1.Stream流由来
首先我们应该知道:Stream流的出现,主要是用在集合的操作上。在我们日常的工作中,经常需要对集合中的元素进行相关操作。诸如:增加、删除、获取元素、遍历。
最典型的就是集合遍历了。接下来我们先举个例子来看看 JDK8 Stream流式操作出现之前,我们对集合操作的过程,从中来了解一下 JDK8 之前集合操作数据的弊端。
Demo:现在有一个List集合,集合中有如下数据:"张无忌"、"周芷若"、"杨逍"、"张强"、"张三丰"、"赵敏"
需求:1.拿到所有姓"张"的名字 2.拿到长度为3个字的名字 3.将最终结果进行打印
/**
* TODO JDK8前遍历集合 Vs JDK8 Stream()流遍历集合
*
* @author liuzebiao
* @Date 2020-1-7 17:49
*/
public class Demo {
public static void main(String[] args) {
List<String> list = new ArrayList<>();
Collections.addAll(list,"张无忌","周芷若","杨逍","张强","张三丰","赵敏");
/**
* 需求:
* 1.拿到所有行"张"的名字
* 2.拿到长度为3个字的名字
* 3.将最终结果进行打印
*/
//JDK8 以前遍历操作集合
/*****************多次for循环********************/
//1.1 拿到所有行"张"的名字
List<String> zhangList = new ArrayList<>();
for (String name : list) {
if(name.startsWith("张")){
zhangList.add(name);
}
}
//1.2.拿到长度为3个字的名字
List<String> threeList = new ArrayList<>();
for (String name : zhangList) {
if(name.length()==3){
threeList.add(name);
}
}
//1.3.将最终结果进行打印
for(String name : threeList){
System.out.println(name);
}
/*******************2.一次for循环********************/
for (String name : list) {
if(name.startsWith("张") && name.length() == 3){
System.out.println(name);
}
}
//JDK8 以后使用Stream()流遍历操作集合
/**************3.使用 Stream流来操作******************/
list.stream()
.filter(name->name.startsWith("张"))
.filter(name->name.length()==3)
.forEach(name-> System.out.println(name));
}
}JDK8之前,(示例中一次for循环除外)当我们面对一个集合多次 for循环的问题,则需要多次遍历集合来完成操作。针对这个问题,JDK8中引入了 Stream 流式操作,便能够解决多次 for 循环的弊端。
使用stream流式操作,直接阅读代码的字面意思即可完美展示无关逻辑方式的语义:①获取流 ② 过滤姓张 ③过滤长度为3 ④遍历打印。我们真正要做的事情内容便能够被更好的体现在代码中。
2.Stream流式思想
注意:Stream流 和 IO 流(InputStream/OutputStream)没有任何关系,请暂时忘记对传统IO流的固有印象。
Stream流式思想类似于工厂车间的"生产流水线",Stream流不是一种数据结构,不保存数据,而是对数据进行加工处理。Stream 可以看做是流水线上的一个工序。在流水线上,通过多个工序让一个原材料加工成一个商品。

3.获取Stream流的两种方式
java.util.stream.Stream<T> 是 JDK8 新加入的流接口。获取一个流非常简单,有以下两种常用的方式:
1.所有的 Collection 集合都可以通过 .stream() 方法来获取流;
扫描二维码关注公众号,回复: 8970826 查看本文章
2.使用 Stream 接口的 .of() 静态方法,可以获取流。
/**
* TODO 获取 Stream 流的两种方式
*
* @author liuzebiao
* @Date 2020-1-7 17:09
*/
public class getStreamDemo {
public static void main(String[] args) {
//方式1:根据Collection获取流
//Collection接口中有一个默认的方法:default Stream<E> stream()
//1.List获取流
List<String> list = new ArrayList<>();
Stream<String> stream01 = list.stream();
//2.Set获取流
Set<String> set = new HashSet<>();
Stream<String> stream02 = set.stream();
//3.Map获取流
//Map 并没有继承自 Collection 接口,所有无法通过该 map.stream()获取流。但是可用通过如下三种方式获取:
Map<String,String> map = new HashMap<>();
Stream<String> stream03 = map.keySet().stream();
Stream<String> stream04 = map.values().stream();
Stream<Map.Entry<String, String>> stream05 = map.entrySet().stream();
//方式2:Stream中的静态方法of获取流
// static<T> Stream<T> of(T... values)
// T... values:可变参数,实际原理就是可变数组(传递String数组进去)
//1.字符串获取流
Stream<String> stream06 = Stream.of("aa", "bb", "cc");
//2.数组类型(基本类型除外)
