自如网杭州市租房数据分析
经过数据爬取和数据清洗后,终于到了数据分析的部分。具体从探索型数据分析和验证型数据分析两部分进行。探索型数据分析是主要为了了解属性的分布、属性之间的相关性,验证型数据分析则用来预测租金价格。
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
import seaborn as sns
%matplotlib inline
sns.set_style("darkgrid") #绘图风格
sns.set_context("talk")
plt.rcParams['font.sans-serif']=['SimHei']1.探索型数据分析
(1)首先看一下数值型属性的统计情况
rent_data=pd.read_csv('rent_data_clean.csv',encoding='gbk')
rent_data.describe()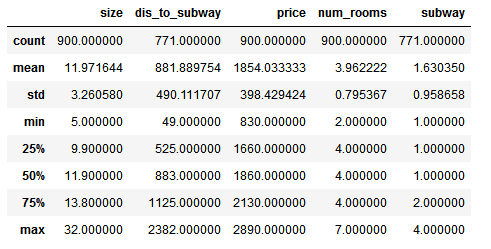
房间价格分布图
plt.hist(rent_data['price'],bins=20,edgecolor='w',color='lightskyblue')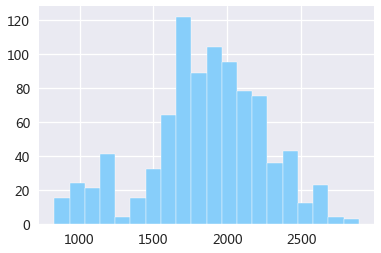
房间面积分布图
plt.hist(rent_data['size'],bins=27,edgecolor='w',color='orange')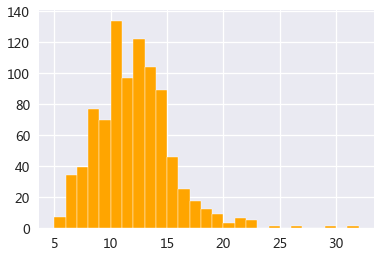
从数据的统计特征和分布直方图来看:
(1) 房源的租金均值为1854元/月,最便宜的是830元,最贵的是2890元,价格主要集中在1600-2300元。
因为这里的价格是合租的单个房间价格,相比杭州整个租房情况,可能价格有点偏高,不过加上清洁打扫等服务,价格应该说还比较合理。(2) 房间的面积大小平均在12平米,从最小的5平米到最大的32平米,主要集中在8-15平米,面积的差异还是挺大的。
最贵的房源和最便宜的房源分别位于哪里?
rent_data[rent_data['price']==rent_data['price'].max()]
rent_data[rent_data['price']==rent_data['price'].min()]
最贵的房间有两个,都达到了2890元/月,一个是位于西湖区文新站附近的新金都城市花园,该房间贵的原因应该是面积较大、周边配套设施齐全。另外一个是位于上城区城战附近的建国南苑,该房间贵的原因应该主要是位于交通枢纽附近,而且面积也挺大的。
最便宜的房间有三个,价格为830元/月,都位于余杭区,由于余杭区距离市区较远,交通、周围设施相对比较欠缺,所以租房价格相对便宜。
(2)再来看一下非数值型属性的分布情况
每个行政区的房源数量(这里下沙因为它高教园和面积较大的特点,作为一个单独的区域)
sns.countplot('district',data=rent_data,palette="Oranges")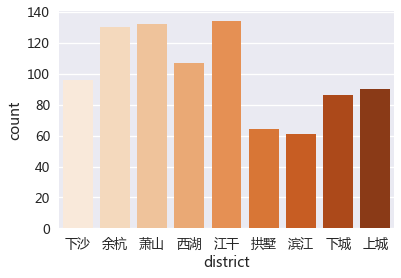
从公寓名称来看:‘龙湖旭辉春江悦茗’出租的房源最多,共54个。
从行政区划分来看:江干区出租的房源最多,共134个;另外,余杭区、萧山区的房源也较多,都超过了120。
从位置范围来看:近江范围内出租房源最多,共64个。
