在Python中,函数是一等对象:
- 在运行时创建
- 能赋值给变量或数据结构中的元素
- 能作为参数传给函数
- 能作为函数的返回结果
把函数视作对象
>>> def factorial(n): #通过控制台会话运行时创建一个函数
... '''returns n!'''
... return 1 if n < 2 else n * factorial(n-1)
...
>>> factorial(42)
1405006117752879898543142606244511569936384000000000
>>> factorial.__doc__
'returns n!'
>>> type(factorial)
<class 'function'> #是function类的实例
我们来看下赋值、调用:
>>> fact = factorial
>>> fact
<function factorial at 0x7f1c69958e18>
>>> fact(5)
120
>>> map(factorial,range(11))
<map object at 0x7f1c62361908>
>>> list(map(fact,range(11)))
[1, 1, 2, 6, 24, 120, 720, 5040, 40320, 362880, 3628800]
有了一等函数,就可以使用函数式风格编程。
高阶函数
接受函数为参数,或者把函数作为结果返回的函数是高阶函数。map函数就是的,另外sorted()函数也是:可选的key参数可用于提供一个函数,应用到各个元素上进行排序。
根据单词长度给一个列表排序:
>>> fruits = ['strawberry', 'fig', 'apple', 'cherry', 'raspberry', 'banana']
>>> sorted(fruits,key=len)
['fig', 'apple', 'cherry', 'banana', 'raspberry', 'strawberry']
根据反向拼写给一个单词列表排序:
>>> def reverse(word):
... return word[::-1]
...
>>> reverse('testing')
'gnitset'
>>> sorted(fruits,key=reverse)
['banana', 'apple', 'fig', 'raspberry', 'strawberry', 'cherry']
banana的反向拼写是a开头,因此是第一个元素。
map、filter和reduce的替代品
函数式语言通常会提供map、filter和reduce三个高阶函数。
列表推导和生成器表达式具有map和filter两个函数的功能,而且更易于阅读。
计算阶乘列表:map和filter与列表推导比较
>>> list(map(fact,range(6))) #0!到5!的一个阶乘列表
[1, 1, 2, 6, 24, 120]
>>> [fact(n) for n in range(6)] #使用列表推导执行相同的操作
[1, 1, 2, 6, 24, 120]
>>> list(map(factorial, filter(lambda n: n % 2,range(6))))
[1, 6, 120]#奇数阶乘列表(1!,3!,5!)
>>> [factorial(n) for n in range(6) if n %2] #使用列表推导替代map和filter,同时避免了使用lambda表达式
[1, 6, 120]
reduce在Python3中是在functools模块,常用于求和,但最好使用内置的sum函数:
>>> from functools import reduce
>>> from operator import add
>>> reduce(add,range(100))
4950
>>> sum(range(100))
4950
为了使用高阶函数,有时创建一次性的小型函数更便利。这便是匿名函数存在的原因。
匿名函数
lambda关键字在Python表达式内创建匿名函数。
Python限制了lambda函数的定义体内只能使用纯表达式,不能赋值,不能使用while和try等。
>>> fruits = ['strawberry', 'fig', 'apple', 'cherry', 'raspberry', 'banana']
>>> sorted(fruits, key = lambda word: word[::-1])
['banana', 'apple', 'fig', 'raspberry', 'strawberry', 'cherry']
可调用对象
除了用户定义的函数,调用运算符(即())还可以应用到其他对象上。