String[] strs = {"aa","bb","cc"};
Stream<String> stream07 = Stream.of(strs);
//3.基本数据类型的数组
int[] arr = {1,2,3,4};
//看着没报错,但是看到返回值是 int[],这是 Stream流把整个数组看做一个元素来操作,而不是操作数组中的int元素
Stream<int[]> stream08 = Stream.of(arr);
}
}4.Stream流常用方法
Stream流模型的操作很丰富,这里介绍一些常用的API。这些方法可以被分成两种类型:
| 方法名 | 方法作用 | 返回值类型 | 方法种类 |
| count | 统计个数 | long | 终结 |
| forEach | 遍历(逐一处理) | void | 终结 |
| filter | 过滤 | Stream | 函数拼接 |
| limit | 取用前几个 | Stream | 函数拼接 |
| skip | 跳过前几个 | Stream | 函数拼接 |
| map | 映射 | Stream | 函数拼接 |
| concat | 组合 | Stream | 函数拼接 |
- 终结方法:返回值类型不再是 Stream 类型的方法,不再支持链式调用。本小节中,终结方法包括 count() 和 forEach() 方法;
- 非终结方法:又叫函数拼接方法。值返回值类型仍然是 Stream 类型的方法,支持链式调用(除了终结方法外,其与方法均为非终结方法)
5.Stream流使用注意事项
- Stream流只能操作一次;
- Stream方法返回的是新的流;
- Stream不调用终止方法,中间的操作不会执行。
6.Stream流常用方法
提醒:以下所有代码部分,能简化部分尽量简化,均使用最简格式!!!
1.forEach()
void forEach(Consumer<? super T> action);forEach() 方法用来遍历流中的数据,是一个终结方法。该方法接收一个 Consumer 接口函数,会将每一个流元素交给该函数进行处理。示例如下:
public class StreamDemo{
public static void main(String[] args){
List<String> list = new ArrayList<>();
Collections.addAll(list,"Mary","Lucy","James","Johson","Steve");
//forEach()遍历
//未简写
//list.forEach((String str)->{
// System.out.println(str);
//});
//简写1
//list.forEach(str-> System.out.println(str));
//最终简写
list.forEach(System.out::println);
}
}测试结果:
Mary
Lucy
James
Johson
Steve2.count()
long count();count() 方法,用来统计集合中的元素个数,是一个终结方法。该方法返回一个 long 值代表元素个数,示例如下:
public class StreamDemo {
public static void main(String[] args){
List<String> list = new ArrayList<>();
Collections.addAll(list,"Mary","Lucy","James","Johson","Steve");
//count()计算集合中元素个数
long count = list.stream().count();
System.out.println("元素个数为:"+count);
}
}测试结果:
元素个数为:53.filter()
Stream<T> filter(Predicate<? super T> predicate);filter() 方法,用于过滤数据,返回符合过滤条件的数据,是一个非终结方法。我们可以通过 filter() 方法将一个流转换成另一个子集流。该接口接收一个 Predicate 函数式接口参数(可以是一个 Lambda 或 方法引用) 作为筛选条件。
因为 filter() 是一个非终结方法,所以必须调用终止方法。示例如下:
public class StreamDemo {
public static void main(String[] args){
List<String> list = new ArrayList<>();
Collections.addAll(list,"Mary","Lucy","James","Johson","Steve");
//filter()过滤,返回以"J"开头的名字
list.stream().filter(str->str.startsWith("J")).forEach(System.out::println);
//使用BiPredicate,就搞复杂了,如下,没啥意思(只会让人看不懂,哈哈)
//BiPredicate<String,String> consumer = String::startsWith;
//list.stream().filter(str->consumer.test(str,"J")).forEach(System.out::println);
}
}测试结果:
James
Johson4.limit()
Stream<T> limit(long maxSize);limit() 方法,用来对 Stream 流中的数据进行截取,只取用前 n 个,是一个非终结方法。参数是一个 long 型,如果集合当前长度大于参数则进行截取,否则不进行操作。因为 limit() 是一个非终结方法,所以必须调用终止方法。示例如下:
public class StreamDemo {
public static void main(String[] args){
List<String> list = new ArrayList<>();
Collections.addAll(list,"Mary","Lucy","James","Johson","Steve");
//limit()截取,截取list集合前三个元素
list.stream().limit(3).forEach(System.out::println);
}
}测试结果:
Mary
Lucy
James5.skip()