从地铁站点来看:江陵路站周围的房源最多,共65个。
各个行政区的房源价格箱线图
sns.boxplot('district','price',data=rent_data,palette="Set3")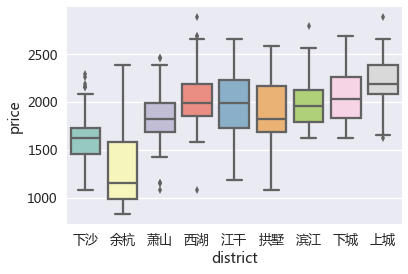
从各个行政区的价格箱线图来看:
上城区的租房价格最高,大致集中在2100-2400元之间,这与上城区商业发达,地处市区有关;
余杭区的租房价格最低,大致集中在1000-1600元之间;
下沙的租房价格也相对便宜,主要集中在1500-1750元之间,这是因为下沙是高教园区,学生比例大,租房价格不会太高。
因此在上城区工作的人可以考虑在价格相对较低的下城、滨江、江干区租房;而在江干、下城区工作的人可以考虑在下沙租房。
(3) 分析了单个属性的情况后,接下来看一下属性之间的关系。
不同地铁线上房屋面积与租金的散点图,三种颜色分别代表1号线、2号线、4号线
g=sns.FacetGrid(rent_data,hue='subway',palette={1:"red", 2:"orange",4:"green"},size=6,aspect=1.5).set(xlim=(0,25))
g.map(plt.scatter,'size','price',edgecolor='w',alpha=0.7).add_legend()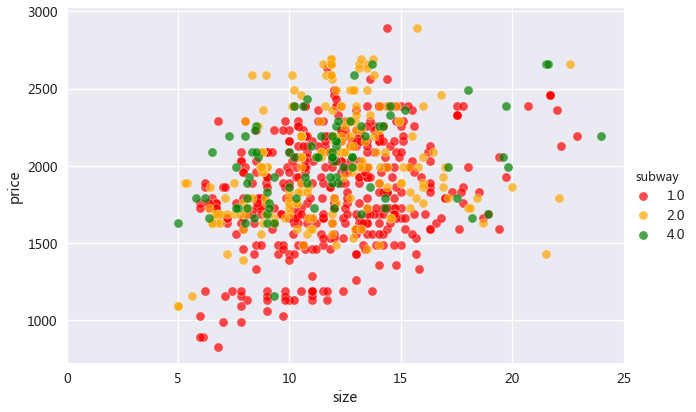
可以看到,面积与租金总体来说成正相关,随房间面积增大,租金也会上升,但相关性不是特别强,
这是因为影响房屋租金的因素有很多,比如交通、购物、娱乐设施等等。
各个行政区各条地铁线上,房间面积与房间价格的关系
g=sns.FacetGrid(rent_data,hue='subway',col='district',col_wrap=3,
palette={1:"red", 2:"orange",4:"green"}).set(xlim=(0,25))
g.map(plt.scatter,'size','price',edgecolor='w',alpha=0.7).add_legend()
plt.subplots_adjust(top=0.9)
g.fig.suptitle('各个行政区各条地铁线上,房间面积与房间价格的关系',fontsize=16)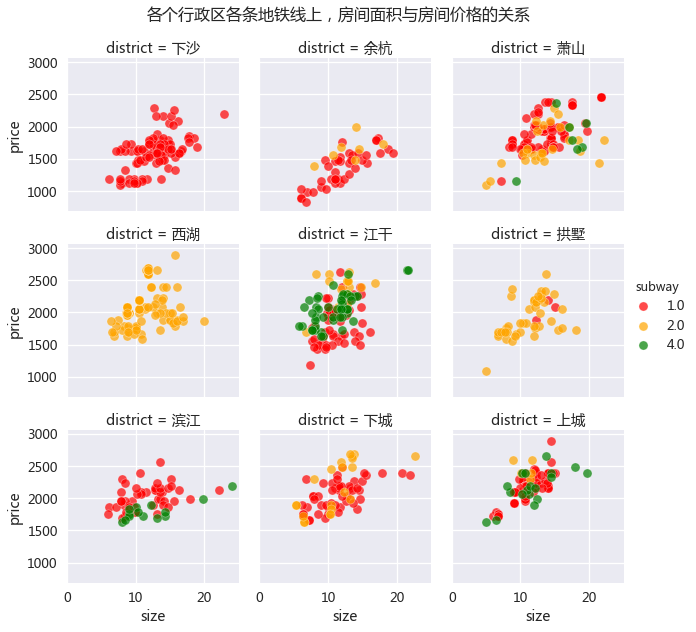
(1)从上面各个区域面积与房价的散点图来看,也可以看出上城区的租房价格最贵,基本都在2000元以上,而余杭区基本都在2000元以下。
(2)地铁线路密集的区域往往房租较高,例如三条地铁都覆盖的上城区和江干区,而萧山区虽然也有三条地铁,但4号线覆盖很少,因此相比前两个区域,价格要低一些由于杭州地铁还没有全部通车,有些区域目前只有1条地铁,随着地体的覆盖增加,租金可能会有所提升。
(3)而且可以发现,有些区域的租金与地铁线路有关,例如江干区,2号线附近租金最高,然后是4号线、1号线,滨江区也有类似的情况。
房间数与租金的关系图
sns.factorplot('num_rooms','price',data=rent_data,size=5,aspect=1.5)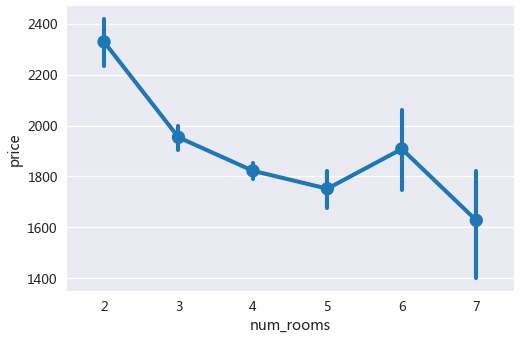
