前言
一开始我是拒绝的,因为不知道从何写起。还是强迫自己去做了这件事,希望自己在写的过程收获满满。
一、Blob简介
如果把一个网络结构Net比作一座大厦的话,那么层Layer就是每一层楼,而Blob就是砖。
Net中,每一层Layer之间数据传递就是以Blob形式传递的,包括正向的原始数据data和反向的梯度信息diff。它是一个四维数组,(Num,Channels,Height,Width), 也可以写成(n, k, h, w)。
以一张三通道480*640的图片为例子,如果转为Blob格式的数据,那么这个Blob大小为(1*3*480*640)。
如果结合caffe来看的话,N的大小是和每一Batch大小相同的。K是和每一层的output输出大小相同的。H和W就是每一层输出特征图的尺寸。注意哦,有些博客讲对于一个比方有1024输出和7*7卷积核的Convolution层,如果batch为1,那么输出Blob是(1,1024,7,7)。这个绝对是错的啊!!!输出的H和W是上一层的H和W经过7*7卷积核卷积运算过后的大小。
举个例子,上一层输出是(32,512,14,14),也就是说上一层输出特征图大小是14*14。当前层输出数量(卷积核数量)规定是1024,卷积核5*5,步长1,padding为0。那么输出结果特征图大小应该是(14-5)/1 + 1 = 10 * (14-5)/1 +1 = 10,所以输出Blob大小为(32,1024,10,10)。
二、Layer简介
Layer应该是Caffe的基本计算单元。Layer使得Net很有层次性,让我们很直观的看到计算进行的顺序和上下关系。
跟盖楼一致,数据是自下而上的计算传输。bottom为输入口,top为输出口。
Layer的一些派生类:
1. Vision Layer:负责处理视觉图像,输入输出都是图像。
1.1.Convolution卷积层:核心层。
lr_mult:学习率系数,当前层的学习率是根据solver.prototxt中base_lr学习率与此参数的乘积. 如果有两个这个参数, 那么第二个对应偏置项的学习率. 一般偏置项学习率是权值学习率的两倍.
num_oupput: 卷积核数量,也就是输出N的数量.
kernel_size:卷积核大小.如果宽高不等,可以用kernel_h和kernel_w设置.
stride:卷积核步长,默认为1.也可以用stride_h和stride_w设置.
pad: 边缘扩张,默认为0.也可以用pad_h和pad_w设置. 如果设置pad=(kernel_sizie-1)/2,那么卷积后的宽高不变.
weight_filler:权值初始化方式.默认是"constant", 全为0. 现在普遍用"xavier",也有用"gaussian"的.
bias_filler:偏置项初始化方式.一般设置为"constant",全为0.
group: 分组,默认为1组.
卷积层输出特征图宽高计算公式: 输出宽高 = (输入宽高 + 2*pad - kernel_size)/stride + 1
1.2.Pooling池化层: 降采样层,缩小数据大小.
kernel_sizie: 池化核大小
pool:池化方式,有MAX, AVE, STOCHASTIC. 计算方式是在池化核大小的矩阵内选最大或计算平均数作为当前连接的输出.
pad:边缘扩张.
stride:步长
1.3.Local Response Normalization(LRN)局部区域归一化: 侧抑制, 在AlexNet和GoogLeNet中有用到
local_size:默认5, 如果是跨通道归一化, 那么表示通道数. 如果是在一个通道内归一化, 则表示处理区域宽高.
alpha:默认1,公式中参数
beta:默认5,公式中参数
norm_region:默认为ACROSS_CHANNELS, 表示在相邻的通道间求和归一化. WITHIN_CHANNEL表示在一个通道内求和归一化.
