分布式锁
在单机多线程环境下,访问共享资源需要保证操作的原子性,而锁机制能提供原子性。在分布式系统下同样需要锁,这就是分布式锁。与前者不同的是,我们需要一个分布式的锁服务。对于分布式所服务的实现,一般可以用关系型数据库、Redis 和 ZooKeeper 等实现。以下三个属性是有效使用分布式锁所需的最低保证:
- 互斥:在任何时候,只有一个客户端能获得锁。
- 无死锁:客户端始终可以获得锁。
- 容错能力:只要大多数Redis节点都处于运行状态,客户端就可以获取和释放锁。
Redis的分布式锁服务
单实例正确示范
获取锁
SET命令
要获取锁,必须遵循以下方法:
SET resource_name my_random_value NX PX 30000 ◠‿◠
该SET命令具有原子性,各项参数含义如下:
- resource_name:key。
- my_random_value: 必须全局唯一,这个随机数在释放锁时保证释放锁操作的安全性。
- NX:只会在 key 不存在的时候给 key 赋值。
- PX :通知 Redis 保存这个 key 30000ms。
释放锁
DEL命令
释放锁,就是把对应的key删掉,可能会使用DEL,来看看DEL会存在什么问题:
DEL key ︶︵︶
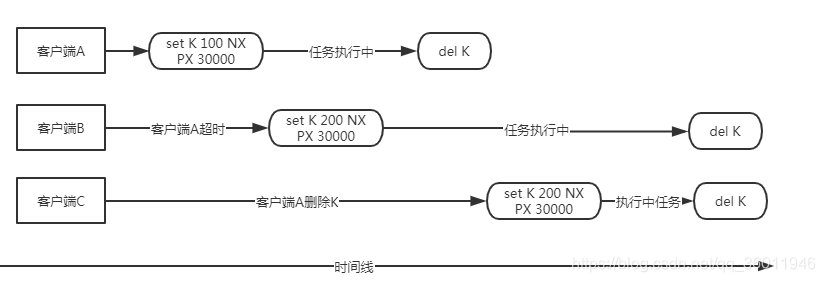
问题主要为:一个客户端可能会删除另一个客户端的锁。
- 客户端A获得锁K,由于被阻塞的时间超过了该锁的有效时间,Redis自动删除过期的锁。
- 客户端B获得锁K,在执行任务的过程中,由于客户端A任务执行完成,删除锁。
- 在客户端B未退出之前,客户端C请求锁K,请求成功。
相当于两个线程同时拥有同一个锁,没有到达锁的互斥要求,所以不推荐用del命令删除锁。
Lua脚本
基本上,使用随机值是为了以安全的方式释放锁,并且脚本会告诉Redis:仅当key存在且存储在key上的值恰好是我期望的值时,才删除该密钥。这是通过以下Lua脚本完成的:
if redis.call("get",KEYS[1]) == ARGV[1] then ◠‿◠
return redis.call("del",KEYS[1])
else
return 0
end
使用上述脚本时,每个锁都由一个随机字符串“签名”,因此仅当该锁仍是持有该锁的客户端尝试将其删除的设置时,该锁才会被删除。
Jedis实现
Jedis使用阻塞的I/O和redis交互,基于上面获得锁和释放锁的Redis操作提供Jedis实现代码如下。
¯¯__¯¯
//加锁和过期自动释放锁
while (!"OK".equals(jedis.set("resource_name", "my_random_value", "NX", "PX", 30000))){
try {
//休眠一秒再次尝试获取锁
Thread.sleep(1000);
} catch (InterruptedException e) {
logger.error("#####exception=[{}]", e.getMessage());
}
}
//执行到这里证明已经获得锁
//do something
//执行完后要释放锁
