杭州租房数据清洗
由于上篇文章中爬取下来的数据不能直接用来分析,比如一个属性包含多个信息、数值型属性包含单位等,因此首先要对数据做一定的清洗,处理成需要的格式 。
import pandas as pd
import numpy as np1.读取数据,初始属性解释
#因为文件中包含中文,为正确读取需要进行中文编码
rent_data=pd.read_csv('rent_data.csv',encoding='gbk')
rent_data.head()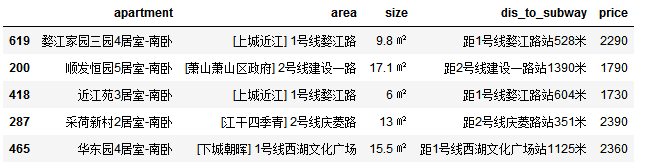
初始属性解释:
- apartment:公寓名称及房间数
- area:公寓所处地区,包括城区、街道或某个范围、靠近地铁几号线、最近的地铁站
- size:房间大小
- dis_to_subway:距离最近地铁站的距离
rent_data.info()输出:
<class 'pandas.core.frame.DataFrame'>
RangeIndex: 900 entries, 0 to 899
Data columns (total 5 columns):
apartment 900 non-null object
area 900 non-null object
size 900 non-null object
dis_to_subway 771 non-null object
price 900 non-null int64
dtypes: int64(1), object(4)
memory usage: 35.2+ KB2.数据清洗
(1) 把apartment属性分为小区名称(name)与房间数(num_rooms)。
- 例如“龙湖滟澜山茗轩南区三期4居室-南卧”可分为“龙湖滟澜山茗轩南区三期”,"4"。
rent_data['name']=rent_data['apartment'].apply(lambda x: x.split('-')[0][:-3])
rent_data['num_rooms']=rent_data['apartment'].apply(lambda x: x.split('-')[0][-3:-2])(2)提取area属性中的区域信息(district)、位置信息(location)、地铁信息(subway)、站点信息(station)。
- 例如"[下沙金沙湖] 1号线金沙湖"对应为为"下沙"、"金沙湖"、"1"、"金沙湖",这里用到了正则表达式。
import re
def get_district(area):
matchobj=re.search(r'\[(.*)\]',area)
return matchobj.group(1)[:2]
def get_location(area):
matchobj=re.search(r'\[(.*)\]',area)
return matchobj.group(1)[2:]
def get_subway(area):
matchobj=re.search(r'\d+',area)
if matchobj:
return matchobj.group()
else:
return ''
def get_station(area):
matchobj=re.search(r'\d.{2}(.*)',area)
if matchobj:
return matchobj.group(1)
else:
return ''
rent_data['district']=rent_data['area'].apply(get_district)
rent_data['location']=rent_data['area'].apply(get_location)
rent_data['subway']=rent_data['area'].apply(get_subway)
rent_data['station']=rent_data['area'].apply(get_station)(3)去掉房屋大小size字段的单位“㎡”,还有面积前面的“约”。
- 例如"9.3 ㎡"处理后为"9.3",“约10 ㎡”处理后为“10”。
def get_size(size):
size_split=size.split()[0]
matchobj=re.search(r'约(.+)',size_split)
if matchobj:
return matchobj.group(1)
else:
return size_split
rent_data['size']=rent_data['size'].apply(get_size)(4)从“距离地铁的距离”属性"dis_to_subway"中提取出距离。
- 例如从“距1号线金沙湖站186米”提取出“186”。
rent_data['dis_to_subway']=rent_data['dis_to_subway'].fillna('') #补全空值
def get_distance(dis_to_subway):
if not dis_to_subway=='':
matchobj=re.search(r'\D{2,}(\d+)',dis_to_subway)
return matchobj.group(1)
else:
return ''
rent_data['dis_to_subway']=rent_data['dis_to_subway'].apply(get_distance)3.删除多余属性
rent_data.drop(['apartment','area'],axis=1,inplace=True)
rent_data.sample(5)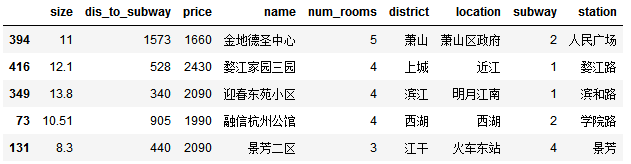
rent_data.to_csv('rent_data_clean.csv',index=False) #存入csv文件