Stream<T> skip(long n);如果希望跳过前几个元素,去取后面的元素,则可以使用 skip()方法,获取一个截取之后的新流,它是一个非终结方法。参数是一个 long 行,如果 Stream 流的当前长度大于 n,则跳过前 n 个,否则将会得到一个长度为 0 的空流。因为 limit() 是一个非终结方法,所以必须调用终止方法。示例如下:
public class StreamDemo {
public static void main(String[] args){
List<String> list = new ArrayList<>();
Collections.addAll(list,"Mary","Lucy","James","Johson","Steve");
//skip()跳过list集合前2个元素,获取剩下的元素
list.stream().skip(2).forEach(System.out::println);
}
}测试结果:
James
Johson
Steve备注:
使用 skip() 和 limit() 方法,即可实现类似分页的操作了。示例如下:
//一页10条 分页操作
//第一页
skip(0).limit(10)
//第二页
skip(10).limit(10)
//第三页
skip(20).limit(10)
...6.map()
<R> Stream<R> map(Function<? super T, ? extends R> mapper);map() 方法,可以将流中的元素映射到另一个流中。即:可以将一种类型的流转换为另一种类型的流,map() 方法是一个非终结方法。该接口需要一个 Function 函数式接口参数,可以将当前流中的T类型数据转换为另一种R类型的流。
因为 map() 方法是一个非终结方法,所以必须调用终止方法。通过如下示例,使用 map() 方法,通过方法引用,便将字符串类型转换成了 Integer 类型。示例如下:
public class StreamDemo {
public static void main(String[] args){
List<String> list = new ArrayList<>();
Collections.addAll(list,"11","22","33","44","55");
//通过map()方法,可以将String类型的流转换为int类型的流
/*list.stream().map((String str)->{
return Integer.parseInt(str);
}).forEach((Integer num) -> {
System.out.println(num);
});*/
//简化:
//list.stream().map(str->Integer.parseInt(str)).forEach(str->System.out.println(str));
//简化后:
list.stream().map(Integer::parseInt).forEach(System.out::println);
}
}测试结果:
11
22
33
44
557.sorted()
sorted() 方法,可以用来对 Stream 流中的数据进行排序。sorted()方法共有以上两种情况:
//根据元素的自然规律排序
Stream<T> sorted();
//根据比较器指定的规则排序
Stream<T> sorted(Comparator<? super T> comparator);因为 sorted() 方法是一个非终结方法,所以必须调用终止方法。
场景:①sorted() 方法:按照自然规律,默认为升序排序。
②sorted(Comparator comparator) 方法,按照指定的比较器规则排序(以降序为例)。 示例如下:
public class StreamDemo {
public static void main(String[] args){
//sorted():根据元素的自然规律排序
Stream<Integer> stream01 = Stream.of(66,33,11,55);
stream01 .sorted().forEach(System.out::println);
//sorted(Comparator<? super T> comparator):根据比较器规则降序排序
Stream<Integer> stream02 = Stream.of(66,33,11,55);
stream02 .sorted((i1,i2)-> i2-i1).forEach(System.out::println);
}
}测试结果:
11
33
55
66
----
66
55
33
118.distinct()
Stream<T> distinct();distinct() 方法,可以用来去除重复数据。因为 distinct() 方法是一个非终结方法,所以必须调用终止方法。
去除重复数据,此处有几种情况:①基本类型去重 ②String类型去重 ③引用类型去重(对象去重)
①②使用 distinct() 方法可以直接去重 ③对象类型需要重写 equals() 和 hasCode() 方法,使用 distinct() 方法才能去重成功。示例如下:
public class StreamDemo {
public static void main(String[] args){
//基本类型去重
Stream<Integer> stream01 = Stream.of(66,33,11,55,33,22,55,66);
stream01 .distinct().forEach(System.out::println);
//字符串去重
Stream<String> stream02 = Stream.of("AA","BB","AA");
stream02.distinct().forEach(System.out::println);
//自定义对象去重
//(Person对象类,有String name,Integer age 两个属性,两参数构造器,get/set()方法,重写了equals(),hashCode(),toString()方法。此处就不附Person实体类了)
BiFunction<String,Integer,Person> fn1 = Person::new;