随公寓房间数的增多,租金呈下降趋势,但是房间数为6是一个特例,该数量不降反升,这主要是因为房间数为6的房源较少导致的,相对来说不具一般性,这些公寓可能由于人群定位、周边配套设施的关系租金较高。
到地铁站的距离与租金价格的关系图
rent_data['dis_to_subway']=rent_data['dis_to_subway'].fillna(3000) #补全缺失值
bins=[0,500,1000,1500,2000,2500,3000]
cut_class=['很近','近','一般近','一般远','远','很远'] #将租金划分为6档
rent_data['dis_cut']=pd.cut(rent_data['dis_to_subway'],bins=6,labels=cut_class)
sns.factorplot('dis_cut','price',data=rent_data,ci=68,size=5,aspect=1.5,color='g')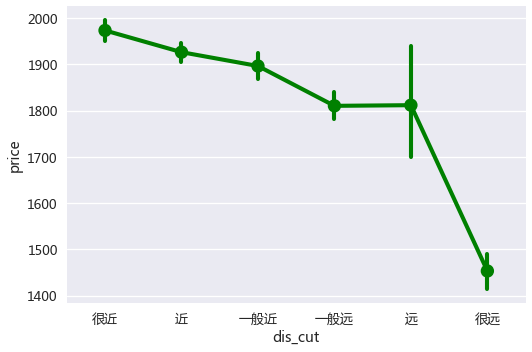
总体而言,随着到地铁站的距离越近,租金越高。
同样的,也因为影响租金高低的因素很多,所以图上‘一般远’和‘远’的价格均值反而近似相等,距离为‘远’的房源价格浮动很大。
通过对自如网杭州地区的租房情况分析,主要结论如下:
(1)租金均值为1854元/月,价格主要集中在1600-2300元;面积平均在12平米,主要集中在8-15平米。
(2)江干区出租的房源最多,共134个;另外,余杭区、萧山区的房源也较多,都超过了120。
(3)上城区的租房价格最高,集中在2100-2400元,这与上城区商业发达,地处市区有关;余杭区的租房价格最低,大致集中在1000-1600元;
下沙的租房价格也相对便宜,主要集中在1500-1750元,这是因为下沙是高教园区,学生比例大,租房价格不会太高。
因此在上城区工作的人可以考虑在价格相对较低的下城、滨江、江干区租房;在江干、下城区工作的人可以考虑在下沙租房。
(4)总体来说,随公寓房间数的增多,租金呈下降趋势;离地铁站的距离越近,租金越高。
2. 验证型数据分析
以上是对租金价格影响因素的探索型数据分析,接下来对租金做一个简单的预测。
预测前处理,对房间数和行政区重新编码,使得按租金高低有序。
room_codes={2:1,3:2,6:3,4:4,5:5,7:6}
def room_code(num):
for key in room_codes.keys():
if num==key:
return room_codes[key]
rent_data['room_code']=rent_data['num_rooms']
rent_data['room_code']=rent_data['room_code'].apply(room_code)district_rank=rent_data[['district','price']].groupby(['district']).mean().sort_values(by='price',ascending=False)
code_dict={}
i=1
for key in district_rank.index:
code_dict[key]=i
i=i+1
code_dict{'上城': 1, '下城': 2, '下沙': 8, '余杭': 9, '拱墅': 6, '江干': 4, '滨江': 5, '萧山': 7, '西湖': 3}
def district_code(district):
