栈——后进先出
栈(stack)又名堆栈,它是一种运算受限的线性表。限定仅在表尾进行插入和删除操作的线性表。这一端被称为栈顶,相对地,把另一端称为栈底。向一个栈插入新元素又称作进栈、入栈或压栈,它是把新元素放到栈顶元素的上面,使之成为新的栈顶元素;从一个栈删除元素又称作出栈或退栈,它是把栈顶元素删除掉,使其相邻的元素成为新的栈顶元素。
栈的定义
-
栈(stack):是限定仅在表尾进行插入或删除操作的线性表。因此,对于栈来说,表尾端有其特殊含义,称为栈顶(top),相应的,表头端称为栈底(bottom)。不含元素的空表称为空栈。
栈存储结构示意图:

由图可知,栈只能从表的一端存取数据,另一端是封闭的。因此,我们可以形象的认为:
栈是一种只能从表的一端存取数据且遵循 “先进后出” 原则的线性存储结构。
栈的抽象数据类型定义
ADT Stack{
数据对象:D={ai | ai∈ElemSet, i=1,2,…,n,n≥0}
数据关系:R={ <a(i-1) , ai> | a(i-1), ai ∈D,i=1,2,…n} 约定a(n)为栈顶,a1为栈底
基本操作:
InitStack(&S)
// 构造一个空栈S
DestoryStack(&S)
// 销毁栈S
ClearStack(&S)
// 将S清为空栈
StackEmpty(S)
// 若栈S为空栈,返回true,否则返回false
StackLength(S)
// 返回S的元素个数,即栈的长度
GetTop(S)
// 返回S的栈顶元素,不修改栈顶指针
Push(&S,e)
// 插入元素e为新的栈顶元素
Pop(&S,&e)
// 删除S的栈顶元素,并用e返回其值
StackTraverse(S)
//从栈底到栈顶依次对S的每个数据元素进行访问
}ADT Stack
栈的应用
由于栈的操作具有后进先出的固有特性,使得栈成为程序设计中的有用工具。另外,如果问题求解的过程具有“后进先出”的天然特性,则求解的算法中也必然需要利用“栈”。
- 数制转换
- 括号匹配的检验
- 行编辑程序
- 迷宫求解
- 表达式求值
- 八皇后问题
- 函数调用
- 递归调用的实现
栈与一般线性表比较

顺序栈
顺序栈:即利用顺序表实现栈存储结构。
顺序栈的表示和实现
顺序栈的定义
//---------顺序栈的存储结构--------
#define MAXSIZE 100 //顺序栈存储空间的初始分配量
typedef struct
{
SElemType *base; //栈底指针
SElemType *top; //栈顶指针
int stacksize; //栈可用最大容量
}SqStack;
顺序栈的初始化
- 顺序栈的初始化操作就是为顺序栈动态分配一个预定义大小的数组空间。
Status InitStack(SqStack &S)
{ //构造一个空栈
S.base = new SElemType[MAXSIZE]; //为顺序栈动态分配一个最大容量为MAXSIZE的数组空间
//或 S.base = (SElemType*)malloc(MAXSIZE*sizof(SElemType));
if (!S.base) exit (OVERFLOW); //存储分配失败
S.top = S.base ; //栈顶指针等于栈底指针,top = base
S.stacksize = MAXSIZE; //stacksize置为栈的最大容量MAXSIZE
return OK;
}
- 判断顺序栈是否为空栈
tatus StackEmpty(SqStack S){
// 若栈为空,返回TRUE;否则返回FALSE
if(S.top == S.base)
return TRUE;
else
return FALSE;
}
- 顺序栈的长度
// 顺序栈长度
int StackLength(SqStack S){
return S.top - S.base;
}
- 清空顺序栈
//清空顺序栈
Status ClearStack(SqStack S){
if(S.base) S.top = S.base;
return OK;
}
- 清空顺序栈
//销毁顺序栈
Status DestroyStack(SqStack &S){
if(S.base){
delete S.base;
S.stacksize = 0;
S.base = S.top = NULL;
}
return 0;
}
顺序栈的入栈
- 入栈操作是指在栈顶插入一个新的元素。
1.判断是否栈满,若满则出错(上溢)
2.元素e压入栈顶
3.栈顶指针加1
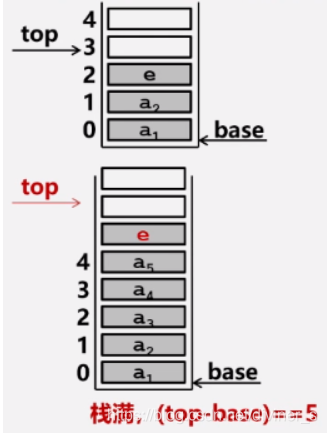
//顺序栈的入栈
Status Push(SqStack &S,SElemType e){
if(S.top - S.base == S.stacksize) //栈满
return ERROR;
*S.top++=e; //*S.top = e; S.top++;
return OK;
}
顺序栈的出栈
- 出栈操作就是将栈顶元素删除
1.判断是否栈空,若满则出错(下溢)
2.获取栈顶元素e
3.栈顶指针减1

