YOLOv3调试心得
1、需要将图像进行归一化操作,即"/255",将数值从0~255转换到0~1
2、OpenCV和PIL读取的图像shape为 h,w,c,需要将其转换为c,w,h;并且,当模型存在batch时,还需要在前面加上一维B,从而形成(b,c,w,h)的格式。
3、OpenCV读取的图像颜色通道为(BGR),最好将其转换为RGB在投入模型(虽然有时候影响不是很大,但最好还是转换一下)。
4、YOLOV3、tiny-YOLOV3在精度方面,前者优于后者;但在速率方面,听说后者更快,但在我的电脑并没有体现出来。
一、制作自己的数据集(VOC数据集方式)
1、新建文件夹:
-VOCdevkit
--VOC2018
—Annotations
—ImageSets
----Layout
----Main
—JPEGImages
—labels
—test.py
--2018_train.txt
--2018_val.txt
--vol_label.py
下面分析一下各个文件夹和文件的作用:
-VOCdevkit
--VOC2018 存放此年份的数据集信息
—Annotations 存放xml文件
—ImageSets
----Layout 未使用
----Main 存放分类后的train/val/test数据集的每个数据图像的名称(运行test.py后自动生成)
—JPEGImages 真正用来存放数据图像的文件夹
—labels 存放用于YOLOv3识别的标签(运行test.py后自动生成,每行为带后缀的图像名称;包含train/val/test中所有数据图像的label)
—test.py 用于将xml转换为YOLOv3识别的txt文件
--2018_train.txt 存放train数据集中的数据的路径信息
--2018_val.txt 存放val数据集中的数据的路径信息
--vol_label.py 用于生成2018_train/val.txt文件
2、关于辅助工具和几个.py的使用
1、标签labels生成工具: 精灵标注助手
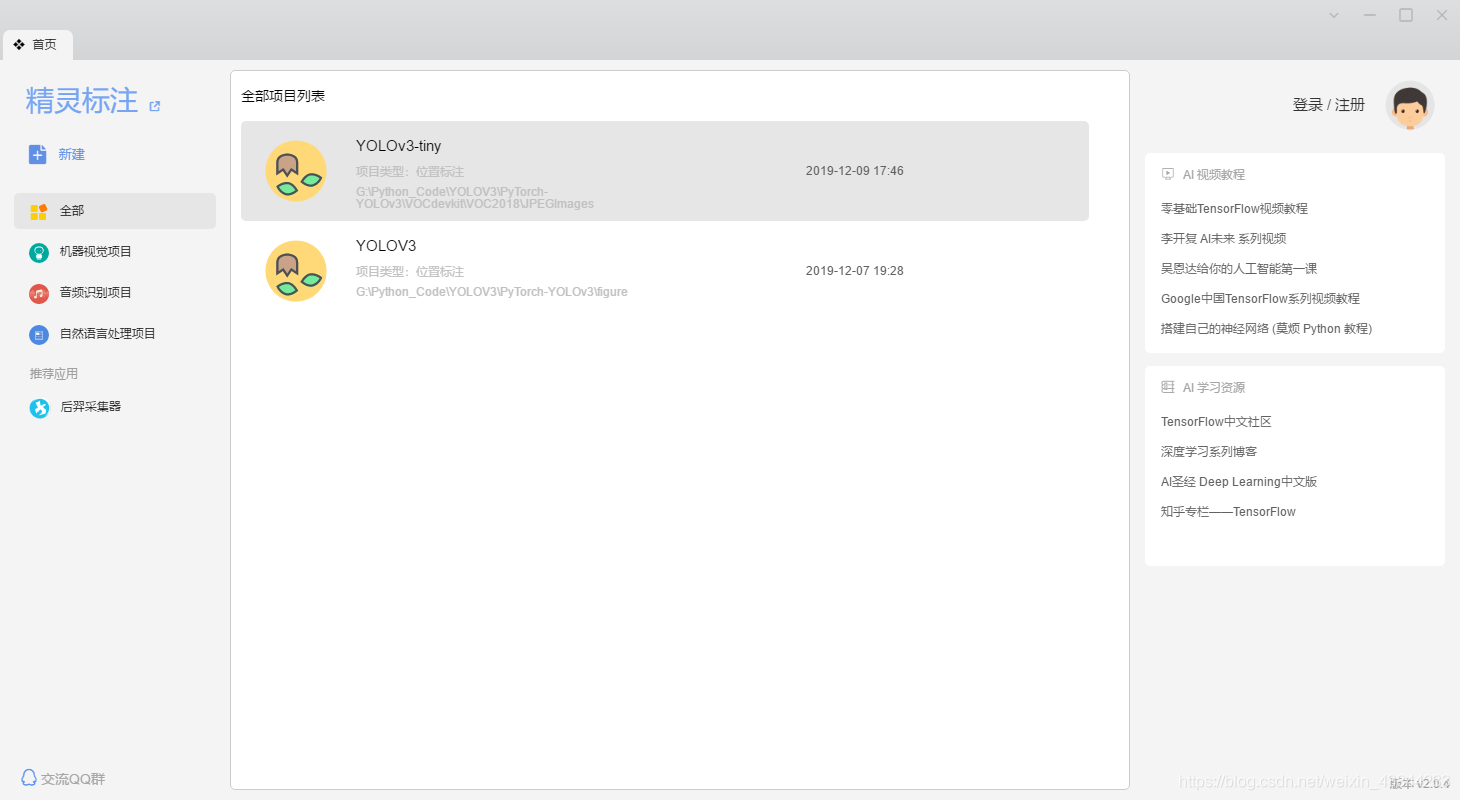
1)安装后的样子如下,中间是我建立的两个项目。
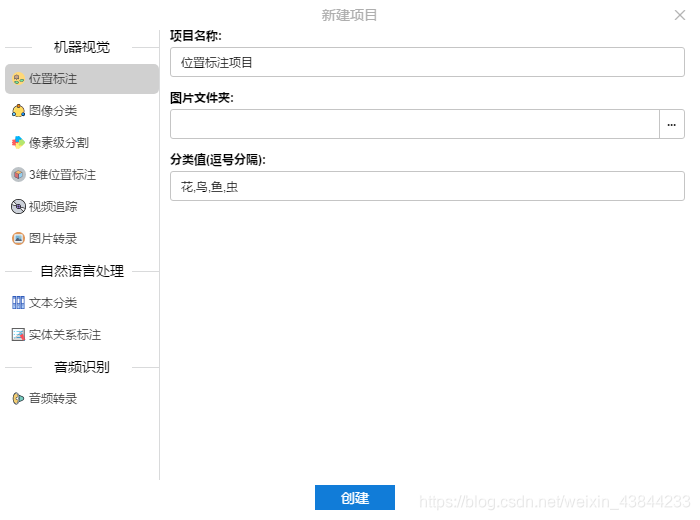
2)点击“新建”,根据的自己的需求选择左侧不同的功能、文件夹路径、分类值;然后点击“创建”
3)进入项目后,就可进行位置标注,可以选择“矩形框、曲线框、多边形框”;
每张图像位置标注后,点击下方的“对勾”和选定后侧的分类信息后才视为本图像的标注完成;

4)当所有图像标注完成后,点击上图左侧“导出”,即可跳出下图选项,选择默认选项即可生成与图像名字对应的xml文件。
注:即使没标注的图像,也会生成相应的xml文件,可通过后续的.py文件去掉这些无效的xml文件。

2、test.py
用途:分别选取train/val/test数据集的图像;
生成文件:train.txt/val.txt/test.txt。
根据上面生成的xml文件,将它们对应的图像名字写入train.txt/val.txt/test.txt文件中,所以txt文件中存在是图像名称(无后缀名,每个名字独占一行),如“photo_0001”。
import os
import random
trainval_percent = 0.15 # 设置验证集的比例
train_percent = 0.85
xmlfilepath = 'Annotations'
txtsavepath = 'ImageSets\Main'
total_xml = os.listdir(xmlfilepath)
num = len(total_xml)
list = range(num)
tv = int(num * trainval_percent)
tr = int(tv * train_percent)