可通过callable()函数来判断对象是否能调用。
>>> abs, str, 13
(<built-in function abs>, <class 'str'>, 13)
>>> [callable(obj) for obj in (abs, str, 13)]
[True, True, False]
用户定义的可调用类型
只要实现实例方法__call__,任何 Python 对象都可以表现得像函数。
比如调用BingoCage实例,从打乱的列表中取出一个元素:
# -*- coding: utf-8 -*
import random
class BingoCage:
def __init__(self,items):
self._items = list(items) #接受任何可迭代对象,本地构建一个副本
random.shuffle(self._items) #打乱
def pick(self):
try:
return self._items.pop()
except IndexError: #为空抛出异常
raise LookupError('pick from empty BingoCage')
def __call__(self):
return self.pick()
if __name__ == '__main__':
bingo = BingoCage(range(3))
print (bingo.pick()) #1
print(bingo()) #打印2 可以像函数一样调用
print(callable(bingo))#True
下面讨论把函数视作对象处理的另一方面:运行时内省。
函数内省
除了 __doc__,函数对象还有很多属性。使用 dir 函数可以探知
factorial 具有下述属性:
>>> dir(factorial)
['__annotations__', '__call__', '__class__', '__closure__', '__code__',
'__defaults__', '__delattr__', '__dict__', '__dir__', '__doc__', '__eq__',
'__format__', '__ge__', '__get__', '__getattribute__', '__globals__',
'__gt__', '__hash__', '__init__', '__kwdefaults__', '__le__', '__lt__',
'__module__', '__name__', '__ne__', '__new__', '__qualname__', '__reduce__',
'__reduce_ex__', '__repr__', '__setattr__', '__sizeof__', '__str__',
'__subclasshook__']
其中大多数属性是 Python 对象共有的。本节讨论与把函数视作对象相关
的几个属性,先从 __dict__ 开始。
与用户定义的常规类一样,函数使用 __dict__ 属性存储赋予它的用
户属性。这相当于一种基本形式的注解。
下面重点说明函数专有而用户定义的一般对象没有的属性。计算两个属性集合的差集便能得到函数专有属性列表:
>>> class C: pass
>>> obj = C()
>>> def func(): pass
>>> sorted(set(dir(func)) - set(dir(obj)))
['__annotations__', '__call__', '__closure__', '__code__', '__defaults__', '__get__', '__globals__', '__kwdefaults__', '__name__', '__qualname__']
| 名称 | 类型 | 说明 |
|---|---|---|
__annotations__ |
dict | 参数和返回值的注解 |
__call__ |
methodwrapper | 实现()运算符;可调用对象协议 |
__closure__ |
tuple | 函数闭包,即自由变量的绑定 |
__code__ |
code | 编译成字节码的函数元数据和函数定义体 |
__defaults__ |
tuple | 形式参数的默认值 |
__get__ |
methodwrapper | 实现只读描述符协议 |
__globals__ |
dict | 函数所在模块中的全局变量 |
__kwdefaults__ |
dict | 仅限关键字形式参数的默认值 |
__name__ |
str | 函数名称 |
__qualname__ |
str | 函数的限定名称,如Random.choice |
从定位参数到仅限关键字参数
