常用操作
Redis是一个类似于hashMap的key-value键值对的内存数据库。
开启redis客户端:
1.redis-cli
2.auth 密码
Key操作‘
DEL 删除Key, del key1 key2
EXPIRE 设置或者更新到期时间,到期后自动清除,单位秒 设置为-1表示永不过期。 EXPIRE key -1
TYPE key 返回key的类型
Key* 返回所有的key
KEYS * pattern查找匹配给定模式pattern的所有key。
KEYS h?llo 匹配 hello , hallo 和 hxllo 等。
KEYS h*llo 匹配 hllo 和 heeeeello 等。
KEYS h[ae]llo 匹配 hello 和 hallo ,但不匹配 hillo 。
String 操作
SET 新增、修改
GET 获取
APPEND key value 追加到末尾。
List 操作
列表的特点就是可以头部(左边)或者尾部(右边)插入。入栈push 出栈pop
Lpush key value [value …]
将一个或多个值 value 插入到列表 key 的表头
如果 key 不存在,一个空列表会被创建并执行 LPUSH 操作。
当 key 存在但不是列表类型时,返回一个错误。
RPUSH key value [value …]
将一个或多个值 value 插入到列表 key 的表尾(最右边)。
如果 key 不存在,一个空列表会被创建并执行 RPUSH 操作。
LSET key index value 通过索引设置值
LPOP key 移除并返回列表 key 的头元素。
RPOP key 移除并返回列表 key 的尾元素。
Hash操作
HSET key field value
将哈希表 key 中的域 field 的值设为 value 。
如果 key 不存在,一个新的哈希表被创建并进行 HSET 操作。
如果域 field 已经存在于哈希表中,旧值将被覆盖。
HGET key field
返回哈希表 key 中给定域 field 的值。
Set操作
Redis 的 Set 是 String 类型的无序集合。集合成员是唯一的,这就意味着集合中不能出现重复的数据。
SADD key member [member …]
将一个或多个 member 元素加入到集合 key 当中,已经存在于集合的 member 元素将被忽略。
假如 key 不存在,则创建一个只包含 member 元素作成员的集合。
SREM key member [member …]
移除集合 key 中的一个或多个 member 元素,不存在的 member 元素会被忽略。
当 key 不是集合类型,返回一个错误。
Zset操作
Redis 有序集合和集合一样也是string类型元素的集合,且不允许重复的成员。
不同的是每个元素都会关联一个double类型的分数。redis正是通过分数来为集合中的成员进行从小到大的排序。
有序集合的成员是唯一的,但分数(score)却可以重复。
ZADD key score member [[score member] [score member] …]
将一个或多个 member 元素及其 score 值加入到有序集 key 当中。
如果某个 member 已经是有序集的成员,那么更新这个 member 的 score 值,并通过重新插入这个 member 元素,来保证该 member 在正确的位置上。
score 值可以是整数值或双精度浮点数。
如果 key 不存在,则创建一个空的有序集并执行 ZADD 操作。
当 key 存在但不是有序集类型时,返回一个错误。
ZREM key member [member …]
移除有序集 key 中的一个或多个成员,不存在的成员将被忽略。
当 key 存在但不是有序集类型时,返回一个错误。
详细可以菜鸟教程
redis 持久化
Redis支持的两种数据持久化方式:RDB(redis database) 和 AOF(仅追加文件)方式。RDB会根据配置的规则定时的将内存的数据持久化到磁盘上,而AOF则是每次执行完命令在redis的操作日志中以追加的方式写入文件。
RDB持久化
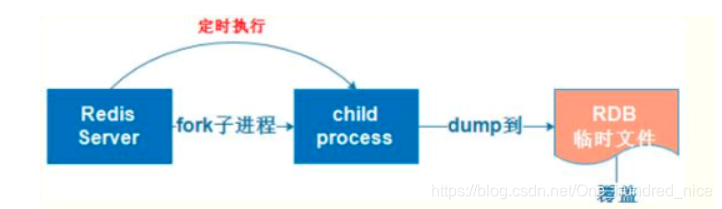
原理:将Redis在内存的数据库记录定时Dump到磁盘上的RDB持久化
意思是在指定的时间内将缓存中的数据集快照写入磁盘,实际过程是一个fork子进程,先将数据集写入临时文件,写入成功后,在覆盖之前的文件,并用二进制压缩存储。
AOP持久化
原理:将Redis的操作日志以追加的方式写入文件中,操作日志只记录了增删操作,没有查询操作

缓存的目的是为了提高系统的性能,缓存中的数据主要有两种:
1.热点数据,我们要把经常访问并且修改频率低的数据放在缓存中,降低数据库IO,同时缓存是把数据放在内存中,查询的速度非常的快,可以加快整个系统的响应速度,也在一定程度上提交系统的并发量;
2.查询非常耗时且实时性较低的数据,如果有一些查询时非常耗时,每次请求都要去查询多张表,会使得系统响应速度特别慢,把这些数据放在缓存中可以极大的提高系统的响应速度;
情景可以如下
1、app端看统计数据,在打开app时加载看板数据,汇总来自于不同的库,各个数据的生成的数据可以放在缓存中,这样可以极大的提高我们查询数据的效率
2、访问频繁、实时性要求不高,但sql查询或io比较耗时的数据,如Session(因为每次请求都携带)
3、一些需要超时失效的数据,比如验证码、Session、Token
4、需要缓冲的数据,比如入列前的订单 ID、队列处理完之后从缓存里取会很方便;(简易队列)
5、分布式存储,有着不同的服务器,查询数据时通过redis的key查询
6、发布/订阅 pub/sub 是 Redis 内置的一个非常强大的特性,例如微博的评论和点赞,访问非常频繁,实时性和准时性要求不高