val = random.sample(list, tv) # 随机选择验证集的图像
train = random.sample(val, tr)
ftest = open('ImageSets/Main/test.txt', 'w')
ftrain = open('ImageSets/Main/train.txt', 'w')
fval = open('ImageSets/Main/val.txt', 'w')
for i in list:
name = total_xml[i][:-4] + '\n'
if i in val:
fval.write(name) # 设置验证集,将选为验证集的图像名称写入valid.txt中
# if i in train:
# ftest.write(name)
# else:
# fval.write(name)
else:
ftrain.write(name) # 设置训练集
ftrain.close()
fval.close()
ftest.close()
3、voc_label.py
用途:将xml文件中的label转换为YOLO能够识别的label,并将分类完成的数据集的路径写入对应txt文件中
生成文件:文件夹labels、2018_train.txt、2018_val.txt
通过程序中的 try…except…来剔除掉为进行标记的数据
import xml.etree.ElementTree as ET
import pickle
import os
from os import listdir, getcwd
from os.path import join
sets = [('2018', 'train'), ('2018', 'val')] # 根据建立文件夹的名字,和所需要处理的数据集更改
# classes = ["aeroplane", "bicycle", "bird", "boat", "bottle"]
classes = ["tube"] # (改!)自己要测的目标类别
def convert(size, box):
dw = 1. / (size[0])
dh = 1. / (size[1])
x = (box[0] + box[1]) / 2.0 - 1
y = (box[2] + box[3]) / 2.0 - 1
w = box[1] - box[0]
h = box[3] - box[2]
x = x * dw
w = w * dw
y = y * dh
h = h * dh
return (x, y, w, h)
def convert_annotation(year, image_id):
in_file = open('VOC%s/Annotations/%s.xml' % (year, image_id)) # (改!)自己的图像标签xml文件的路径
tree = ET.parse(in_file) # 直接解析xml文件
root = tree.getroot() # 获取xml文件的根节点
try: # 尝试读取xml中的标签信息
size = root.find('size') # 获取指定节点“图像尺寸”
w = int(size.find('width').text) # 获取图像宽
h = int(size.find('height').text) # 获取图像高
except: # 如果查找不到,则return False
return False
print(image_id)
out_file = open('VOC%s/labels/%s.txt' % (year, image_id), 'w') # (改!)自己的图像标签txt文件要保存的路径
for obj in root.iter('object'):
difficult = obj.find('difficult').text # xml里的difficult参数
