Spark任务调度策略
FIFO
FIFO(先进先出)方式调度Job,每个Job被切分成多个Stage。第一个Job优先获取所有可用资源,接下来第二个Job再获取剩余可用资源。(每个Stage对应一个TaskSetManager)
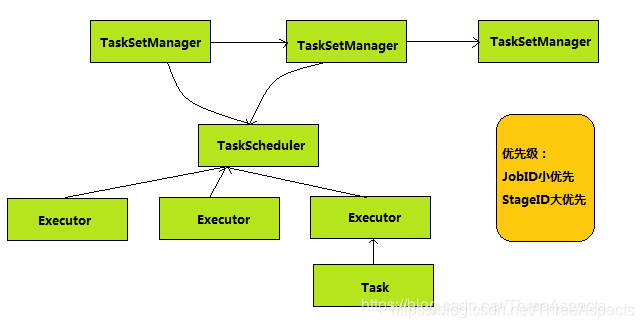
优先级(Priority): 在DAGscheduler创建TaskSet时使用JobId作为优先级的值。FIFO调度算法实现如下所示
private[spark] class FIFOSchedulingAlgorithm extends SchedulingAlgorithm {
override def comparator(s1: Schedulable, s2: Schedulable): Boolean = {
val priority1 = s1.priority
val priority2 = s2.priority
var res = math.signum(priority1 - priority2)
if (res == 0) {
val stageId1 = s1.stageId
val stageId2 = s2.stageId
res = math.signum(stageId1 - stageId2)
}
if (res < 0) {
true
} else {
false
}
}
}
由源码可知,FIFO依据JobId进行挑选较小值。因为越早提交的作业,JobId越小。
对同一个作业(Job)而言,越早生成的Stage,其StageId越小。有依赖关系的多个Stage之间,DAGScheduler会控制Stage是否会被提交到调度队列中(若其依赖的Stage未执行完前,此Stage不会被提交),其调度顺序可通过此来保证。但若某Job中有两个无入度的Stage的话,则先调度StageId小的Stage
FAIR
FAIR共享模式调度下,Spark以在多Job之间轮询方式为任务分配资源,所有的任务拥有大致相当的优先级来共享集群的资源。FAIR调度模型如下图:
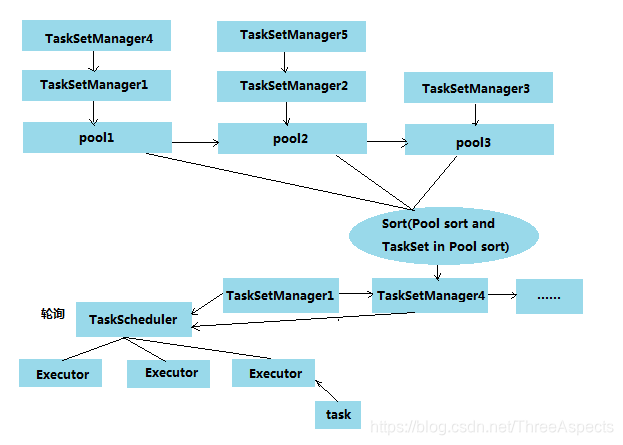
Fair调度队列可存在多个调度队列,且队列呈树型结构,用户使用sc.setLocalProperty(“spark.scheduler.pool”, “poolName”)来指定要加入的队列,默认情况下会加入到buildDefaultPool。每个队列中还可指定自己内部的调度策略,且Fair还存在一些特殊的属性:
- schedulingMode: 设置调度池的调度模式FIFO或FAIR, 默认为FIFO
- minShare:最少资源保证量,当一个队列最少资源未满足时,它将优先于其它同级队列获取资源
- weight: 在一个队列内部分配资源时,默认情况下,采用公平轮询的方法将资源分配给各个应用程序,而该参数则将打破这种平衡。例如,如果用户配置一个指定调度池权重为2, 那么这个调度池将会获得相对于权重为1的调度池2倍的资源
以上参数,可通过conf/fairscheduler.xml文件配置调度池的属性。Fair调度算法实现:
private[spark] class FairSchedulingAlgorithm extends SchedulingAlgorithm {
override def comparator(s1: Schedulable, s2: Schedulable): Boolean = {
val minShare1 = s1.minShare
val minShare2 = s2.minShare
val runningTasks1 = s1.runningTasks
val runningTasks2 = s2.runningTasks
val s1Needy = runningTasks1 < minShare1
val s2Needy = runningTasks2 < minShare2
val minShareRatio1 = runningTasks1.toDouble / math.max(minShare1, 1.0).toDouble
val minShareRatio2 = runningTasks2.toDouble / math.max(minShare2, 1.0).toDouble
val taskToWeightRatio1 = runningTasks1.toDouble / s1.weight.toDouble
val taskToWeightRatio2 = runningTasks2.toDouble / s2.weight.toDouble
var compare: Int = 0
if (s1Needy && !s2Needy) {
return true
} else if (!s1Needy && s2Needy) {
return false
} else if (s1Needy && s2Needy) {
compare = minShareRatio1.compareTo(minShareRatio2)
} else {
compare = taskToWeightRatio1.compareTo(taskToWeightRatio2)
}
if (compare < 0) {
true
} else if (compare > 0) {
false
} else {
s1.name < s2.name
}
}
}
由原码可知,未满足minShare规定份额的资源的队列或任务集先执行;如果所有均不满足minShare的话,则选择缺失比率小的先调度;如果均不满足,则按执行权重比进行选择,先调度执行权重比小的。如果执行权重也相同的话则会选择StageId小的进行调度(name=“TaskSet_”+ taskSet.stageId.toString)。以此为标准将所有TaskSet进行排序, 然后选出优先级最高的进行调度。
———————————————————————————————————————
默认情况下,Spark的调度程序以FIFO方式运行作业。每个job会被划分成很多stage,在第一个job运行完成之后,第二个job才会去执行。如果在队列头部的job不需要使用集群的全部资源,那么后面的job可以立即执行。队列头部的job很大的话,其余的job必须推迟执行。
从Spark 0.8开始,也可以在作业之间配置公平的共享。在公平分享下,Spark以“循环”方式在任务之间分配tasks,使所有job获得大致相等的集群资源份额。这意味着长job运行期间提交的短job,也可以立即获取到资源,并且仍然可以获得良好的响应时间,而无需等待长job完成。此模式最适合多用户。要启用公平调度程序,只需在配置SparkContext时:
val conf = new SparkConf().setMaster(...).setAppName(...)
conf.set("spark.scheduler.mode", "FAIR")
val sc = new SparkContext(conf)
