3、快速理解picamera
通过默认配置,开启摄像头,并预热10秒钟。
import time
import picamera
camera = picamera.PiCamera()
try:
camera.start_preview()
time.sleep(10)
camera.stop_preview()
finally:
camera.close()- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
运行后,可以看到摄像头的指示灯亮起10秒钟后熄灭。这里需要注意的是,每次调用后都需要通过close释放掉picamera的资源。
下面演示了python的with语句块,来隐式的开启picamera执行并最后释放掉资源(调用了close())
import time
import picamera
with picamera.PiCamera() as camera:
camera.start_preview()
time.sleep(10)
camera.stop_preview()- 1
- 2
- 3
- 4
- 5
- 6
- 7
下面这个例子介绍了picamera的某些属性可以被动态调整。在例子中,亮度属性被逐渐增加。
import time
import picamera
with picamera.PiCamera() as camera:
camera.start_preview()
try:
for i in range(100):
camera.brightness = i
time.sleep(0.2)
finally:
camera.stop_preview()- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
下面这个例子演示了,picamera将分辨率设置为640*480并开启摄像头进行预览60秒,并将预览内容写入名为”foo.h264”的文件中。
import picamera
with picamera.PiCamera() as camera:
camera.resolution = (640, 480)
camera.start_preview()
camera.start_recording('foo.h264')
camera.wait_recording(60)
camera.stop_recording()
camera.stop_preview()- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
摄像头的默认分辨率为显示器的分辨率,如果显示器被禁用,则默认分辨率为1280*768。
这里需要注意的是,wait_recording()方法替代了time.sleep()方法,并且同时开始录制,此方法会抛出错误(例如磁盘已满),所以如果用time.sleep来代替wait_recording的话,stop_recording()的执行会被time.sleep所阻断,带休眠时间以后才会被执行。
下面这个例子演示的是,在开启摄像头之前设置了一些参数,然后捕捉一张照片存储到foo.jpg的文件中:
import time
import picamera
with picamera.PiCamera() as camera:
camera.resolution = (1280, 720)
camera.start_preview()
camera.exposure_compensation = 2
camera.exposure_mode = 'spotlight'
camera.meter_mode = 'matrix'
camera.image_effect = 'gpen'
# 初始化预热摄像头
time.sleep(2)
camera.capture('foo.jpg')
camera.stop_preview()- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
下面这个例子可以利用picamera来给拍摄的图像上打上Exif标记。
import time
import picamera
with picamera.PiCamera() as camera:
camera.resolution = (2592, 1944)
camera.start_preview()
time.sleep(2)
camera.exif_tags['IFD0.Artist'] = 'Me!'
camera.exif_tags['IFD0.Copyright'] = 'Copyright (c) 2013 Me!'
camera.capture('foo.jpg')
camera.stop_preview()- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
接下来的文档会详细介绍Exif标记的完整属性。
下面这个例子演示拍摄连续拍摄100次,每次暂停60秒,并且将拍摄的内容以“image{counter:02d}.jpg的格式保存在磁盘上,其中d为递增变量。
import time
import picamera
with picamera.PiCamera() as camera:
camera.resolution = (1280, 720)
camera.start_preview()
time.sleep(1)
for i, filename in enumerate(camera.capture_continuous('image{counter:02d}.jpg')):
print('Captured image %s' % filename)
if i == 100:
break
time.sleep(60)
camera.stop_preview()- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
下面这个例子演示了,在低分辨率的情况下,通过capture_sequence方法快速捕捉图像:
import time
import picamera
with picamera.PiCamera() as camera:
camera.resolution = (640, 480)
camera.start_preview()
start = time.time()
camera.capture_sequence((
'image%03d.jpg' % i
for i in range(120)
), use_video_port=True)
print('Captured 120 images at %.2ffps' % (120 / (time.time() - start)))
camera.stop_preview()- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
下面这个例子演示了,通过picamera来捕捉一张图像,并且通过RGB格式进行解码,生成一个numpy的图像阵列。
import time
import picamera
import picamera.array
with picamera.PiCamera() as camera:
with picamera.array.PiRGBArray(camera) as stream:
camera.resolution = (1024, 768)
camera.start_preview()
time.sleep(2)
camera.capture(stream, 'rgb')
print(stream.array.shape)4、picamera基本使用方法
如果你是一个python程序员,那么你将轻松的掌握以下实例,请随时提出改进或新的实例。
4.1、捕捉一个图像输出至文件
使用capture方法可以轻松将捕捉到的图像输出至指定文件。
下面这个实例是捕捉一个分辨率为1024*768的图像,并将之输出到foo.jpg中:
import time
import picamera
with picamera.PiCamera() as camera:
camera.resolution = (1024, 768)
camera.start_preview()
#摄像头预热2秒
time.sleep(2)
camera.capture('foo.jpg')- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
需要注意的是,若目录中有同名文件,picamera将会重置该图片。
4.2、捕捉一个流
这个实例是通过capture()方法将捕捉的一个图像转成一个以jpeg解码的流(bytes流):
import io
import time
import picamera
# 创建一个流
my_stream = io.BytesIO()
with picamera.PiCamera() as camera:
camera.start_preview()
# 摄像头预热
time.sleep(2)
camera.capture(my_stream, 'jpeg')- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
需要注意的是,这不像输出到一个文件,该流捕捉以后会自动关闭脚本,因为在这个实例中没有对流进行其他操作。若对象有flush方法的话,在捕捉完毕后,会调用对象的flush方法,如下:
import time
import picamera
# 打开一个扩展名为jpg的文件
my_file = open('my_image.jpg', 'wb')
with picamera.PiCamera() as camera:
camera.start_preview()
time.sleep(2)
camera.capture(my_file)
# 在此时capture会调用my_file的flush方法,完成流封装。
# 但并未关闭文件,需要调用close进行关闭
my_file.close()- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
上边这个实例需要注意的是,我们并没有指定捕捉文件的解码格式,所以capture会获取输出的文件名的扩展名来寻找解码属性。
4.3、捕捉一个图像转化为PIL imag对象
首先我们要捕捉一个图像流,然后通过流读取将图像的数据转换成PIL image对象。
import io
import time
import picamera
from PIL import Image
# 创建一个流
stream = io.BytesIO()
with picamera.PiCamera() as camera:
camera.start_preview()
time.sleep(2)
camera.capture(stream, format='jpeg')
# 将指针指向流的开始
stream.seek(0)
image = Image.open(stream)- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
4.4、捕捉一个图像转化为open cv对象
首先我们捕捉一个图像流,然后将图像数据转换为open cv对象:
import io
import time
import picamera
import cv2
import numpy as np
# 创建一个流
stream = io.BytesIO()
with picamera.PiCamera() as camera:
camera.start_preview()
time.sleep(2)
camera.capture(stream, format='jpeg')
# 从流构建numpy
data = np.fromstring(stream.getvalue(), dtype=np.uint8)
# 通过opencv解码numpy
image = cv2.imdecode(data, 1)
# opencv解码后返回以RGB解码的图像数据
image = image[:, :, ::-1]- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
如果你不想使用有损JPEG编码,并希望加快这一解码过程的话,可以使用picamera自带的picamera.array模块。可以使用PiRGBArray类简单的捕获’brg’格式的数据。(假定RGB与BGR是分辨率相同的数据,只是具有相反的颜色)
import time
import picamera
import picamera.array
import cv2
with picamera.PiCamera() as camera:
camera.start_preview()
time.sleep(2)
with picamera.array.PiRGBArray(camera) as stream:
camera.capture(stream, format='bgr')
# 此时就可以获取到bgr的数据流了
image = stream.array- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
4.5、调整捕捉图像的分辨率
有时,我们需要将图片进行某种分析或处理,你希望尽可能的捕获比较小分辨率的图像,虽然这种分辨率的调整可以交给PIL或者opencv来完成,但是通过picamera可以更搞笑的完成这个操作:
import time
import picamera
with picamera.PiCamera() as camera:
camera.resolution = (1024, 768)
camera.start_preview()
# 摄像头预热
time.sleep(2)
camera.capture('foo.jpg', resize=(320, 240))- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
同时调整分辨率的参数也可以适用于捕获视频的start_recording()方法。
4.6、捕获连续图像
您可能希望连续捕捉到的图像的亮度、色彩与对比度上保持一致(例如,这个可能在延迟摄影中非常有用)。可以设置一些属性,确保在多个镜头中保持画面的一致。具体来说,您需要保证摄像头的曝光时间,白平衡和画面增益都是固定的。
- 设置曝光时间:shutter_speed
- 设置画面增益:首先将 exposure_mode设置为’off’然后将analog_gain和digital_gain设置在合理的范围值。
- 设置白平衡:将awb_mode设置为’off’,然后将awb_gains设置为red或者blue或者直接设置iso的值。
设置这些属性是非常专业的,并且非常难调整到合适的范围值。在白天,对于iso,100~200是一个简单的合理范围,而在低光环境下,需要调整到400~800。对于shutter_speed如果需要确定一个合理的范围值可以直接查询exposure_speed属性。对于曝光增益,通常只需要将analog_gain设置为大于1的值(analog_gain的默认值为1,但这将产生一个全黑的图像帧)。
下面的这个例子提供了一些简单配置的实例:
import time
import picamera
with picamera.PiCamera() as camera:
camera.resolution = (1280, 720)
camera.framerate = 30
# 等待摄像头预热,适应光线环境
time.sleep(2)
# 现在设置图像修正值
camera.shutter_speed = camera.exposure_speed
camera.exposure_mode = 'off'
g = camera.awb_gains
camera.awb_mode = 'off'
camera.awb_gains = g
# 最后将采取修正值的图像输出到文件
camera.capture_sequence(['image%02d.jpg' % i for i in range(10)])- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
4.7、捕获延时拍摄序列
有一种需求就是,每若干分钟捕获一张图像,并存储起来,若像实现这种需求最简单的方法就是capture_continuous()函数。调用这个函数时,会不断捕捉摄像头图像,知道调用停止函数。这样你可以很轻易的控制定时捕获两张图片之间的时间。
接下来这个例子就是演示每5分钟定时抓拍一张图片:
import time
import picamera
with picamera.PiCamera() as camera:
camera.start_preview()
time.sleep(2)
for filename in camera.capture_continuous('img{counter:03d}.jpg'):
print('Captured %s' % filename)
time.sleep(300) # 休眠5分钟- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
除了延时捕获图像以外,还可以通过datetime来计算时间,在特定的时间开启摄像头捕获图像。
import time
import picamera
from datetime import datetime, timedelta
def wait():
# 计算时间,将从下一个小时开始捕获图像
next_hour = (datetime.now() + timedelta(hour=1)).replace(
minute=0, second=0, microsecond=0)
delay = (next_hour - datetime.now()).seconds
time.sleep(delay)
with picamera.PiCamera() as camera:
camera.start_preview()
wait()
for filename in camera.capture_continuous('img{timestamp:%Y-%m-%d-%H-%M}.jpg'):
print('Captured %s' % filename)
wait()- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
4.8、在光线比较弱的环境下捕获图像
树莓派的摄像头可以在光纤比较弱的环境下捕获图像,其主要的实现方式是通过设置捕获属性,给摄像头设置一个比较高的光线增益,以及增加曝光的时间以让摄像头接收尽可能多的光。我们可以通过设置shutter_speed[设置曝光时间]与framerate[帧率]两个参数。首先我们要设置一个比较慢的帧率,然后将曝光时间设置为6秒来捕获图像:
import picamera
from time import sleep
from fractions import Fraction
with picamera.PiCamera() as camera:
camera.resolution = (1280, 720)
# 设置帧率为1/6fps,然后将曝光时间设置为6秒
# 最后将iso参数设置为800
camera.framerate = Fraction(1, 6)
camera.shutter_speed = 6000000
camera.exposure_mode = 'off'
camera.iso = 800
# 给摄像头一个比较长的预热时间,让摄像头尽可能的适应周围的光线
# 你也可以试试开启AWB【自动白平衡】来代替长时间的预热
sleep(10)
# 最后捕捉图像,因为我们将曝光时间设置为6秒,所以拍摄的时间比较长
camera.capture('dark.jpg')- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
如果在一个光线不是特别暗的地方使用以上实例,则你会得到一个严重曝光以至于可能是全白的图像文件。
因为我们设置了一个比较长的曝光时间,如果这时移动摄像头,那么我们将会得到一个严重图像扭曲的照片。
4.9、将捕获的流转换为网络流
这是一个将捕获的图片通过网络传给服务器的例子。在这个例子中我们有两个脚本:服务器端,树莓派端。然后通过socket进行连接。我们使用一种简单的数据包协议。首先我们数据包的前4个字节是类型为int值的数据,代表图像数据的长度,然后是图像的数据。若收到的数据长度为0,则代表picamera已经停止捕获图像。
数据包格式如下: 
首先在服务器运行一下脚本(这个脚本是基于PIL包来解析jpeg文件,你也可以使用其他的图形库,比如opencv或graphicsMagick等来替代PIL):
import io
import socket
import struct
from PIL import Image
# 启动socket,设置监听端口为8000,接受所有ip的连接
server_socket = socket.socket()
server_socket.bind(('0.0.0.0', 8000))
server_socket.listen(0)
# 接受一个客户端连接
connection = server_socket.accept()[0].makefile('rb')
try:
while True:
# 读取我们的包头,也就是图片的长度
# 如果长度为0则退出循环
image_len = struct.unpack('<L', connection.read(struct.calcsize('<L')))[0]
if not image_len:
break
# 构造一个流来接受客户端传输的数据
# 开始接收数据并写入流
image_stream = io.BytesIO()
image_stream.write(connection.read(image_len))
# 将流的指针指向开始处,并通过PIL来读入流
# 并将之存储到文件
image_stream.seek(0)
image = Image.open(image_stream)
print('Image is %dx%d' % image.size)
image.verify()
print('Image is verified')
finally:
connection.close()
server_socket.close()- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
树莓派脚本如下:
import io
import socket
import struct
import time
import picamera
# 连接之前创建的服务器端
# 将my_server替换成服务器的ip
client_socket = socket.socket()
client_socket.connect(('my_server', 8000))
# 创建一个连接
connection = client_socket.makefile('wb')
try:
with picamera.PiCamera() as camera:
camera.resolution = (640, 480)
# 摄像头预热
camera.start_preview()
time.sleep(2)
# 记录一个开始时间,并构建一个流来存储捕获的图片数据
# 我们可以直接讲捕获的数据流传给服务器,但为了捕获我们的图像长度,
# 我们暂且阻碍传输,并等待捕获完成,并获取图长度组建数据包
start = time.time()
stream = io.BytesIO()
for foo in camera.capture_continuous(stream, 'jpeg'):
# 将数据写入流中
connection.write(struct.pack('<L', stream.tell()))
connection.flush()
# 将数据流的指针指向起始位置
connection.write(stream.read())
# 如果我们的等待的连接时间大于30秒则退出循环
if time.time() - start > 30:
break
# 重置捕获流,等待下一次捕获图像。
stream.seek(0)
stream.truncate()
# 循环结束,写一个长度为0的数据包,告知服务器我们已经完成了整个操作。
connection.write(struct.pack('<L', 0))
finally:
connection.close()
client_socket.close()- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
4.10、录制视频文件
录制一个视频文件很简单:
import picamera
with picamera.PiCamera() as camera:
camera.resolution = (640, 480)
camera.start_recording('my_video.h264')
camera.wait_recording(60)
camera.stop_recording()- 1
- 2
- 3
- 4
- 5
- 6
- 7
请注意,我们在这里使用的方法是wait_recording,而不是time.sleep(),以下的例子也是使用这个方法来演示,虽然功能上与time.sleep相同,但是wait_recording会不断的监听错误的抛出(比如磁盘空间不足),一旦出现错误会立即暂停捕获图像,来处理当前的错误,而不是在sleep以后才进行处理。所以如果我们用time.sleep来替代wait_recording方法的话,这种错误只能在stop_recording()后才能被处理,这可能导致了我们未能及时处理错误,导致图像数据捕获失败。
4.11、将录制的视频转换为数据流
这个例子与将录制的视频存储到文件很像:
import io
import picamera
stream = io.BytesIO()
with picamera.PiCamera() as camera:
camera.resolution = (640, 480)
camera.start_recording(stream, format='h264', quality=23)
camera.wait_recording(15)
camera.stop_recording()- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
在这里,我们设置了一个视频质量参数quality,指示解码器将图像质量维持在23左右。H.264视频编码主要取决于两个参数:
- 视频输出是以秒为单位,单位时间内输出的视频最大则质量越高,视频输出的默认缺省为17000000(17Mbps)最大值为25000000(25Mbps)。我们设置的参数越大,则解码器会在相应的品质上进行解码。你可能会发现,除非你使用更高的分辨率,否则在默认情况下是不需要限制视频质量的。
- 质量参数通知解码器保持什么水平的图像进行录制。quality参数值的的范围是1(最高质量)~40(最低质量),在普通的4M宽带下,将视频质量设置为20~25之间是合理范围。
4.12、录制多个视频文件
如果你希望将视频文件分割多个进行录制,可以使用split_recording()方法来实现这个功能:
import picamera
with picamera.PiCamera() as camera:
camera.resolution = (640, 480)
camera.start_recording('1.h264')
camera.wait_recording(5)
for i in range(2, 11):
camera.split_recording('%d.h264' % i)
camera.wait_recording(5)
camera.stop_recording()- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
在实例中,我们通过split_recording函数来分割录制10个视频文件,每个视频文件的时间为5秒。
也可以利用record_sequence()函数来实现这个功能,而且代码更加简洁:
import picamera
with picamera.PiCamera() as camera:
camera.resolution = (640, 480)
for filename in camera.record_sequence(
'%d.h264' % i for i in range(1, 11)):
camera.wait_recording(5)- 1
- 2
- 3
- 4
- 5
- 6
- 7
record_sequence这个方法适用于1.3以后的版本。
4.13、循环录制
这个功能类似于将录制的视频转换成文件流,区别是,picamera将产生一个loop缓冲区,如果在缓冲区已满,则picamera会将最开头的视频替换掉,以保证在缓冲区的视频是最新的。
一个典型的例子,就是安全监控实例,在这个实例中,我们希望检测到视频内有移动的物体,然后将这段视频记录起来。本例中我们先进行录制20秒的视频,并将其存储到文件流中,直到write_now返回true才会将这个缓存区域存储起来(这段实现比较多样,我们可以使用任意一个检测图像运动的算法来实现这个例子)。如果我们检测到有移动的物体,那么我们将刷新缓存中录制10秒的视频,并将该视频保存至磁盘:
import io
import random
import picamera
def write_now():
# 在这我们做一个假的例子,产生一个随机的true来代替检测到运动的物体
return random.randint(0, 10) == 0
def write_video(stream):
print('Writing video!')
with stream.lock:
# 找到视频的起始端
for frame in stream.frames:
if frame.frame_type == picamera.PiVideoFrameType.sps_header:
stream.seek(frame.position)
break
# 将流输出到磁盘
with io.open('motion.h264', 'wb') as output:
output.write(stream.read())
with picamera.PiCamera() as camera:
stream = picamera.PiCameraCircularIO(camera, seconds=20)
camera.start_recording(stream, format='h264')
try:
while True:
camera.wait_recording(1)
if write_now():
# 检测到移动的物体
# 进行10秒的录制,并将录制的视频存放至缓存区
camera.wait_recording(10)
write_video(stream)
finally:
camera.stop_recording()- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
在上面的示例中,我们使用了线程锁,以防止我们在保存视频时缓存区的录像被修改(因为我们创建的缓存流是一个loop缓冲区,是可以读写覆盖的)。如果没有使用with语句块,那么我们在写入完成时,应该取消对缓存的stream.lock锁。
需要注意的是,缓存区最少要有20秒的视频,因为使用H.264解码的话,最小码率为17Mbps,所以超过或等于20秒的视频流才是可用的视频。
这功能支持1.0及以后版本。