cls = obj.find('name').text # 要检测的类别名称name
if cls not in classes or int(difficult) == 1 or cls is None:
continue
cls_id = classes.index(cls)
xmlbox = obj.find('bndbox')
b = (float(xmlbox.find('xmin').text), float(xmlbox.find('xmax').text), float(xmlbox.find('ymin').text),
float(xmlbox.find('ymax').text))
bb = convert((w, h), b)
out_file.write(str(cls_id) + " " + " ".join([str(a) for a in bb]) + '\n')
return True
# 获取当前文件的路径
wd = getcwd()
print(wd)
for year, image_set in sets:
# 用于检查是否存在保存目标文件的文件夹,没有则新建此文件夹
if not os.path.exists('./VOC%s/labels/' % (year)):
os.makedirs('./VOC%s/labels/' % (year))
# 用VOC数据集的话,是将VOCdevkit/VOC2007/ImageSets/Main/文件夹下的所有txt都循环读入了
# 这里我只读入所有待训练图像的路径train.txt
image_ids = open('./VOC%s/ImageSets/Main/%s.txt' % (year, image_set)).read().strip().split()
# 保存数据集的绝对路径至一个txt文件中
list_file = open('%s_%s.txt' % (year, image_set), 'w')
for image_id in image_ids:
res = convert_annotation(year, image_id)
if res: # 只有xml文件中存在正确的label时,才将该数据路径写入相应的txt中
list_file.write('VOCdevkit/VOC%s/JPEGImages/%s.jpg\n' % (year, image_id))
# image_id = os.path.split(image_id)[1] # image_id内容类似'0001.jpg'
# image_id2 = os.path.splitext(image_id)[0] # image_id2内容类似'0001'
list_file.close()
4、至此,数据集以处理完毕,下面就是投入到model中进行训练
踩到的坑:
1、加载(而非制作)数据集的时候,使用Dataloader函数一直报错:
原因:在读取label时,读取的文件不存在。
解决:
# datasets.py-65行
# path.replace("images", "labels").replace(".png", ".txt").replace(".jpg", ".txt") #改为下面的内容
path.replace("JPEGImages", "labels").replace(".png", ".txt").replace(".jpg", ".txt")
因为原工程中图像存在于“image”,标签存在于“labels”;而自己制作的数据使用VOC的方式,图像数据在“JPEGImages”文件夹中,label存储在“labels”文件夹中。
2、训练集中的每一张图像都必须存在标注(即图像中至少存在一类对象)
解决:已通过上述的py文件剔除为进行任何标记的数据。