Stream<Person> stream14 = Stream.of(fn1.apply("西施", 18), fn1.apply("貂蝉", 20), fn1.apply("王昭君", 22), fn1.apply("杨玉环", 23), fn1.apply("杨玉环", 23));
stream14.distinct().forEach(System.out::println);
}
}测试结果:
66
33
11
55
22
----
AA
BB
----
Person{name='西施', age=18}
Person{name='貂蝉', age=20}
Person{name='王昭君', age=22}
Person{name='杨玉环', age=23}9.match()
//allMatch 全匹配(匹配所有,所有元素都需要满足条件-->返回true)
boolean allMatch(Predicate<? super T> predicate);
//anyMatch 匹配某个元素(只要有一个元素满足条件即可-->返回true)
boolean anyMatch(Predicate<? super T> predicate);
//noneMatch 匹配所有元素(所有元素都不满足指定条件-->返回true)
boolean noneMatch(Predicate<? super T> predicate);match() 方法,可以用来判断 Stream 流中的数据是否匹配指定的条件。allMatch()、anyMatch()、noneMatch() 方法都是终结方法,返回值为 bollean。示例如下:
public class StreamDemo {
public static void main(String[] args){
Stream<Integer> stream01 = Stream.of(5, 3, 6, 1);
boolean allMatch = stream01.allMatch(i -> i > 0);
System.out.println("allMatch匹配:"+allMatch);
Stream<Integer> stream02 = Stream.of(5, 3, 6, 1);
boolean anyMatch = stream02 .anyMatch(i -> i > 5);
System.out.println("anyMatch匹配:"+anyMatch);
Stream<Integer> stream03 = Stream.of(5, 3, 6, 1);
boolean noneMatch = stream03 .noneMatch(i -> i < 3);
System.out.println("noneMatch匹配:"+noneMatch);
}
}测试结果:
allMatch匹配:true
anyMatch匹配:true
noneMatch匹配:false10.find()
Optional<T> findFirst();
Optional<T> findAny();findFirst() 、findAny() 方法,都是用来查找 Stream 流中的第一个元素。返回值为 Optional<T>,意味着有可能找到也有可能找不到的情况。示例如下:
public class StreamDemo {
public static void main(String[] args){
//findFirst()
Stream<Integer> stream01 = Stream.of(33, 11, 22, 5);
Optional<Integer> first = stream01.findFirst();//返回 Optional,意味着可能找到,可能找不到
System.out.println(first.get());//调用get获取值
//findAny()
Stream<Integer> stream02 = Stream.of(33, 11, 22, 5);
Optional<Integer> any = stream02.findAny();
System.out.println(any.get());
}
}测试结果:
33
3311.max() 和 min()
Optional<T> max(Comparator<? super T> comparator);
Optional<T> min(Comparator<? super T> comparator);max() 和 min() 方法,用来获取 Stream 流中的最大值和最小值。该接口需要一个 Comparator 函数式接口参数,根据指定排序规则来获取最大值,最小值。
为了保证数据的准确性,此处排序规则需要是升序排序。因为:max() 方法获取的是排序后的最后一个值,min() 方法获取的是排序后的第一个值。如果使用降序排序后,那么 max() 和 min() 方法就相反了,就有异常了。示例如下:
public class StreamDemo {
public static void main(String[] args){
//max()
Stream<Integer> stream01 = Stream.of(33, 11, 22, 5);
Optional<Integer> max = stream01.max((i1, i2) -> i1 - i2);
System.out.println("最大值:"+max.get());
//min()
Stream<Integer> stream02 = Stream.of(33, 11, 22, 5);
Optional<Integer> min = stream02.min((i1, i2) -> i1 - i2);
System.out.println("最小值:"+min.get());
}
}测试结果:
最大值:33
最小值:512.reduce()
//1.
Optional<T> reduce(BinaryOperator<T> accumulator);
//2.
T reduce(T identity, BinaryOperator<T> accumulator);
//3.
<U> U reduce(U identity,BiFunction<U, ? super T, U> accumulator,BinaryOperator<U> combiner);接下来进行参数介绍:
//1.
Optional<T> reduce(BinaryOperator<T> accumulator); -->无默认值(可能为空,所以返回 Optional<T> 类型)
//2.
