(获得武汉疫情历史数据)紧急上线
最近看了很多人都在询问武汉疫情的历史数据,很难获得,估计也只有一些新闻客户端有这东西。方法还是有的,唯一注意的就是可能获得的数据不全面,只能获得到全球各个国家的数据。
接下来介绍方法,如何获得全球的历史数据。
总统介绍就是:先从who网站上下载报告(pdf),然后用R提取报告里面的表格。
进入网站下载表格:
网站为:
https://www.who.int/emergencies/diseases/novel-coronavirus-2019/situation-reports
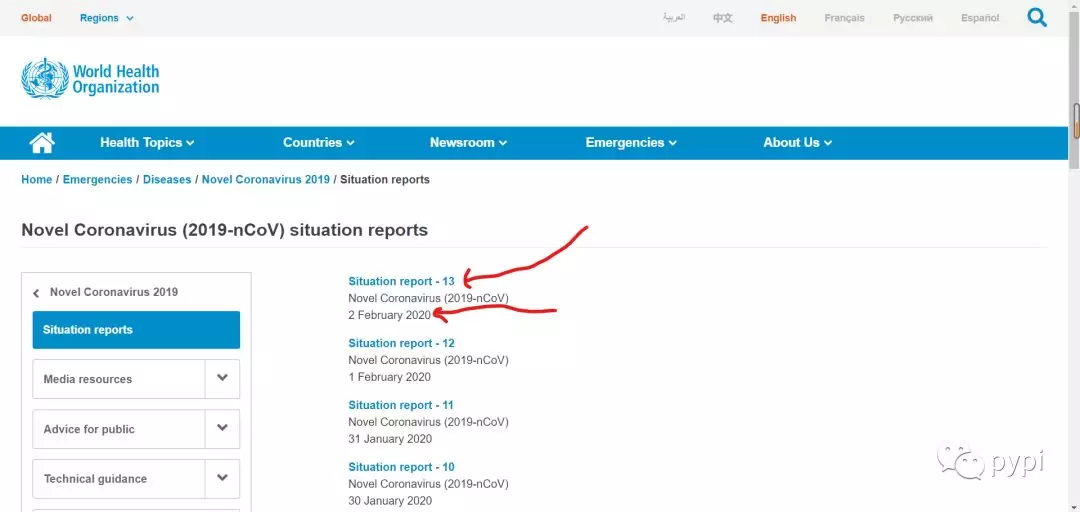
进入网站就会看到一串列表,点击就会发现pdf,下面是报告的时间。
我使用的是chrome浏览器,点击右边的进行下载,
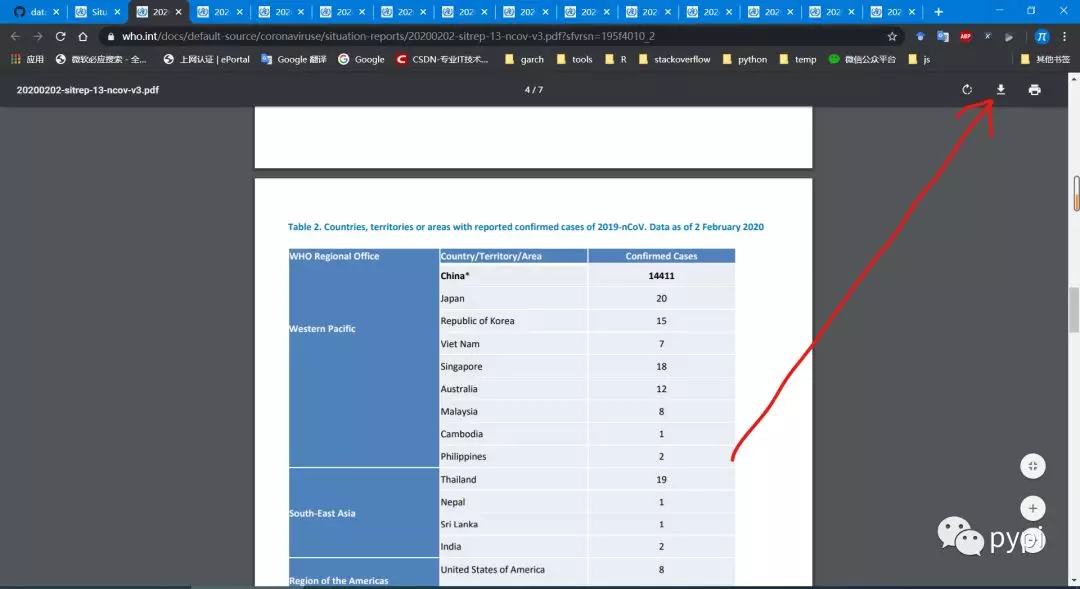
或者:
将鼠标放在1处,然后鼠标右键选择2, 这个时候已经复制了链接:接下来将链接复制到Rstudio里面。

写成下面的样子:
url <- 'https://www.who.int/docs/default-source/coronaviruse/situation-reports/20200202-sitrep-13-ncov-v3.pdf?sfvrsn=195f4010_2'
library(pdftools)
library(magrittr)
who_text <- pdf_text(url) %>%
readr::read_lines()
第一行代码就是刚才复制的链接,第三行就是用来加载R处理pdf的包,第四行就是用来加载使用管道函数的包。
第五行和第六行就是使用pdf_text函数读取url(这个时候如果使用科学上网,加载的速度可能更快一点),然后用readr的read_lines函数处理,然后得到who_text。
这个时候,就是需要定位表格的位置,直接在控制台输入who_text。然后就会返回一串字符串。

上面这样的缩放肯定看不到,你只要按住crtl和-键。可以多按几次,就可以不断缩小视图。如下:(如果要恢复,只要按crtl 和 键)
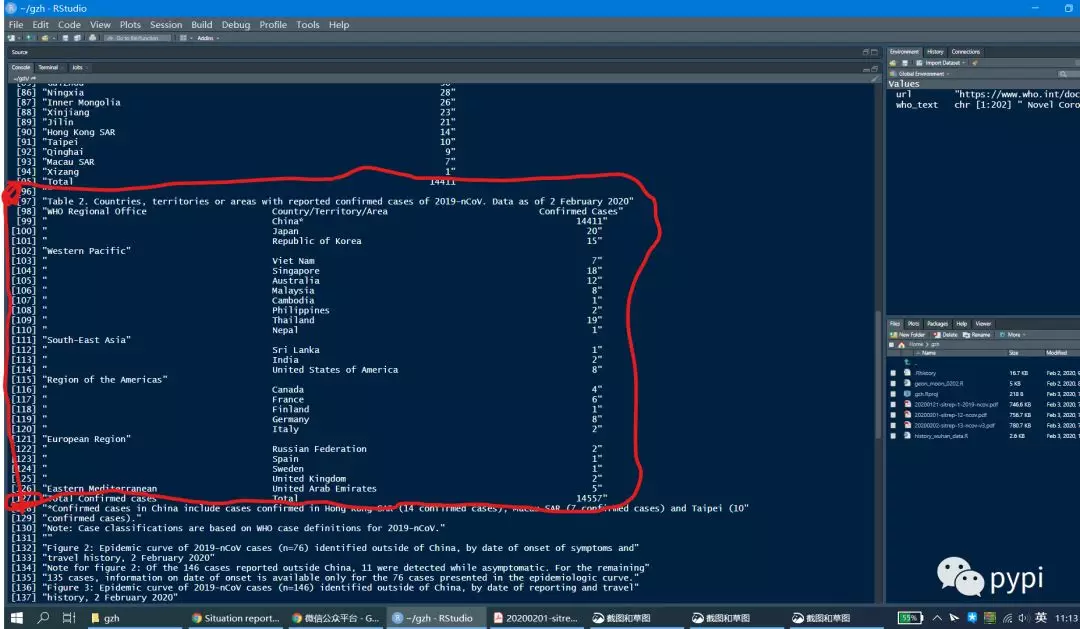
可以看到表头(对应的who_text的98行),如下:
[98] "WHO Regional Office Country/Territory/Area Confirmed Cases"
表尾(对应的who_text的127行], 如下:
# [127] "Total Confirmed cases Total 14557"
在确定表头表尾的位置和,使用如下函数:
get_foreign_data <- function(who_text, start_table, end_table){
library(stringr)
table_foreign <- who_text[start_table:end_table]
country <- c()
country_num_conf <- c()
for (i in seq(length(table_foreign))) {
temp_char_1 <- str_trim(unlist(str_split(table_foreign[i], ' ')))
temp_char_1 <- ifelse(temp_char_1 == '', NA, temp_char_1)
temp_char_2 <- temp_char_1[!is.na(temp_char_1)]
if (length(temp_char_2) == 3) {
country_temp <- temp_char_2[2]
num_conf <- temp_char_2[3]
} else if (length(temp_char_2) == 2) {
country_temp <- temp_char_2[1]
num_conf <- temp_char_2[2]