归一化公式: 分子为每一个数, 分母为
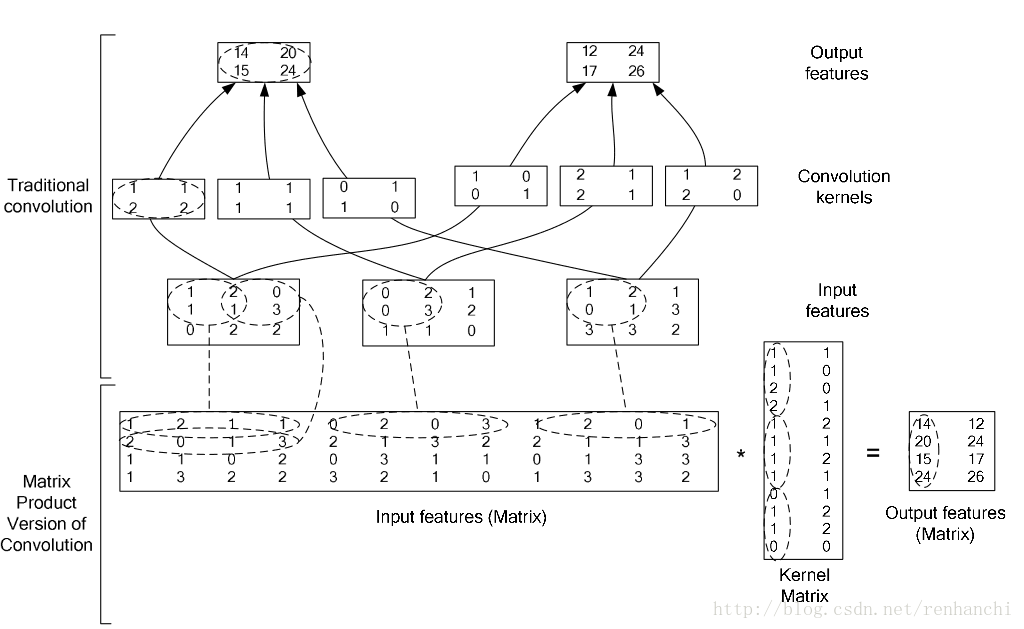
1.4.im2col层:将一个大矩阵,重叠的划分为多个子矩阵,对一个子矩阵序列化成向量,然后得到另外一个矩阵.
在caffe中, 卷积运算就是先对数据进行im2col操作, 再进行内积运算(inner product). 这样做比原始的卷积才做速度更快.
1.5.Batch Normalization(BatchNorm)层: 归一化, 0均值, 单位方差, 应用在resnet.
早期都使用白化处理数据, 常用的是PCA白化. 就是先对数据进行PCA处理, 然后在进行方差归一化.
但是白化需要计算协方差矩阵和求逆等操作, 计算量很大, 并且在反向传播的时候不一定可导.
理想情况是对整个数据集进行Norm处理, 但是不现实.
所以提出了Batch Norm, 用一个Batch的均值和方差作为对整个数据集均值和方差的估计.
BN算法流程如下:

有一个参数:
batch_norm_param {
use_global_stats: false
}
这个参数默认为false, 作用是使用当前batch数据的均值和方差做归一化,
如果设置为true, 则会使用所有数据的均值和方差做归一化. 这里留一个疑问, 我猜测应该是累积以往所有数据的均值和方差.
在训练阶段, 这个参数使用缺省设置, 就是false. 否则模型不收敛.
在检测阶段, 这个参数使用true. 否则准确率很低.
2. Loss Layers损失层:用于计算损失值, 根据损失值反向传播求梯度更新参数.
有Softmax(SoftmaxWithLoss), Sum-of-Squares/Euclidean(EuclideanLoss), Hinge/Margin(HingeLoss), Sigmoid Cross-Entropy(SigmoidCrossEntropyLoss), Infogain(InfogainLoss), Top-k
2.1.SoftmaxWithLoss
Softmax是一个分类器, 输出概率(likelihood), 是Logistic Regression的一种推广, 逻辑回归只能用于二分类, Softmax可以用于多分类.
在Softmax输出概率和已知类别的基础上做交叉熵计算, 可以求得当前类别的loss.
3. Activation/Neuron Layer 激活层: 运算为同址计算(in-place computation, 返回值覆盖原值而不占用新内存)
3.1.Sigmoid
没有额外参数. 将输入变量映射到[0,1]之间, 可以用作分类器. 求导容易. 但是,初始化结果会对sigmoid的输出产生很大影响. 如果初始化过大或者过小, 梯度会接近0, 使参数挂掉. 并且sigmoid函数的输出并没有0均值.
公式: y = 1/(1 + e ^ -x)
层类型: Sigmoid
3.2.TanH/Hyperbolic Tangent
双曲正切函数数据变换, 在形状上与Sigmoid十分接近. 将输入变量映射到[-1,1]之间, 求导容易, 输出期望为0, 所以在一定程度上TanH比Sigmoid要好一点. 与Sigmoid有共同的缺点, 就是对初始化敏感, 参数过大或者过小都会使梯度接近0.