T reduce(T identity, BinaryOperator<T> accumulator); -->有默认值(所以返回类型为 T)
//T identity:默认值
//BinaryOperator<T> accumulator:对数据进行处理的方式
//提醒:BinaryOperator<T> 接口继承自 BiFunction,实际上使用的还是 BiFunction<T, U, R>中的apply()方法,因为apply(T t,U u)有两个参数,
// 所以 在下面你会看到 BinaryOperator<T> accumulator 这个参数传递的是(x,y) 两个参数。如果需要将 Sream 流中的所有数据,归纳得到一个数据的情况,可以使用 reduce() 方法。如果需要对 Stream 流中的数据进行求和操作、求最大/最小值等(都是归纳为一个数据的情况),此处就可以用到 reduce() 方法。示例如下:
public class StreamDemo {
public static void main(String[] args){
//reduce():求和操作
Stream<Integer> stream01 = Stream.of(4,3,5,6);
Integer sum = stream01.reduce(0,(x,y)-> x + y);
System.out.println("求和:"+sum);
//reduce():求最大值操作
Stream<Integer> stream01 = Stream.of(4,3,5,6);
Integer sum = stream01.reduce(0,(x,y)-> x + y);
System.out.println("最大值为:"+sum);
}
}测试结果:
最大值:33
最小值:5结果分析:(求和分析)
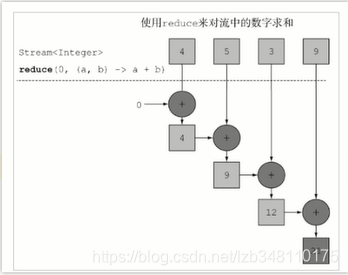
求和流程: 第一次:将默认值赋值给x,取出集合第一个元素赋值给y 第二步:将上一次返回的结果赋值给x,取出集合第二个元素赋值给y 第三步:继续执行第二步(如下图所示)
13.map() 和 reduce()方法组合使用
map() 和 reduce() 方法组合使用,可以解决很多日常工作中遇到的问题。我们就从如下场景了解:
场景一:现在有一个 Person 类,有两个属性:name 和 age,新建四个 Person类,然后完成如下操作:① 求出所有年龄的总和 ②求出 Person 类中的最大年龄
public class StreamDemo {
/**
* map() 和 reduce() 方法组合使用
*/
public static void main(String[] args){
BiFunction<String,Integer,Person> fn2 = Person::new;
//1.求出所有年龄的总和(年龄为int值,默认为0,此处可以使用待默认值的reduce()方法)
Stream<Person> stream01 = Stream.of(fn2.apply("刘德华", 58), fn2.apply("张学友", 56), fn2.apply("郭富城", 54), fn2.apply("黎明", 52));
//基本写法:
//Integer total = stream01.map(p -> p.getAge()).reduce(0,(x, y) -> x + y);
//(方法引用)简化后:
Integer total = stream01.map(p -> p.getAge()).reduce(0,Integer::sum);
System.out.println("年龄总和为:"+total);
//2.找出最大年龄
Stream<Person> stream02 = Stream.of(fn2.apply("刘德华", 58), fn2.apply("张学友", 56), fn2.apply("郭富城", 54), fn2.apply("黎明", 52));
//基本写法:
//Integer maxAge = stream02.map(p -> p.getAge()).reduce(0, (x, y) -> x > y ? x : y);
//(方法引用)简化后:
Integer maxAge = stream02.map(p -> p.getAge()).reduce(0, Integer::max);
System.out.println("最大年龄为:"+maxAge);
}
}测试结果:
年龄总和为:220
最大年龄为:58场景二:统计字符串 "a" 出现的次数
public class StreamDemo {
public static void main(String[] args){
Stream<String> stream03 = Stream.of("a", "b", "c", "d", "a", "c", "b", "a");
//map() 和 reduce() 方法组合使用
Integer aTotal = stream03.map(str -> {
if (str == "a") {
return 1;
} else {
return 0;
}
}).reduce(0, Integer::sum);
System.out.println("a次数:"+aTotal);
}
}测试结果:
a次数:314.mapToInt()/mapToDouble()/mapToLong()
//mapToInt()
IntStream mapToInt(ToIntFunction<? super T> mapper);
//mapToLong()
LongStream mapToLong(ToLongFunction<? super T> mapper);
//mapToDouble()
DoubleStream mapToDouble(ToDoubleFunction<? super T> mapper);我们通过 Stream<Integer> stream = Stream.of(1,2,3,4,5); 这种方式,返回值为 Stream<Integer> 这种包装类的泛型,这种方式虽然用起来没有问题,但是它在效率上还是存在着一定的问题。
当我们将一对数字转成 Stream 流时,因为泛型的原因,只能使用 Integer 包装类。会先把这些数字包装成 Integer 类。
//1.Integer是一个类,占用的内存肯定比 int 大
//2.Stream流在操作时,会存在自动装箱和拆箱操作
Stream<Integer> stream = Stream.of(2,3,5,6,7);
//把大于3的打印出来(num在Stream流中是Integer类型,在与3比较时,显然会存在自动拆装箱问题),效率会有影响
stream.filter(num -> num > 3).forEach(System.out::println);所以在 JDK8 中,对 Stream 流还新增了一个 mapToInt()方法。该方法可以将流中操作的 Integer 包装类,在 Stream 流中转换成直接来操作 int 类型,效率明显会高一点。
源码分析:
IntStream mapToInt(ToIntFunction<? super T> mapper);
//此时 mapToInt() 接收一个 ToIntFunction 的函数式接口
//接下来我们来分析参数:ToIntFunction<? super T> mapper
@FunctionalInterface
public interface ToIntFunction<T> {
/**
* Applies this function to the given argument.
