以下是我自己个人学习Mybatis框架的一些学习笔记,所以记录的都是自己个人的东西,可能没有那么全面。主要是为了方便日后自己查看,欢迎大家留言讨论,一起学习一起进步!!
1.mybatis和hibernate
前者半自动,后者全自动 --->ORM(对象关系映射)2.mybatis底层都是对jdbc的封装
3.mybatis数据处理层的流程:
参数映射-->SQL解析-->SQL执行-->结果映射4.mybatis工作原理图:

5.属性和成员变量的区别
属性是指实体类的set方法,去掉set,然后首字母小写,这个就是属性!!例如setName,name就是属性而private String name --->是成员变量
对外提供set的才是属性!因为可以修改。而成员变量是私有的不能直接修改。
可以结合spring的配置文件设置来理解,并不是所以的成员变量都能修改,只有对外提供了set方法的才算属性,才能修改!
6.mybatis要配置两个xml文件。
一个是mybatis-config.xml名字可以随意,配置的是mybatis的一些配置
一个是mybatis-mapper.xml文件,一般是一个dao对应一个mapper文件。
7.mybatis的xml文件的头文件约束:
mybatis配置文件的头文件约束:
<?xml version="1.0" encoding="UTF-8" ?> <!DOCTYPE configuration PUBLIC "-//mybatis.org//DTD Config 3.0//EN" "http://mybatis.org/dtd/mybatis-3-config.dtd">
8.idea编译器复制类的全路径
在idea中,如果选中一个文件,然后右击,copy path的话是全限定性路劲,包含电脑盘符的,一般不用这种。我们用copy Reference 引用!!直接鼠标放的光标在一个类上就可以了,不管有没有打开这个类。
9.什么时候要写classpath
一般location属性的要加classpath: 而resource直接右击copy Reference 快捷键就是shift+ctril+alt+c就可以了10.mybatis用xml配置的流程
- 配置mybatis-config文件,要配置properties,environments,mappers
- 配置mapper文件,一般是一个实体类对应一个mapper,这里注意,namaspace自定义一般用实体类的全限定名,下面的每一个sql标签都有一个id值,也可以自定义,一般跟dao层的方法名称相同
- 配置mapper文件,一般是一个实体类对应一个mapper,这里注意,namaspace自定义一般用实体类的全限定名,下面的每一个sql标签都有一个id值,也可以自定义,一般跟dao层的方法名称相同
- 一般写个工具类,直接获取到sqlSession对象。
- sqlSession对象是单实例线程安全的!
- 扩展:Servlet也是单实例的,如果存在可以修改的参数,则会存在线程安全问题!
11.为什么sqlSessionFactoryBuider不需要关闭输入流
sqlSessionFactoryBuilder.build--->源码会自动关闭输入流,所有不用我们手动关12.typeAliases设置类的别名
在mybatis-config中配置,没卵用,一般不配,因为项目中的类非常多,写全限定性命好维护。13.插入对象后如何返回对象的id主键
mybatis中,插入对象后,返回该对象的id,需要加这个:<selectKey keyProperty="id" order="AFTER" resultType="java.lang.Long">
SELECT LAST_INSERT_ID()
</selectKey>
直接加载select标签内部就可以了!!mysql的是after,oracle的是before
14.mybatis中自带的常见的基本类型、封装类型、集合类型的别名:
已经为许多常见的 Java 类型内建了相应的类型别名。它们都是大小写不敏感的,需要注意的是由基本类型名称重复导致的特殊处理。基本类型:

常用包装类型:

最好还是写全限定性名吧!!!好维护!!不会错!!不过也不用担心,后面有mybatis逆向工程,很多东西都是直接根据数据库表自动生成的!!