String script = "if redis.call('get', KEYS[1]) == ARGV[1] then return redis.call('del', KEYS[1]) else return 0 end";
//返回删除key的个数
Object result = jedis.eval(script, Collections.singletonList("resource_name"), Collections.singletonList("my_random_value"));
Jedis实现有以下不足:
-
无法支持重入
-
如果需要续期,需要增加额外的代码量
Redisson实现(推荐)
Redission通过Netty支持非阻塞I/O,封装了锁的实现,RLock继承了java.util.concurrent.locks.Lock的接口,让我们像操作我们的本地Lock一样去操作Redission的Lock,基于Redission的实现代码如下:
设置单实例:
config.useSingleServer().setAddress("redis://"120.0.0.1:6379");
代码实现:
RLock lock = redissonClient.getLock("resource_name"); ◠‿◠
//------------------------lock---------------------------------
//① 阻塞
// 获取锁并在10秒后自动解锁
lock.lock(10, TimeUnit.SECONDS);
lock.unlock();
//------------------------lock---------------------------------
//------------------------tryLock------------------------------
//② 阻塞100s后放弃请求锁
// 等待锁的获取时间长达100秒,获取锁并在10秒后自动解锁
boolean res = lock.tryLock(100, 10, TimeUnit.SECONDS);
if (res) {
try {
//do something
} finally {
lock.unlock();
}
}
//------------------------tryLock------------------------------
Redisson能够满足Jedis上述的不足,而且简化了代码量。【注】:lock和tryLock一般根据情况选择一个使用即可。
重入原理
定义:如果一个线程试图获取一个已经由它自己持有的锁,那个这个请求会成功。
redis中的数据结构:
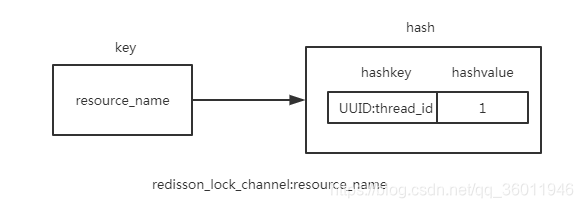
Redisson使用hash结构存储锁的信息,其中hashkey为UUID(Redisson初始化生成的全局ID)+当前线程ID,hashvalue就是上锁次数。如果当前线程再次请求锁时(hashkey的值一样),hashvalue的值加1。
上锁逻辑:
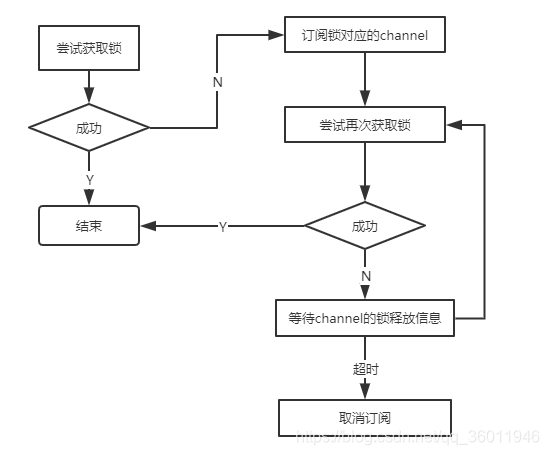
续期原理
为什么需要续期?