Python 最好的特性之一是提供了极为灵活的参数处理机制,而且 Python
3 进一步提供了仅限关键字参数(keyword-only argument)。与之密切相
关的是,调用函数时使用 * 和 **“展开”可迭代对象,映射到单个参
数。
def tag(name,*content,cls = None,**attrs):
""" 生成一个或多个HTML标签
:param name: 定位参数(位置参数)
:param content: 可变参数(允许传入任意(或0)个参数,通过tuple存储)
:param cls: 命名关键字参数,命名关键字参数需要一个*(或者是可变参数)作为分隔符,该分隔符后面的就是命名关键字参数,
必须传入参数名
:param attrs: 关键字参数,允许传入任意(或0)个含参数名的参数,通过dict存储
:return:
"""
if cls is not None:
attrs['class'] = cls
if attrs:
attr_str = ''.join(' %s="%s"' % (attr, value) for attr, value in sorted(attrs.items()))
else:
attr_str = ''
if content:
return '\n'.join('<%s%s>%s</%s>' %(name, attr_str, c, name) for c in content)
else:
return '<%s%s />' % (name, attr_str)
我们来对这些参数做一些解释:
name: 定位参数(位置参数)*content: 可变参数(允许传入任意(或0)个参数,通过tuple存储)cls: 仅限(命名)关键字参数,命名关键字参数需要一个*(或者是可变参数)作为分隔符,该分隔符后面的类似位置参数的就是命名关键字参数, 注意调用的时候必须传入参数名。attrs: 关键字参数,允许传入任意(或0)个含参数名的参数,通过dict存储
下面是调用例子:
>>> tag('br') # 传入单个参数到定位参数name,生成一个指定名称的空标签
'<br />'
>>> tag('p','hello') #第一个参数后的任意个参数会被*content捕获,存入元组
'<p>hello</p>'
>>> tag('p', 'hello', 'world') #第一个参数后的任意个参数会被*content捕获,存入元组
'<p>hello</p>\n<p>world</p>'
>>> tag('p', 'hello', id=33) #tag函数签名中没有指定名称的关键字会被**attrs捕获,存入字典(这里是id)
'<p id="33">hello</p>'
>>> tag('p', 'hello', 'world', cls='sidebar') #cls参数只能作为关键字参数传入,必须传入参数名,不然无法与位置参数进行区分
'<p class="sidebar">hello</p>\n<p class="sidebar">world</p>'
>>> tag(content='testing', name="img")
'<img content="testing" />'
>>> my_tag = {'name': 'img', 'title': 'Sunset Boulevard','src': 'sunset.jpg', 'cls': 'framed'}
>>> print(tag(**my_tag)) #my_tag 前面加上 **,字典中的所有元素作为单个参数传入,同名键会绑定到对应的具名参数上,余下的则被 **attrs 捕获。
<img class="framed" src="sunset.jpg" title="Sunset Boulevard" />
定义函数时若想指定仅限关键字参数,要把它们放到前面有 *的参数后面。如果不想支持数量不定的定位参数,但是想支持仅限关键字参数,在签名中
放一个 *,如下所示:
>>> def f(a, *, b):
... return a,b
...
>>> f(1,b=2)
(1, 2)
>>> f(1,2) #必须制定参数名b
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
TypeError: f() takes 1 positional argument but 2 were given
获取关于参数的信息
HTTP 微框架 Bobo 中有个使用函数内省的好例子。示例 是对 Bobo
教程中“Hello world”应用的改编,说明了内省怎么使用。
import bobo
@bobo.query('/')
def hello(person):