15.框架项目搭建命名规范:
dao包里:xxxMapper接口,比如student表,就建一个StudentMapper接口,接口里有增删改查操作方法
mapper包里:xxxMapper.xml,namaspace就写对应的mapper接口的全限定性名,下面对应的sql语句的id就写接口对应的方法名
dao包的实现类:xxxMapperImpl,实现类里面是通过sqlSession对象进行增删改查的操作,一般这个后期直接由spring整合,进行动态映射处理
配置文件:mabatis-config.xml
16.关于sql操作,如果只有一个参数,且参数是基本类型的话,一般这样操作,例如:
<!--一般来说参数是一个的,且参数类型是基本类型的话,#{}仅仅只是代表占位符
不过最好还是写跟参数的名字一样吧,这样好看一些
-->
<delete id="deleteById" parameterType="integer">
<!--delete from student where id=#{xxx}-->
delete from student where id=#{id}
</delete>
17.新增,修改,删除,一般没有resultType或者resultMap。
18.selSession.seleceOne方法
如果是根据单一属性,例如根据name啊,id啊,则应该用selectOne的方法!!不是select
19.#{}和${}的区别
#{}--->用的占位符,底层用PreparedStatement,效率高${}--->用的是字符串拼接,底层用的Statement,效率低,有sql注入风险如果一个sql参数是字符串需要拼接的话,有两中写法,根据nama模糊查询若用#{},则需像这样写:concat('%',#{name},'%') 这个值可以随便写,一般建议和参数名相同若用${},则需像这样写:'%${value}%' 这个值必须写value!!建议使用#{}效率高,还没有sql注入风险!!20.jdbc:mysql:///databaseName 3个杠表示本机,默认端口3306的快捷写法!!
21.mapper的动态代理! 两个很重要的点
- mapper文件的namaspace为接口的全限定接口名
- xml中的sql语句的id和接口的方法名相同
通过sqlSession.getMapper(Class对象) 返回的就是我们的mapper接口,底层使用的是jdk的proxy代理,例如:
private AnimalMapper animalMapper;
@Before
public void before(){
SqlSession sqlSession = MybatisUtils.getSqlSession();
animalMapper=sqlSession.getMapper(AnimalMapper.class);
}
下面的代码只需要调用animalMapper就可以了。
就不需要像以前一样再定义mapper的实现类,然后再获取sqlSession,然后再调用sqlSession的方法来curd操作这么麻烦了!!
22.多查询条件的解决方法(Map方式解决)
其实也就是放在map中,再把map丢给接口去查。Map<String,Object> map----->封装多个参数,丢给mapper.xml文件就可以了
#{xxx}--->可以是占位符,可以是对象的属性,也可以是map中的key
如:map.put("name","张三");
#{name}---->"张三"
如果放的是对象,如 map.put("stu",student) 想要拿这个student里面的东西,需要这么写#{stu.name}
22.多查询条件的解决方法(索引方式解决)
例如mapper接口中有这个方法void insert(String name,int age);
那么在mapper.xml中可以这么写,#{0},#{1} 索引从0开始
23.#{}的存放信息总结
- 参数对象的属性,例如参数是student对象,那么#{name},就是拿这个student对象的name属性
- 随意内容,一般是基本数据类型,且参数为1个时,此时为占位符,建议与参数名称相同
- 参数为map时,#{key}
- 参数为map中的对象时,#{key.field}
- 参数的索引,#{0},#{1}......从0开始! 一般如果是多个参数的话,parameterType就不指定了
24.在xml文件中绝对不能出现的符号:
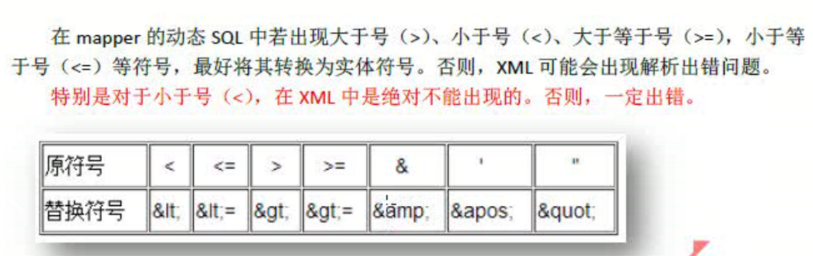
25.动态sql:
参考网址: http://www.mybatis.org/mybatis-3/zh/dynamic-sql.html
动态if标签<if test="name!=null and name!=' ' ">
动态where标签
用来解决where 1=1的问题!!因为当数据量非常大的时候执行效率的问题。虽然select * from student 和select * from student where 1=1 查询结果相同。
但是当数据量较大时,后者的效率会大大下降
效率低下的写法:
<select id="selectAll" resultType="com.mybatisDynamicProxy.entity.Animal">
select * from animal
where 1=1
<if test="name!=null and name!=''">
and name like concat('%',#{name},'%')
</if>
<if test="age!=null and age !=0">
and age>#{age}
</if>
</select>
高效的写法: 每个if都加上and,第一个条件拼接会自动去掉and
<select id="selectAll" resultType="com.mybatisDynamicProxy.entity.Animal">
select * from animal
<where>
<if test="name!=null and name!=''">
and name like concat('%',#{name},'%')
</if>
<if test="age!=null and age !=0">
and age>#{age}