看看下图这种情况:
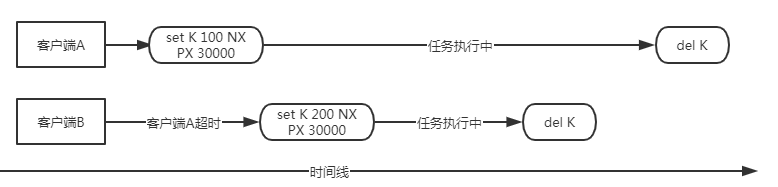
在上图描述的情况中,当客户端A被阻塞时长超过锁的有效时间,客户端B获得锁,并更新了资源后退出,但此时客户端A的阻塞条件被打破,把客户端B更新的资源覆盖掉了,造成了数据出错。只是由于客户端A持有锁的有效时间过期造成的,这就需要给锁续期。
原理:持有锁的客户端Redisson实例处于活跃状态时延长锁的到期时间,当其崩溃的时候也能防止持有的锁一直保持,有自动释放机制。默认情况下,lockWatchdog超时为30秒,可以通过Config.lockWatchdogTimeout设置进行更改(分布式锁的超时时间为30秒)。
默认情况下,锁的有效期为30秒,如果业务再行到 internalLockLeaseTime/3 ,即10秒的时候还没执行完,就会进行一次续期,重新设置锁的有效期为30秒。当遇到宕机时,续期任务无法运行,30秒后锁自动释放。
小结
以上介绍的都是同步阻塞式的可重入锁实现,关闭异步实现和除了可重入锁以外的其他锁实现,比如Fair Lock、ReadWriteLock、Semaphore、CountDownLatch等,可参考Redisson官方文档的第8章。
到此,单实例的分布式锁基本功能已实现,前面提到的分布式锁所需的最低保证均已满足,但在线上环境Redis大多数为集群模式,那单实例的实现已无法满足互斥和容错能力,这时就需要引入RedLock算法。
集群模式正确示范
基于故障转移的实现
主从、哨兵等实现的是基于故障转移的,为什么不适用基于故障转移的实现呢?
当Master宕机后,slaver选举为Master之前,无法保证原Master上的锁已同步到slaver上,因为Redis复制是异步的。
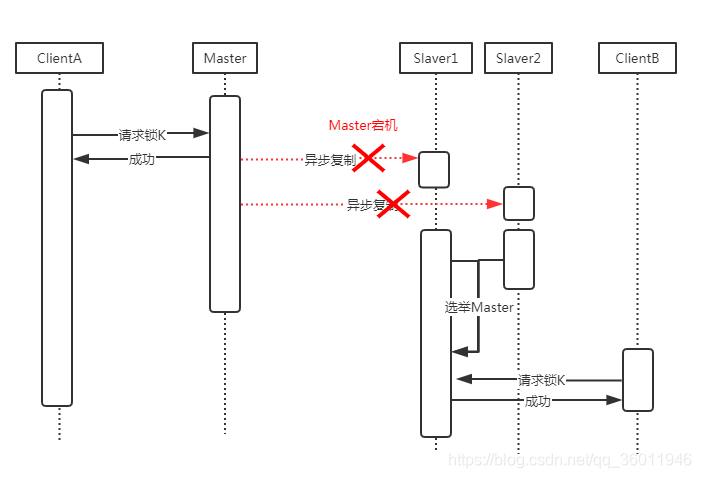
此模型存在明显的竞争条件:
- 客户端A获取主服务器中的锁。
- 在将密钥复制到Slaver之前,Master宕机。
- Slaver晋升为Master。
- 客户端B获取对相同资源K的锁定,而该资源K同时被客户端A锁定。安全违规!
RedLock(官方推荐)
为了获取锁,客户端执行以下操作:
-
它以毫秒为单位获取当前时间。
-
它尝试在所有N个实例中顺序使用所有实例中相同的键名和随机值来获取锁定。在第2步中,在每个实例中设置锁定时,客户端使用的超时时间小于总锁定自动释放时间,以便获取该超时时间。例如,如果自动释放时间为10秒,则超时时间可能在5到50毫秒之间。这样可以防止客户端长时间与处于故障状态的Redis节点通信时保持阻塞:如果一个实例不可用,我们应该尝试与下一个实例尽快通信。
-
客户端通过从当前时间中减去在步骤1中获得的时间戳,来计算获取锁所花费的时间。当且仅当客户端能够在大多数实例中获取锁时(N/2+1), 并且获取锁所花费的总时间小于锁有效时间,则认为已获取锁。
-
如果获取了锁,则其有效时间被视为初始有效时间减去在步骤3中计算的经过的时间。
-
如果客户端由于某种原因无法获取锁(无法锁定N/2+1实例或有效期为负),它将尝试解锁所有实例(甚至是它认为无法锁定的实例)。
// 源码 failedLocksLimit:允许失败的客户端数量 protected int failedLocksLimit() { return this.locks.size() - this.minLocksAmount(this.locks); } protected int minLocksAmount(List<RLock> locks) { return locks.size() / 2 + 1; }
代码实现:
RLock lock1 = redissonClient1.getLock("resource_name"); ◠‿◠
RLock lock2 = redissonClient2.getLock("resource_name");
RLock lock3 = redissonClient3.getLock("resource_name");
RedissonRedLock redLock = new RedissonRedLock(lock1, lock2, lock3);
//------------------------lock---------------------------------
//① 阻塞
// 获取锁并在10秒后自动解锁