公式: y = (e ^ x - e ^ -x) / (e ^ x + e ^ -x)
层类型: ThanH
3.3.ReLU/Rectified-Linear and Leaky-ReLU
ReLU是现在使用最多的激活函数, 收敛快, 易求导. 标准ReLU将负数都变为0, 在会影响数据表现. Leaky-ReLU设定一个参数, 让负数输入乘以这个参数, 在一定程度上保护了数据的表现.
标准ReLU公式: y = max(0, x)
Leaky-ReLU公式: y = max(x*negative_slope, x)
层类型: ReLU
3.4.Absolute Value
求每个输入数据的绝对值.
公式: y = Abs(x)
层类型: AbsVal
3.5.Power
对输入数据进行幂运算.
power: 默认为1
scale: 默认为1
shift: 默认为0
公式: y = (shift + scale * x) ^ power
层类型:Power
3.6.BNLL
Binomial Normal Log Likelihood
公式: y = log(1 + exp(x))
层类型: BNLL
4. Data Layer 数据层: 网络的最底层, 主要实现数据格式的转换.
高效率: LevelDB, LMDB, 内存. 低效率: hdf5, 图片格式
层类型: Data
include 设置是TEST阶段还是TRAIN阶段.
transform_param负责数据的预处理
根据输入来源不同, data_param参数不同.
4.1. transform_param
scale: 0.00390625 = 1/255, 将输入数据归一化.
mean_file_size: binaryproto 均值文件路径
mean_value: 重复三次,分别是三通道的均值. ImageNet常用均值为{104, 117, 123 }.
crop_size: 图片缩放尺寸
下面的处理在TRAIN阶段使用.
mirror: 0或1, true或false. 镜像处理.
4.2. 数据来自于LevelDB或者LMDB数据库
层类型:Data
data_param参数:
source: 包含数据库的目录路径.
batch_size: 批处理数量
backend: LevelDB或者LMDB, 默认是前者.
4.3.数据来自于内存
层类型: MemoryData
memory_data_param参数:
batch_size: 批数量
channels: 通道数
height: 高度
width: 宽度
4.4. 数据来自于hdf5
层类型: HDF5Data
hdf5_data_param参数:
source: 路径
batch_size: 批数量
4.5. 数据来自于图片
层类型: ImageData
image_data_param参数:
source:一个文本文件的路径,每一行是一张图片的路径和标签
root_folder: 路径, 和上面txt文件中路径组合为图片的完整路径.
batch_size: 批数量
shuffle: 随机打乱. 默认为false
new_height, new_width: 如果设置,则resize图片
4.6. 数据来自于Windows
层类型: WindowData
window_data_param参数:
source: 一个文本文件的路径
batch_size: 批数量
5. Common Layers
Inner Product(InnerProduct), Accuracy(Accuracy), Splitting(Split), Flattening(Flatten), Reshape(Reshape), Concatenation(Concat), Slicing(Slice), Elementwise(Eltwise), Argmax(ArgMax), Mean-Variance Normalization(MVN)
5.1. Inner Product 全连接层
输出维度为(n, k, 1, 1)
层类型: InnerProduct
lr_mult: 学习率系数
num_output: 即为k
weight_filler: 权值初始化方式. 默认为"constant", 全为0, 一般设置成"xavier"或者"gaussian"
bias_filler: 偏置项初始化方式, 一般设置为"constant", 全为0.
bias_term: 是否使用偏置项, 默认为true.
5.2. Accuracy
输出分类结果的精确度, 只有在TEST阶段才有, 需要加入include参数.
层类型: Accuracy
5.3. Dropout
用于防止过拟合, 随机让某些层节点权值不失效.
dropout_ratio: 失效节点百分比
5.4. Concatenation
输入数据的拼接
层类型: Concat
axis: (n, k, h, w)的索引, 表示拼接该通道.
5.5. Slicing
输入数据的拆分, 与Concatenation功能相反.
层类型: Slice
axis: 作用参照上面.
slice_point: 此参数个数必须比top数量少一个. 第一个参数表示第一个拆分出来的数据的数量, 以此类推. 最后一个数据的数量等于总数量减去前面所有参数的结果.
以上内容, 部分参考自: http://www.cnblogs.com/denny402/category/759199.html