</if>
</where>
</select>
3.choose标签,when标签,otherwise标签,就跟java中的switch一样。when标签时选择中了后面的就不管了!if标签时一个个都执行。
4.foreach标签

就是如果遍历的泛型是自定义类型,比如自定义对象,那么item属性就是代表一个对象,下面要用这个对象里面的属性,比如item="student",如果要用对象里面的name属性,就要用这样的格式#{student.name}
<select id="selectByIds" parameterType="list" resultType="com.mybatisDynamicProxy.entity.Animal">
select * from animal
<where>
<foreach collection="list" item="animal" open="id in (" close=")" separator=",">
#{animal.id}
</foreach>
</where>
</select>
26.先插一句题外话:
resultMap中如果是collection属性,也就是一对多的情况,里面用ofType属性如果是association属性,也就是多对一的情况,一个学生,每个学生属性里面都有一个学校的属性。里面用javaType
resultMap更详细的解释是resultMapping,结果映射。不要想成map集合,虽然来说map集合也可以理解,但是mapping更贴切吧!
27.多种关系如何封装成resultMap,关联查询!!
1对多-->
有两种解决方式,一种是通过多表关联查询,还有一种是通过多表单独查询。后者可以使用延迟加载!!下面直接贴xml文件。不在解释
多表关联查询:
<resultMap id="baseMap" type="com.one2many.entity.School">
<id column="schid" property="id"/>
<result column="schname" property="name"/>
<collection property="students" ofType="com.one2many.entity.Student">
<id column="stuid" property="id"/>
<result column="stuname" property="name"/>
</collection>
</resultMap>
<select id="selectAll" resultType="com.one2many.entity.School" resultMap="baseMap">
SELECT
*
FROM
student,
school
WHERE
student.schid=school.schid
</select>
也就是说只用一个查询语句,在resultMap中设置好,就ok了,直接全部封装好了!!这种方式不能延迟加载
多表单独查询:
<resultMap id="baseMap" type="com.one2many.entity.School">
<id column="schid" property="id"/>
<result column="schname" property="name"/>
<collection property="students"
ofType="com.one2many.entity.Student"
select="selectStus" column="schid"/>
<!--这里的column就是根据哪个列,然后把那个列的值传给引入的select-->
<!--collection对应ofType,association对应javaType-->
</resultMap>
<resultMap id="StudnetMap" type="com.one2many.entity.Student">
<id column="stuid" property="id"/>
<result column="stuname" property="name"/>
</resultMap>
<select id="selectStus" resultMap="StudnetMap">
select * from student where schid=#{schid}
</select>
<select id="selectAll" resultType="com.one2many.entity.School" resultMap="baseMap">
select * from school
</select>
多对1-->
跟1对多差不多,就是多个学生,对应一个学校。每个学生属性里面都会有一个学校的属性。
就是那个resultMap中写association,然后用javaType就可以了!
自关联--->
自己的理解是员工表,员工有上级领导。所有也是存在一对多,多对一的关系。
像parent_ids,leader,这种字段,自关联的主键id。
1.自关联,一对多(1)
查询子孙的,不包含传入的那个参数的数据!!比如我传的是1,查出来的是所有老板以下的所有员工的关系。但是没有包含老板。
<resultMap id="EmployeeMap1" type="com.mybatis.oneself.dao.Employee">
<id column="id" property="id"/>
<result column="name" property="name"/>
<collection property="employeeList"
ofType="com.mybatis.oneself.dao.Employee"
column="id"
select="selectChildrenByParent"/>
<!--这里的select选择非常关键,就相当于循环递归调用自己-->
</resultMap>
<select id="selectChildrenByParent" resultMap="EmployeeMap1">
select id,name from employee where pid=#{pid}
</select>
2.自关联,一对多(2)
查询自身以及所有的子孙,比如传了1,老板也查出来,老板以下的也都查出来!