redLock.lock(10, TimeUnit.SECONDS);
redLock.unlock();
//------------------------lock---------------------------------
//------------------------tryLock---------------------------------
//② 阻塞100s后放弃请求锁
// 等待锁的获取时间长达100秒,获取锁并在10秒后自动解锁
try {
redLock.tryLock(100, 10, TimeUnit.SECONDS);
} catch (InterruptedException e) {
e.printStackTrace();
} finally {
redLock.unlock();
}
//------------------------tryLock---------------------------------
【注】:和单实例一样,lock和tryLock一般根据情况选择一个使用即可。
至此,已给出RedLock的实现,如果需要了解更多信息,可参考Redis官方算法Redlock。
MySQL的分布式锁服务
悲观锁
在MySQL中新建一张锁表,加锁时往数据库中添加一条记录,释放时删除这条数据。
-
互斥?
一个字段,锁标识,唯一性约束。
-
超时释放?
一个字段,记录锁的过期时间,定时任务过期清理。
-
重入?
一个字段,记录当前线程的ID;
-
非阻塞?
while循环,直到成功为止,或者等待超时返回。
我们可以得到如下一张表:
CREATE TABLE `lock_tbale` (
`id` bigint(20) NOT NULL AUTO_INCREMENT,
`lock_flag` varchar(255) NOT NULL COMMENT '锁标识',
`expire_time` datetime DEFAULT NULL COMMENT '过期时间',
`thread_id` varchar(255) NOT NULL COMMENT '线程id',
PRIMARY KEY (`id`),
UNIQUE KEY `lock_flag` (`lock_flag`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4 COLLATE=utf8mb4_0900_ai_ci;
加锁的SQL语句:
INSERT INTO lock_tbale(lock_flag,expire_time,thread_id) values
('lock_flag','2020-02-04 12:00:00','123456789');
释放锁的SQL语句:
DELETE FROM lock_tbale WHERE lock_flag = 'lock_flag';
重入的SQL语句:
SELECT * FROM lock_tbale WHERE thread_id = '123456789' AND lock_flag = 'lock_flag';
查询到有数据时表示可重入,没数据时在加锁。
悲观锁有着明显的缺点,悲观锁的实现依赖于数据库提供的唯一性约束来保存互斥,依赖于代码逻辑来做阻塞(while循环),当有大量流量请求同一个锁时,这些流量全部落在MySQL上,这无疑是毁灭性的灾难,所以悲观锁的实现不太适合高并发场景。
乐观锁
乐观锁的实现方式是在原来表的基础上添加一个版本号,更新数据前,先把这个版本号读出来,更新数据时加上这个版本号条件,只有当数据库里的版本号等于查询出来的版本号时,更新才成功,更新成功后加1,更新语句大概可以写成下面这样:
UPDATE table_name SET xxx = #{xxx},version=version+1 where version =#{version};
乐观锁也有着一些不知之处:
- 资源表要添加一个version字段;
- 如果一个操作涉及多张表,则每张表的版本号都得查一次;
小结
不论是悲观锁还是乐观锁,用MySQL来实现分布式锁都是不推荐的,其性能,可靠性,以及实现的复杂度上都没有良好的表现,所以,MySQL的实现只能作为一种备选。
未完待续…
GitHub:https://github.com/pikaxiao/SpringFamily
参考
- Redis官方文档.
- Redisson官方文档.