return 'Hello %s!' % person
Bobo 会内省 hello 函数,发现它需要一个名为
person 的参数,然后从请求中获取那个名称对应的参数,将其传给
hello 函数,因此程序员根本不用触碰请求对象。
通过以下命令启动程序:
>bobo -f bobo_demo.py
Serving ['bobo__main__'] on port 8080...
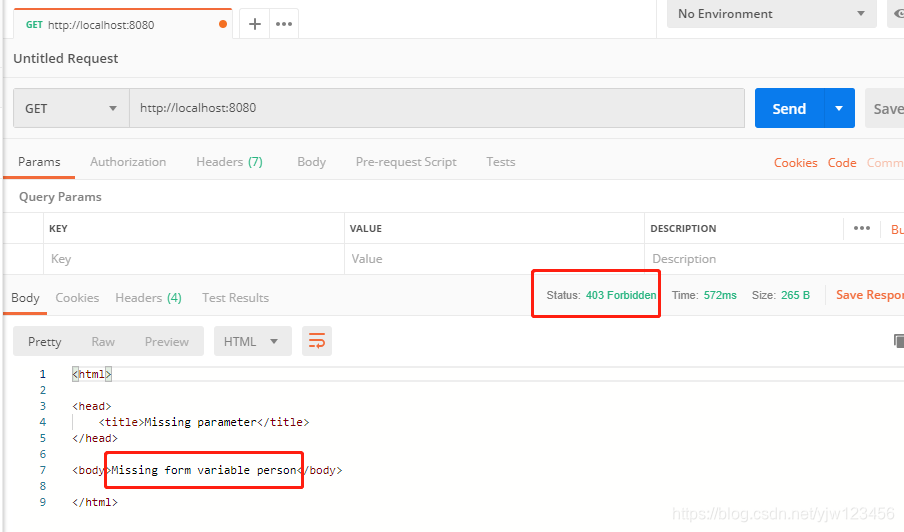
通过Postman访问 http://localhost:8080 可以看到状态码是403,并且有个消息提示缺少person变量。
我们加上person试一下:
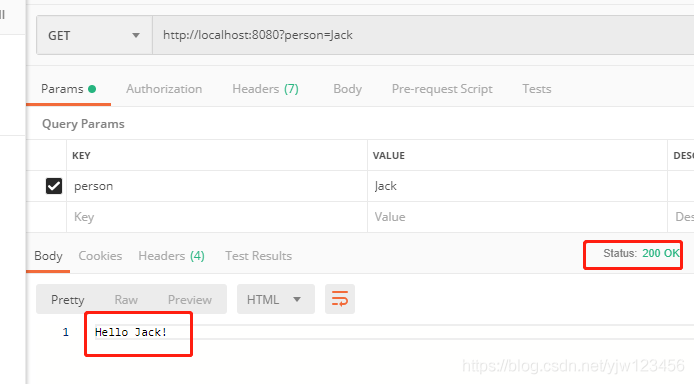
Bobo是怎么知道函数需要哪个参数的呢?它又怎么知道参数没有默认值呢?
函数对象有个__defaults__属性,它的值是一个元组,里面保存着
定位参数和关键字参数的默认值。仅限关键字参数的默认值在
__kwdefaults__属性中。然而,参数的名称在__code__ 属性中,
它的值是一个 code 对象引用,自身也有很多属性。
def clip(text, max_len=80):
"""在max_len前面或后面的第一个空格处截断文本"""
end = None
if len(text) > max_len:
space_before = text.rfind(' ', 0, max_len)
if space_before >= 0:
end = space_before
else:
space_after = text.rfind(' ', max_len)
if space_after >= 0:
end = space_after
if end is None:
end = len(text)
return text[:end].rstrip()
print(clip.__defaults__) #(80,)
print(clip.__code__) #<code object clip at 0x000001F1807759C0, file "D:/workspace/python/FluentPython/first_class_function/clip.py", line 3>
print(clip.__code__.co_varnames) #('text', 'max_len', 'end', 'space_before', 'space_after')
print(clip.__code__.co_argcount) #2
可以看出,这种组织信息的方式并不是最便利的。参数名称在
__code__.co_varnames 中,不过里面还有函数定义体中创建的局
部变量。因此,参数名称是前 N 个字符串,N 的值由
__code__.co_argcount确定。
幸好,我们有更好的方式——使用inspect模块
sig = signature(clip)
print(sig) #(text, max_len=80)
for name, param in sig.parameters.items():
print(param.kind, ':', name, '=', param.default)
#POSITIONAL_OR_KEYWORD : text = <class 'inspect._empty'>
#POSITIONAL_OR_KEYWORD : max_len = 80
inspect.Signature 对象有个 bind 方法,它可以把任意个参数绑
定到签名中的形参上,所用的规则与实参到形参的匹配方式一样。框架
可以使用这个方法在真正调用函数前验证参数,如示例所示。
>>> import inspect
>>> sig = inspect.signature(tag) #tag函数在上面定义过
>>> my_tag = {'name': 'img', 'title': 'Sunset Boulevard', 'src': 'sunset.jpg', 'cls': 'framed'}
>>> bound_args = sig.bind(**my_tag)
>>> bound_args #得到BoundArguments对象
<BoundArguments (name='img', cls='framed', attrs={'title': 'Sunset Boulevard', 'src': 'sunset.jpg'})>
>>> for name, value in bound_args.arguments.items(): #迭代bound_args.arguments
... print(name, '=', value)
...
