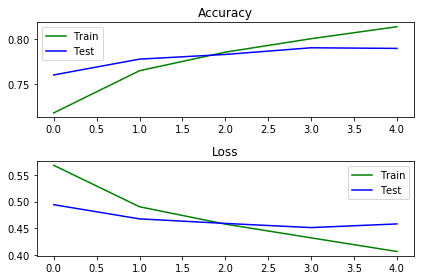
神奇的词向量,模型不再严重过拟合了,准确率进一步提升到了77.63%,训练时间缩短了一半!

为了证明之前的防过拟合策略是正确的,我们增加一倍的训练集,来看看效果。不出意外,果然提升了!至此,模型基本达到了我们想要的状态,准确进一步提升来到了79%,估计进行完整的调参的话,可以上到80%以上。
京东评论
我们再来试试中文的文本分类。中文天生有个坑需要去跨越,那就是分词,对于一般的文本,现有的分词工具已经能够出色地完成任务了。而面对网络文本,目前还没有看到有效的解决方案,这篇论文尝试使用Bi-LSTM+CRF的方法来实现深度学习模型分词器,有空可以来研究下。所以,本文目前还是使用的主流的分词工具结巴分词。
根据用户给的评分,5分视作好评,2,3,4分视作中评,1分视作差评。于是,我们便得到了目标类别,共三类。其实,中评的定义很模糊,用户自身也很难去判断,中评的文本中会有一定的好评或者差评的倾向性,对于文本分类造成一定的困难。
传统机器学习方法(TF-IDF + 朴素贝叶斯/SVM)
-
from sklearn.feature_extraction.text import CountVectorizer -
from sklearn.feature_extraction.text import TfidfTransformer -
from sklearn.naive_bayes import MultinomialNB -
from sklearn.pipeline import Pipeline -
from sklearn.pipeline import make_pipeline -
from sklearn.linear_model import SGDClassifier -
from sklearn import metrics -
from sklearn.model_selection import train_test_split -
from sklearn.model_selection import cross_val_score -
from data_helper_ml import load_data_and_labels -
import numpy as np -
categories = ['good', 'bad', 'mid'] -
# 我在data_helper_ml文件中定义了一些文本清理任务,如输入文本处理,去除停用词等 -
x_text, y = load_data_and_labels("./data/good_cut_jieba.txt", "./data/bad_cut_jieba.txt", "./data/mid_cut_jieba.txt") -
# 划分数据集 -
x_train, x_test, y_train, y_test = train_test_split(x_text, y, test_size=0.2, random_state=42) -
y = y.ravel() -
y_train = y_train.ravel() -
y_test = y_test.ravel() -
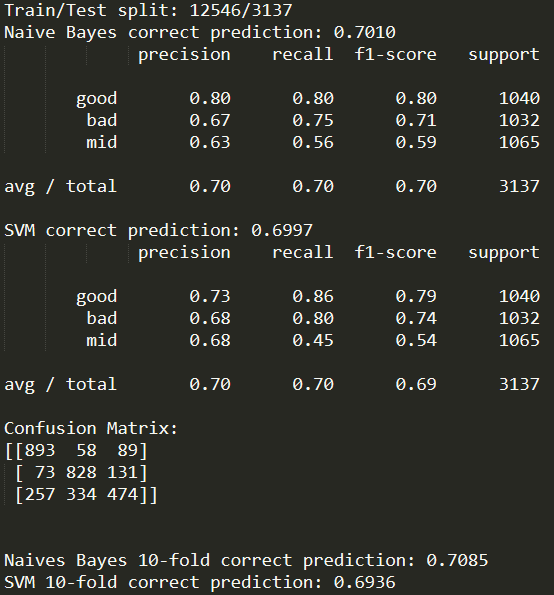
print("Train/Test split: {:d}/{:d}".format(len(y_train), len(y_test))) -
""" Naive Bayes classifier """ -
# sklearn有一套很成熟的管道流程Pipeline,快速搭建机器学习模型神器 -
bayes_clf = Pipeline([('vect', CountVectorizer()), -
('tfidf', TfidfTransformer()), -
('clf', MultinomialNB()) -
]) -
bayes_clf.fit(x_train, y_train) -
""" Predict the test dataset using Naive Bayes""" -
predicted = bayes_clf.predict(x_test) -
print('Naive Bayes correct prediction: {:4.4f}'.format(np.mean(predicted == y_test))) -
# 输出f1分数,准确率,召回率等指标 -
print(metrics.classification_report(y_test, predicted, target_names=categories)) -
""" Support Vector Machine (SVM) classifier""" -
svm_clf = Pipeline([('vect', CountVectorizer()), -
('tfidf', TfidfTransformer()), -
('clf', SGDClassifier(loss='hinge', penalty='l2', alpha=1e-3, max_iter= 5, random_state=42)), -
]) -
svm_clf.fit(x_train, y_train) -
predicted = svm_clf.predict(x_test) -
print('SVM correct prediction: {:4.4f}'.format(np.mean(predicted == y_test))) -