for value in district_rank.index:
if district==value:
return code_dict[value]
rent_data['district_code']=rent_data['district']
rent_data['district_code']=rent_data['district_code'].apply(district_code)rent_data.head()
线性回归系数
from sklearn.linear_model import LinearRegression
from sklearn import preprocessing
features=['size','dis_to_subway','district_code','room_code']
std_scale = preprocessing.StandardScaler()
rent_data[features]=std_scale.fit_transform(rent_data[features])
X=rent_data[features]
y=rent_data['price']
lm=LinearRegression()
lm.fit(X,y)
print(lm.intercept_)
print(lm.coef_)1854.03333333
[ 153.34600711 -82.81457497 -227.78316433 -28.91179471]
从各个特征的系数可以看出,行政区对租金价格的影响最大,房间数对价格的影响最小。
通过交叉验证来优化模型,提高模型的泛化性
from sklearn import cross_validation
from sklearn.model_selection import cross_val_predict
from sklearn import metrics
prediction = cross_val_predict(lm, X, y, cv=5)
print("MSE:",metrics.mean_absolute_error(y, prediction)) #平均绝对值误差MSE: 212.85073474
用随机森林进行回归预测
from sklearn.ensemble import RandomForestRegressor
rf=RandomForestRegressor(random_state=50)
prediction = cross_val_predict(rf, X, y, cv=5)
print("MSE:",metrics.mean_absolute_error(y, prediction)) MSE: 187.784730867
通过对租金进行预测,主要结论如下:
(1) 通过用线性回归和随机森林回归两种方法对租金价格进行预测,发现随机森林的效果更好,平均误差在188元,也就是说实际租金和预测租金平均相差188元。
(2) 根据房源面积、到地铁站的距离、行政区和房间数这些影响因素,可以大概知道房源的价格。可以给有租房需求的人提供一个很有用的帮助,他们可以知道目标房源的价格是偏高了,还是偏低了,从而做出有效的决定。
(3) 另外,由于实验中的样本数量(900)不多,影响因素也只有4个,所以预测结果不是特别接近,如果能获得更多的影响因素和样本,预测结果会更好。