name = img
cls = framed
attrs = {'title': 'Sunset Boulevard', 'src': 'sunset.jpg'}
>>> del my_tag['name'] #把必须指定的参数name从my_tag中删除
>>> bound_args = sig.bind(**my_tag) #调用报错
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
File "/usr/lib/python3.6/lib/python3.6/inspect.py", line 2933, in bind
return args[0]._bind(args[1:], kwargs)
File "/usr/lib/python3.6/lib/python3.6/inspect.py", line 2848, in _bind
raise TypeError(msg) from None
TypeError: missing a required argument: 'name'
框架和 IDE 等工具可以使用这些信息验证代码。Python 3 的另一个特性
——函数注解——增进了这些信息的用途
函数注解
Python 3 提供了一种句法,用于为函数声明中的参数和返回值附加元数据。
下面给定一个有注解的clip函数:
def clip(text:str, max_len:'int > 0'=80) -> str: #有注解的函数声明
"""在max_len前面或后面的第一个空格处截断文本"""
end = None
if len(text) > max_len:
space_before = text.rfind(' ', 0, max_len)
if space_before >= 0:
end = space_before
else:
space_after = text.rfind(' ', max_len)
if space_after >= 0:
end = space_after
if end is None:
end = len(text)
return text[:end].rstrip()
注解不会做任何处理,只是存储在函数的 __annotations__属性(一个字典)中:
print(clip.__annotations__)
{'text': <class 'str'>, 'max_len': 'int > 0', 'return': <class 'str'>}
Python 对注解所做的唯一的事情是,把它们存储在函数的
__annotations__属性里。仅此而已,Python 不做检查、不做强制、
不做验证,什么操作都不做。
在未来,Bobo 等框架可以支持注解,并进一步自动处理请求。例如,
使用 price:float 注解的参数可以自动把查询字符串转换成函数期待
的float 类型;quantity:'int > 0'这样的字符串注解可以转换
成对参数的验证。
支持函数式编程的包
operator模块
在函数式编程中,经常需要把算术运算符当作函数使用。例如,不使用
递归计算阶乘。求和可以使用 sum 函数,但是求积则没有这样的函
数。我们可以使用 reduce 函数,但是需要一个函数计算序列中两个
元素之积。示例展示如何使用 lambda 表达式解决这个问题。
>>> from functools import reduce
>>> def fact(n):
... return reduce(lambda a, b: a*b, range(1,n+1))
operator模块为多个算术运算符提供了对应的函数,从而避免编写
lambda a, b: a*b 这种平凡的匿名函数。
from functools import reduce
from operator import mul
def fact(n):
return reduce(mul, range(1, n+1))
operator 模块中还有一类函数,能替代从序列中取出元素或读取对象
属性的 lambda 表达式:因此,itemgetter 和 attrgetter 其实会
自行构建函数
>>> metro_data = [
... ('Tokyo', 'JP', 36.933, (35.689722, 139.691667)),
... ('Delhi NCR', 'IN', 21.935, (28.613889, 77.208889)),
... ('Mexico City', 'MX', 20.142, (19.433333, -99.133333)),
... ('New York-Newark', 'US', 20.104, (40.808611, -74.020386)),
... ('Sao Paulo', 'BR', 19.649, (-23.547778, -46.635833)),
... ]
>>>
>>>
>>> from operator import itemgetter
>>> for city in sorted(metro_data, key=itemgetter(1)): #
... print(city)
...
('Sao Paulo', 'BR', 19.649, (-23.547778, -46.635833))
('Delhi NCR', 'IN', 21.935, (28.613889, 77.208889))
('Tokyo', 'JP', 36.933, (35.689722, 139.691667))
('Mexico City', 'MX', 20.142, (19.433333, -99.133333))
('New York-Newark', 'US', 20.104, (40.808611, -74.020386))
其实,itemgetter(1)的作用与lambda fields: fields[1]一样:创建一个接受集合的函数,返回索引位 1上的元素。
如果把多个参数传给itemgetter,它构建的函数会返回提取的值构
成的元组:
>>> cc_name = itemgetter(1,0)
>>> for city in metro_data:
... print(cc_name(city))
...