//顺序栈的出栈
Status Pop(SQStack &S,SElemType &e){
//若栈不空,则删除S的栈顶元素,用e返回其值,并返回OK;否则返回ERROR;
if(S.top == S.base)
return ERROR;
e = *--S.top; //--S.top; e = *S.top;
return OK;
}
取顺序栈的栈顶元素
SElemType GetTop(SqStack S){//返回S的栈顶元素,不修改指针
if(S.top!= S.base) //栈非空
return *(S.top-1); //返回栈顶元素的值,栈顶指针不变
}
链栈
链栈:即利用链表实现栈存储结构。通常链栈用单链表来表示。
链栈的表示和实现
链栈示意图:

将链表头部作为栈顶的一端,可以避免在实现数据 “入栈” 和 “出栈” 操作时做大量遍历链表的耗时操作。
链表的头部作为栈顶,意味着:
- 在实现数据"入栈"操作时,需要将数据从链表的头部插入;
- 在实现数据"出栈"操作时,需要删除链表头部的首元节点;
因此,链栈实际上就是一个只能采用头插法插入或删除数据的链表。
链栈的定义
//-------链栈的存储结构------
typedef struct StackNode{
SElemType data;
struct StackNode *next;
}StackNode, *LinkStack;
注意链栈中指针的位置
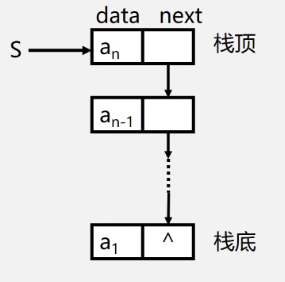
- 链表的头指针就是栈顶
- 不需要头结点
- 基本不存在栈满的情况
- 空栈相当于头指针指向空(NULL)
- 插入和删除仅在栈顶处执行
链栈的初始化
- 链栈的初始化操作就是创造一个空栈,因为没必要设头结点,所以直接将栈顶指针置空即可。
void InitStack(LinkStack &S){
//构造一个空栈,栈顶指针置为空
S = NULL;
return OK;
}
*判断链栈是否为空
//判断链栈是否为空
Status StackEmpty(LinkStack S){
if(S == NULL) return TRUE;
else return FALSE;
}
链栈的入栈
- 和顺序栈的入栈不同的是,链栈在入栈之前不需要判断栈是否满,只需要为入栈元素动态分配一个结点空间,如图:
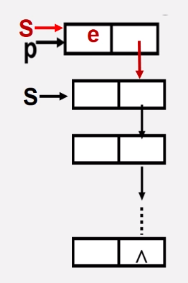
1.为入栈元素e分配空间,用指针p指向
2.将新结点数据域置为e
3.将新结点插入栈顶
4.修改栈顶指针为p
//链栈的入栈
Status Push(LinkStack &S,SElemType e){
p = new StackNode;//生成新结点p
p->data = e; //将新结点数据据置为e
p->next = S; //将新结点插入栈顶
S = p; //修改栈顶指针
return OK;
}
链栈的出栈
- 链栈在出栈后需要释放出栈元素的栈顶空间,如图:
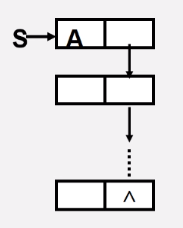
1.判断栈是否为空栈吗,若空则返回ERROR
2.将栈顶元素赋给e
3.临时保存栈顶元素的空间,以备释放
4.修改栈顶指针,指向新的栈顶元素
5.释放原栈顶元素的空间
//链栈的出栈
Status Pop(LinkStack &S, SElemType &e){
if(S == NULL) return ERROR; //栈空
e = S->data; //将栈顶元素赋给e
p = S; //用p临时保存栈顶元素空间,以备释放
S = S ->next; //修改栈顶指针
delete p; //释放原栈顶元素的空间
return OK;
}
取链栈的栈顶元素
- 与顺序栈一样,当栈非空时,此操作返回当前栈顶元素的值,栈顶指针S保持不变
//取链栈的栈顶元素
SElemType GetTop (SqSTack S)
{//返回S的栈顶元素,不修改栈顶指针
if(S!= NULL) //栈非空
return S->data; //返回栈顶元素的值,栈顶指针不变
}
声明:此博客只是作者为了熟悉知识点而写的笔记
借鉴:《数据结构》(C语言版)(第2版)严蔚敏