} else if (length(temp_char_2) == 1) {
country_temp <- NA
num_conf <- NA
}
country <- c(country, country_temp)
country_num_conf <- c(country_num_conf, num_conf)
}
data_foreign <- data.frame(country = country,
num_conf = country_num_conf)
data_foreign <- data_foreign[!is.na(data_foreign$country), ]
data_foreign$country <- as.character(data_foreign$country)
data_foreign$num_conf <- as.character(data_foreign$num_conf)
return(data_foreign)
}
上面的代码不解释了,主要就是提取表头和表尾内的数据(不包括表头和表尾)。
代码如下:
get_foreign_data(who_text = who_text, start_table = 99, end_table = 126)
将刚才的who_text传递进去,除去表头的第一行就是98 1 = 99,不包括表尾的是127-1=126行。
然后就出现结果:
# country num_conf
# 1 China* 14411
# 2 Japan 20
# 3 Republic of Korea 15
# 5 Viet Nam 7
# 6 Singapore 18
# 7 Australia 12
# 8 Malaysia 8
# 9 Cambodia 1
# 10 Philippines 2
# 11 Thailand 19
# 12 Nepal 1
# 14 Sri Lanka 1
# 15 India 2
# 16 United States of America 8
# 18 Canada 4
# 19 France 6
# 20 Finland 1
# 21 Germany 8
# 22 Italy 2
# 24 Russian Federation 2
# 25 Spain 1
# 26 Sweden 1
# 27 United Kingdom 2
# 28 United Arab Emirates 5
#
#
上面只是针对网站第13个列表,可以使用相同的函数提取别的pdf。但是只能用来提取各个国家的数据。就是国内的数据都不行(因为我发现只有几个pdf包含了中国各个省的数)。但是我的代码也写了:
get_china_data <- function(who_text, start_table, end_table) {
table <- who_text[start_table:end_table]
cities <- c()
cities_num_conf <- c()
for (i in seq(length(table))){
cell_temp <- unlist(stringr::str_split(table[i], ' '))
cities <- c(cities, head(cell_temp, 1))
cities_num_conf <- c(cities_num_conf, tail(cell_temp, 1))
}
china_province <- data.frame(cities = as.character(cities),
num_conf = as.numeric(as.character(cities_num_conf)))
return(china_province)
}
get_china_data(who_text = who_text, start_table = 61, end_table = 94)
第15行就是运行代码,和上面的一样,也就是获得表头、表尾的位置,然后提取出各个行的对应的开始和结束位置。