('JP', 'Tokyo')
('IN', 'Delhi NCR')
('MX', 'Mexico City')
('US', 'New York-Newark')
('BR', 'Sao Paulo')
attrgetter 与 itemgetter 作用类似,它创建的函数根据名称提取
对象的属性。如果把多个属性名传给 attrgetter,它也会返回提取
的值构成的元组。此外,如果参数名中包含 .(点号),attrgetter
会深入嵌套对象,获取指定的属性。
>>> from collections import namedtuple
>>> LatLong = namedtuple('LatLong','lat long') #使用 namedtuple 定义 LatLong
>>> Metropolis = namedtuple('Metropolis', 'name cc pop coord')
>>> metro_areas = [Metropolis(name, cc, pop, LatLong(lat, long))
... for name,cc,pop,(lat,long) in metro_data]
>>> metro_areas[0]
Metropolis(name='Tokyo', cc='JP', pop=36.933, coord=LatLong(lat=35.689722, long=139.691667))
>>> metro_areas[0].coord.lat#获取它的纬度
35.689722
>>> from operator import attrgetter
>>> name_lat = attrgetter('name', 'coord.lat') #获取 name 属性和嵌套的 coord.lat 属性
>>> for city in sorted(metro_areas, key=attrgetter('coord.lat')):#使用attrgetter,按照纬度排序
... print(name_lat(city))
...
('Sao Paulo', -23.547778)
('Mexico City', 19.433333)
('Delhi NCR', 28.613889)
('Tokyo', 35.689722)
('New York-Newark', 40.808611)
使用 Metropolis 实例构建 metro_areas 列表;注意,我们使用
嵌套的元组拆包提取 (lat, long),然后使用它们构建 LatLong,
作为 Metropolis 的 coord 属性。
在 operator 模块余下的函数中,最后介绍一下
methodcaller。它的作用与 attrgetter 和 itemgetter 类似,它
会自行创建函数。methodcaller 创建的函数会在对象上调用参数指
定的方法:
>>> from operator import methodcaller
>>> s = 'The time has come'
>>> upcase = methodcaller('upper') #想调用str.upper方法
>>> upcase(s)
'THE TIME HAS COME'
>>> hiphenate = methodcaller('replace',' ', '-')
>>> hiphenate(s)
'The-time-has-come'
使用functools.partial冻结参数
functools.partial 这个高阶函数用于部分应用一个函数。部分应
用是指,基于一个函数创建一个新的可调用对象,把原函数的某些参数
固定。使用这个函数可以把接受一个或多个参数的函数改编成需要回调
的 API,这样参数更少。
>>> from operator import mul
>>> from functools import partial
>>> triple = partial(mul,3) #将参数3固定,这样只需要传一个参数
>>> triple(7)
21
>>> list(map(triple,range(1,10)))
[3, 6, 9, 12, 15, 18, 21, 24, 27]
使用 上篇介绍的unicode.normalize 函数再举个例子,这个示例
更有实际意义。如果处理多国语言编写的文本,在比较或排序之前可能
会想使用 unicode.normalize('NFC', s) 处理所有字符串 s。如
果经常这么做,可以定义一个 nfc 函数:
>>> import unicodedata,functools
>>> nfc = functools.partial(unicodedata.normalize,'NFC')
>>> s1 = 'café'
>>> s2 = 'cafe\u0301'
>>> s1,s2
('café', 'café')
>>> s1 == s2
False
>>> nfc(s1) == nfc(s2)
True
partial 的第一个参数是一个可调用对象,后面跟着任意个要绑定的
定位参数和关键字参数。这个功能其实很有用的。