print(metrics.classification_report(y_test, predicted, target_names=categories)) -
# 输出混淆矩阵 -
print("Confusion Matrix:") -
print(metrics.confusion_matrix(y_test, predicted)) -
print('\n') -
""" 10-折交叉验证 """ -
clf_b = make_pipeline(CountVectorizer(), TfidfTransformer(), MultinomialNB()) -
clf_s= make_pipeline(CountVectorizer(), TfidfTransformer(), SGDClassifier(loss='hinge', penalty='l2', alpha=1e-3, n_iter= 5, random_state=42)) -
bayes_10_fold = cross_val_score(clf_b, x_text, y, cv=10) -
svm_10_fold = cross_val_score(clf_s, x_text, y, cv=10) -
print('Naives Bayes 10-fold correct prediction: {:4.4f}'.format(np.mean(bayes_10_fold))) -
print('SVM 10-fold correct prediction: {:4.4f}'.format(np.mean(svm_10_fold)))
结果如下图:
深度学习模型
# 读取经过jiaba分词后的三个数据文件
good_examples = list(open(good_data_file, "r", encoding='utf-8').readlines())
bad_examples = list(open(bad_data_file, "r", encoding='utf-8').readlines())
mid_examples = list(open(mid_data_file, "r", encoding='utf-8').readlines())
# 清理一些无效字符,clean为自定义函数
good_examples = [clean(sent) for sent in good_examples]
bad_examples = [clean(sent) for sent in bad_examples]
mid_examples = [clean(sent) for sent in mid_examples]
# 删除前后空格
good_examples = [i.strip() for i in good_examples]
bad_examples = [i.strip() for i in bad_examples]
mid_examples = [i.strip() for i in mid_examples]
# 去除清理过后的空文本, sent_filter为自定义函数
good_examples = sent_filter(good_examples)
bad_examples = sent_filter(bad_examples)
mid_examples = sent_filter(mid_examples)
X = good_examples + bad_examples + mid_examples
# 处理目标变量
good_labels = [[1, 0, 0] for _ in good_examples]
bad_labels = [[0, 1, 0] for _ in bad_examples]
mid_labels = [[0, 0, 1] for _ in mid_examples]
Y = np.concatenate([good_labels, bad_labels, mid_labels], 0)
为了照顾类别的平衡,在爬取数据的时候尽可能保持各个类别数量的相等,每个类别大约5200条评论左右。之后的步骤就很类似了,由于目前没有很好的中文预训练好的词向量文件,我们这里直接从原文本训练词向量。
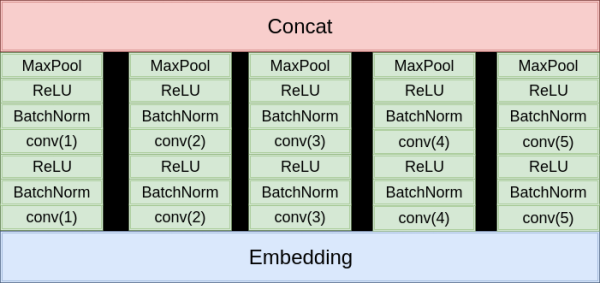
这里我们依旧仿照知乎看山杯的冠军作者来实现一个新的模型架构Inception,Inception的结构源于2015年ImageNet竞赛中的冠军模型的缩小版。模型和之前的TextCNNBN版本很相似,如下图所示:
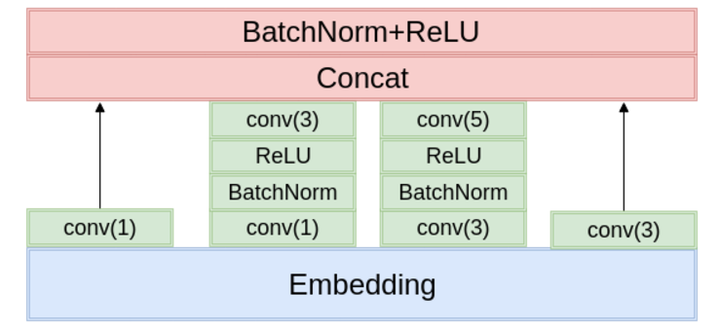
大家也可以自己动手来试试搭建这样一个Inception模型,代码我就不贴出来了:P
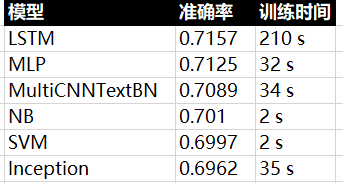
始终没有解决过拟合的问题,可能是数据问题,模型之间的差距并不明显,最终结果如下:
写在最后
我们来回顾下,我们至此学到了哪些内容。
- 文本分类任务的处理流程(文本清理编码-数据集的划分-模型搭建-模型运行评估)
- 传统机器学习模型的处理方法(Baseline:TF-IDF + 分类器)
- 常见的深度学习模型(CNN,RNN,Attention)
- 历年经典论文中的模型复现(TextCNN,RCNN,HAN等)
- 实战(多分类的小数据集,推文情感分析,京东评论好中差评)
最后给大家推荐一些高质量的学习资源: