一、源码编译安装:
安装前建议你备份一下/usr/include/目录下opencv和opencv2两个目录。
反正我每次安装完tesseract后,我的opencv头文件不是没了就是出问题。
github地址:https://github.com/tesseract-ocr/tesseract/releases
建议下载安装4.0版本,有LSTM,准确率和速度都不错。
其次建议下载安装3.05版本,也是此时的最新版本,没有LSTM。
安装介绍地址:https://github.com/tesseract-ocr/tesseract/blob/master/INSTALL.GIT.md
懒得打开上面安装链接的看下面就好。
1. 先安装各种依赖
sudo apt-get install g++ # or clang++ (presumably) sudo apt-get install autoconf automake libtool sudo apt-get install autoconf-archive sudo apt-get install pkg-config sudo apt-get install libpng12-dev sudo apt-get install libjpeg8-dev sudo apt-get install libtiff5-dev sudo apt-get install zlib1g-dev
如果你要安装训练工具的话,还要安装下面三个依赖
sudo apt-get install libicu-dev sudo apt-get install libpango1.0-dev sudo apt-get install libcairo2-dev
2. 然后安装Leptonica
这个软件有很多版本,先给你下载地址,然后给你版本对照表。
官网地址:http://www.leptonica.org/
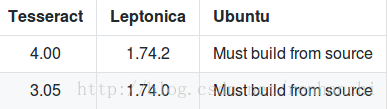
必须源码编译安装,默认安装目录在/usr/local/下
3. 安装tesseract
./autogen.sh ./configure make sudo make install sudo ldconfig make training sudo make training-install
二、部分API介绍
预训练模型地址:https://github.com/tesseract-ocr/tessdata
预训练模型可以放到任意位置,也可以放到默认位置:/usr/local/share/tessdata/
这个方法基本原理我当时也没深研究。
我理解大概就是先把图片转化为灰度图。
然后以当前点为中心,判断周围一圈的点是否不为白色。
如果这个点不是白色,那么继续以这个点为中心点向外扩张。
通过上面简单原理,我们可以知道。
输入图片越小运行速度越快
输入图片越干净输出越准确
字符不能有过大旋转角度(作者肯定不会360度旋转训练模型,他也确实没这么做)
下面是API例子:
#include <tesseract/baseapi.h>
#include <leptonica/allheaders.h>
#include <opencv2/core/core.hpp>
#include <opencv2/imgproc/imgproc.hpp>
#include <opencv2/highgui/highgui.hpp>
int main()
{
char *outText;
tesseract::TessBaseAPI *api = new tesseract::TessBaseAPI();
//设置识别引擎,如果要用cube引擎,需要去上面下载cube对应的预训练模型。
tesseract::OcrEngineMode enginemode = static_cast(0);
/*
"OCR Engine modes:"
" 0 Original Tesseract only."
" 1 Cube only."
" 2 Tesseract + cube."
" 3 Default, based on what is available."
4 Neural nets (LSTM) only.(版本4.0才有)
*/
// 初始化,NULL可以替换成你存放预训练模型的路径。下面"eng"可以是"eng++chi_sim"形式。
if (api->Init(NULL, "eng", enginemode))
{
fprintf(stderr, "Could not initialize tesseract.\n");
exit(1);
}
//下面两句话都是设置只识别数字,第一种方法是打开识别开关,第二种方法是只识别白名单内字符。当然还有黑名单。具体看下面我给的API地址。
//api->SetVariable("classify_bln_numeric_mode", "1");
//api->SetVariable("tessedit_char_whitelist", "0123456789");
//设置识别页面类型
tesseract::PageSegMode pagesegmode = static_cast(7);
api->SetPageSegMode(pagesegmode);
/*
"Page segmentation modes:"
" 0 Orientation and script detection (OSD) only."
" 1 Automatic page segmentation with OSD."
" 2 Automatic page segmentation, but no OSD, or OCR."
" 3 Fully automatic page segmentation, but no OSD. (Default)"
" 4 Assume a single column of text of variable sizes."
" 5 Assume a single uniform block of vertically aligned text."
" 6 Assume a single uniform block of text."
" 7 Treat the image as a single text line."
" 8 Treat the image as a single word."
" 9 Treat the image as a single word in a circle."
" 10 Treat the image as a single character."
" 11 Sparse text. Find as much text as possible in no particular order."
" 12 Sparse text with OSD."
" 13 Raw line. Treat the image as a single text line,"
*/
// Open input image with leptonica library
Pix *image = pixRead("/usr/src/tesseract/testing/phototest.tif");
api->SetImage(image);
//下面是通过opencv读取图片
//cv::Mat gray_img, thres_img;
//cv::Mat img = cv::imread("");
//cv::cvtColor(img, gray_img, cv::COLOR_BGR2GRAY);
//cv::threshold(gray_img, thres_img, 127., 255., cv::THRESH_BINARY);
//api->SetImage((uchar*)thres_img.data, thres_img.cols, thres_img.rows, 1, thres_img.cols);
// Get OCR result
outText = api->GetUTF8Text();
printf("OCR output:\n%s", outText);
// Destroy used object and release memory
api->End();
delete [] outText;
pixDestroy(&image);
return 0;
}
API头文件地址:https://github.com/tesseract-ocr/tesseract/blob/master/api/baseapi.h
先这样吧,这个工具功能蛮强大的。还需要时间慢慢研究。
顺便提一嘴我做卡片识别的思路。
关键技术是opencv的findContours()配合finetune后的mnist,数字识别效果拔群。
以上部分内容参考自:https://github.com/tesseract-ocr/tesseract