<resultMap id="EmployeeMap" type="com.mybatis.oneself.dao.Employee">
<id column="id" property="id"/>
<result column="name" property="name"/>
<collection property="employeeList"
ofType="com.mybatis.oneself.dao.Employee"
select="selectChildrenByParent"
column="id"/>
<!--这里非常关键,就相当于循环递归调用自己-->
<!--先把自己查出来,然后把自己的id当做pid传给另外一个查询,然后那个查询就是上面递归调用的方法是一样的!-->
</resultMap>
<select id="selectChildrenByParent" resultMap="EmployeeMap">
select id,name from employee where pid=#{pid}
</select>
<select id="selectEmployeeById" resultMap="EmployeeMap">
select * from employee where id=#{id}
</select>
3.自关联,多对一。
一个员工对应一个上级!也就是resultMap改来改去,然后resultMap标签里面的select选择以及column的选择!!就是说,resultMap中的select语句要用哪个column的值作为子查询的值!!再次强调下ofType和javaType,一个集合类型的,一个单个类型的。
多对多--->
(就是两个一对多构成的!!)中间关联表是多方!!,学生表和课程表是一方一个表只要有外键的,就是多方!反过来说,外键肯定是在多方的!
就是通过第三张表关联起来,比如学生选课表
一个学生对应多个课程,一个课程也对应多个学生!!(现实模型)
程序就跟上面的差不多。
如果要延迟加载,则必须要用到子查询。即在resultMap中的association或者collection中引入select标签!
28.延迟加载,就是sql的执行时间
主查询没法设置,会直接加载。而从查询可以配置延迟加载,加载时机。
(主表、关联表)
关联对象的加载时机(子查询):
- 直接加载:直接查
- 侵入式延迟:关联对象的详情侵入到了主加载对象的详情里面了!!
- 深度延迟:子查询一开始不查,只有真正访问关联对象时才回去查
<settings>
<!--日志-->
<setting name="logImpl" value="LOG4J"/>
<!--是否开启延迟加载,这个是总开关,false的话下面的也没用!-->
<setting name="lazyLoadingEnabled" value="true"/>
<!--是否开启侵入式延迟加载-->
<setting name="aggressiveLazyLoading" value="false"/>
</settings>
在mybatis-config.xml配置文件中设置。
个人理解:
第一个直接加载不说了。
第二个,侵入式加载--->是指,一开始进行关联对象的查询,但是,如果主加载对象进行访问,就算没有访问到关联对象,那么关联对象的详情也会进行查询操作!!比如主是School,从是Student,查询School,如果访问School的详情,就算不访问School里面的Student属性,Student的详情在这个时候也会进行查询!这就是侵入式加载!
第三个,延迟加载,只有访问到School的Student的里面的属性,确确实实访问到了Student的属性,那么才开始查询操作。
延迟加载只能适用在多表单独查询,对于多表连接查询是没有用的!!
29.缓存的处理
缓存有作用域和生命周期,作用域是根据namespace来区分的!
一级缓存:
一级缓存,默认开启,且不能关闭,生命周期是单个sqlSession,sqlSession如果关闭了,那么就没有了。而二级缓存是整个应用环境的!缓存数据在多个sqlSession之间共享!
一级缓存的证明,以及查询缓存的依据:

注意:如果进行了增删改的操作,那么缓存都会被清空,不管是不是一个namespace下的,因为本身也可以是交叉业务。缓存会被清空哦!!
二级缓存:
内置二级缓存的开启与验证
注意:在二级缓存下如果进行了增删改的操作,只会把那个namespace下的缓存的entry的value设为了null,key还是存在的。所有,如果是其他namespace的二级缓存还是存在的,这一点跟一级缓存不一样,一级缓存是全部清空。所有这边二级缓存的设置有一些属性,比如大小,满了以后怎么操作?刷新时间?
如果想要二级缓存不清楚,需要设置flushcache为false!!
二级缓存的关闭:
局部关闭就是在sql标签加上useCache属性为false全局关闭需要在mybatis配置文件中的setting标签中配置name=CacheEnabled 属性为false
二级缓存使用原则:
- 多个namespace不要操作同一张表
- 不要在关联关系表上执行增删改操作
- 查询多余增删改的时候
综上,实际项目中的表都是千丝万缕的关系,几乎很少是单表的。所有几乎用不到二级缓存,因为用不好了就会产生数据不一致的情况!!一般来说,都是用局部的二级缓存!!比如,那个mapper接口想要用二级缓存就在哪个mapper接口对应的xml中,配置cache属性!!
使用第三方二级缓存:
不多介绍了,百度mybatis如何使用第三方二级缓存即可。30.mybatis的注解式开发
首先,官方并不推荐注解式开发,还是建议xml方式的开发。注解还是挺简单的,具体有什么注解,可以到mybatis的注解的包下看看,一查便知。如果想要注解生效,需要再配置文件中的mappers标签中用package标签,引入mapper接口所在的包。以前是使用mapper标签引入xml映射文件。
@MapKey这个注解
可以用用,其他的主键个人不建议。
返回的是以MapKey注解里面额值为key,以返回对象的map对象key-value的形式,注意不是直接返回对象哦!mapper接口这样写:
@MapKey("name")
Map<String,Map<Object,Object>> selectAll();
xml文件这样写:
<select id="selectAll" resultType="java.util.Map">
select * from employee
</select>
31.mybatis与spring的整合
注册一个 MapperScannerConfigurer
1.配置basePacke属性--->就是mapper接口,因为在这边已经配过了,所有mybatis的主配置文件那边就不用再配置了!!
2。配置sqlSessionFactoryBeanName属性,就是刚刚上面那个
这是我项目中的整合xml文件:
spring-mybatis.xml
<?xml version="1.0" encoding="UTF-8"?>
<beans xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xmlns:context="http://www.springframework.org/schema/context"
xmlns="http://www.springframework.org/schema/beans"
xsi:schemaLocation="http://www.springframework.org/schema/beans
http://www.springframework.org/schema/beans/spring-beans.xsd
http://www.springframework.org/schema/context
http://www.springframework.org/schema/context/spring-context.xsd">
<context:property-placeholder location="classpath:properties/*.properties"/>
<bean id="dataSource" class="com.alibaba.druid.pool.DruidDataSource">
<property name="username" value="${driver.username}"/>
<property name="password" value="${driver.password}"/>
<property name="url" value="${driver.url}"/>
<property name="driverClassName" value="${driver.class}"/>
</bean>
<!--配置sqlSessionFactoryBean对象-->
<bean id="sqlSessionFactory" class="org.mybatis.spring.SqlSessionFactoryBean">
<property name="dataSource" ref="dataSource"/>
<property name="configLocation" value="classpath:mybatis-config2.xml"/>
<property name="mapperLocations" value="classpath:mapper/*.xml"/>
</bean>
<!--配置Mapper自动扫描器-->
<bean class="org.mybatis.spring.mapper.MapperScannerConfigurer">
<property name="sqlSessionFactoryBeanName" value="sqlSessionFactory"/>
<property name="basePackage" value="com.mybatis.**.dao"/>
</bean>
</beans>
mybatis-config.xml
<?xml version="1.0" encoding="UTF-8" ?>
<!DOCTYPE configuration
PUBLIC "-//mybatis.org//DTD Config 3.0//EN"
"http://mybatis.org/dtd/mybatis-3-config.dtd">
<configuration>
<settings>
<!--日志-->
<setting name="logImpl" value="LOG4J"/>
</settings>
</configuration>当然啦,这个config还可以配置很多其他的东西,像分页的插件啊,缓存啊等等。
然后,就是写实体类和Dao层接口的时候,名字对应上,还有Dao层的接口和mapper.xml中的namespace要对应,方法要和sql语句的id对应。
差不多就这些东西了。