*
* @param value the function argument
* @return the function result
*/
int applyAsInt(T value);
}
//我们发现:ToIntFunction 是一个函数式接口,里面仅有一个抽象方法 applyAsInt(),
//applyAsInt() 方法:接收一个参数 ,返回一个int型。接下来我们便知道如何使用Lambda表达式来使用 mapToInt() 方法了示例如下:
public class StreamDemo {
public static void main(String[] args){
//使用 mapToInt()方法
IntStream intStream = Stream.of(1, 2, 3, 4, 5, 6).mapToInt((Integer num) -> {
return num.intValue();
});
//(使用方法引用)简化后
IntStream intStream1 = Stream.of(1, 2, 3, 4, 5, 6).mapToInt(Integer::intValue);
intStream1.filter(n->n>3).forEach(System.out::println);
/**
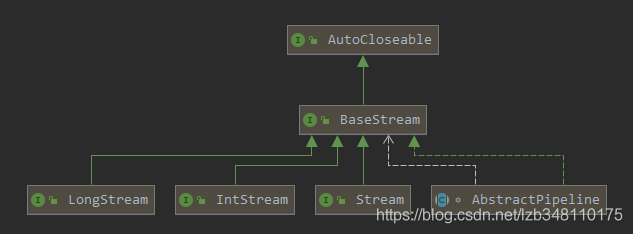
* 使用mapToInt(),返回值是一个IntStream类型.我们看一下它们的继承结构图(如下所示):
* IntStream 和 Stream<Integer> 类型进行比较。发现他们都继承自 BaseStream。所以它们区别不大
* 只不过 IntStream 内部操作的是 int 基本类型的数据,省去自动拆装箱过程。从而可以节省内存开销
*/
}
}集成机构图:
提示:
mapToDouble() / mapToLong() 的使用,与 mapToInt()一致,此处不再介绍。
15.concat()
public static <T> Stream<T> concat(Stream<? extends T> a, Stream<? extends T> b) {
Objects.requireNonNull(a);
Objects.requireNonNull(b);
@SuppressWarnings("unchecked")
Spliterator<T> split = new Streams.ConcatSpliterator.OfRef<>(
(Spliterator<T>) a.spliterator(), (Spliterator<T>) b.spliterator());
Stream<T> stream = StreamSupport.stream(split, a.isParallel() || b.isParallel());
return stream.onClose(Streams.composedClose(a, b));
}concat() 方法,可以将两个Stream流合并成一个流进行返回。如果是三个流,则需要两两合并,不能一次性合并三个流。concat() 方法是 Stream 接口的静态方法,我们可以直接使用【类名.方法名】调用。
注意:
concat() 方法此处接收的是 Stream 类型,不能接收 IntStream 等类型。concat() 是一个静态方法,与 java.lang.String 中的 concat() 方法是不同的。
示例如下:
public class StreamDemo {
public static void main(String[] args){
//concat()方法
Stream<Integer> aStream = Stream.of(1, 2, 3);
Stream<Integer> bStream = Stream.of(4, 5, 6);
Stream<Integer> concatStream = Stream.concat(aStream, bStream);
concatStream.forEach(System.out::println);
}
}测试结果:
1
2
3
4
5
616.collect()
collect() 方法的使用,也有很多内容学习,此处内容过多,不做一一列举。
如需了解 Stream 流 collect() 方法的使用介绍,你可以看博主另一篇文章学习了解。请点击如下链接跳转:Stream流 collect() 方法的详细使用介绍
附:JDK8新特性(目录)
本目录为 JDK8新特性 学习目录,包含JDK8 新增全部特性的介绍。
如需了解,请跳转链接查看:我是跳转链接
集合之 Stream 流式操作,介绍到此为止
文章都是博主精心编写,如果本文对你有所帮助,那就给我点个赞呗 ^_^
End