4.14、将录制的视频用于网络传输
这个功能类似于录制视频流,但区别在于,我们将创建一个socket对象,这不像我们传输图像的数据协议那么复杂,我们并不需要对视频流进行数据包的封装。这一次,我们将持续发送视频的帧组成的数据流,以便简化我们的socket视频通讯。
首先我们开始编写服务器端脚本:
import socket
import subprocess
# 首先我们创建一个socket监听,端口为8000,接受所有的ip连接
server_socket = socket.socket()
server_socket.bind(('0.0.0.0', 8000))
server_socket.listen(0)
# 然后我们创建一个socket文件流
connection = server_socket.accept()[0].makefile('rb')
try:
# 如果接受到一个客户端连接,那么我们将通过终端来打开一个播放器。
# 如果你使用的是mplayer,则需要注释掉vlc这段。
cmdline = ['vlc', '--demux', 'h264', '-']
#cmdline = ['mplayer', '-fps', '25', '-cache', '1024', '-']
player = subprocess.Popen(cmdline, stdin=subprocess.PIPE)
while True:
# 创建一个死循环,每次读取1k的数据
# 然后将数据传送到播放器
data = connection.read(1024)
if not data:
break
player.stdin.write(data)
finally:
connection.close()
server_socket.close()
player.terminate()- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
注意,如果你是在Windows上运行此代码,则需要提供完成播放器exe文件路径。
你可能会注意到,播放的视频有几秒钟的延迟,不用担心,这是正常现象,因为媒体播放器为了能够流畅的播放视频,会事先换成几秒的视频流,以防止网络卡顿。但是一些播放器(比如mplayer)允许用户跳过缓存或减少缓冲区直接播放视频,虽然这将提高了播放的卡顿和中断播放的现象,但是视频的延迟将大大减少。
现在我们来编写树莓派端代码:
import socket
import time
import picamera
# 创建一个socket连接,来连接我们的服务器,这里需要将my_server替换成服务器的ip
client_socket = socket.socket()
client_socket.connect(('my_server', 8000))
# 创建一个socket文件流
connection = client_socket.makefile('wb')
try:
with picamera.PiCamera() as camera:
camera.resolution = (640, 480)
camera.framerate = 24
# 开启摄像头,并预热两秒
camera.start_preview()
time.sleep(2)
# 开始录制并传输,录制视频总长度为60秒
camera.start_recording(connection, format='h264')
camera.wait_recording(60)
camera.stop_recording()
finally:
connection.close()
client_socket.close()- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
还可以指出的是,我们能够利用netcat和raspivid命令来快速实现这段脚本,在终端上运行以下代码:
server-side: nc -l 8000 | vlc --demux h264 -
client-side: raspivid -w 640 -h 480 -t 60000 -o - | nc my_server 8000- 1
- 2
然而,我们可以将连接反过来,通过树莓派简历一个视频服务器,等待播放器的连接。当连接简历时,我们会录制60秒的视频,并实时传输过去。这样我们可以先初始化摄像头的连接,等待播放器的接入:
import socket
import time
import picamera
with picamera.PiCamera() as camera:
camera.resolution = (640, 480)
camera.framerate = 24
server_socket = socket.socket()
server_socket.bind(('0.0.0.0', 8000))
server_socket.listen(0)
# 创建一个socket文件流
connection = server_socket.accept()[0].makefile('wb')
try:
camera.start_recording(connection, format='h264')
camera.wait_recording(60)
camera.stop_recording()
finally:
connection.close()
server_socket.close()- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
然后我们可以通过播放器来打开这个网络地址,这里演示的是利用vlc来打开摄像头:
vlc tcp/h264://my_pi_address:8000/- 1
注意的是,目前,VLC或mplayer都不会对视频流进行GPU解码,他们会先尝试利用CPU进行解码,但这种软解码的效率不够强大。所以为了能够顺利播放,你需要将播放器运行在一个性能比较好的设备上(废话。。。)
4.15、在捕捉的图像上叠加图片
在摄像头进行捕捉的同时我们可以运行多层渲染器,然而picamera只允许加载单个渲染器到相机端,所以如果想在捕获的图像上叠加图片,我可以需要创建一个附加的渲染器来显示我们捕捉到的静态图像。
注意,picamera不支持在捕捉图像或拍摄视频的同时来叠加图像信息,如果需要嵌入一些文字信息请参阅下面的“在捕捉的图像上叠加文字信息”
叠加图片工作是一个比较复杂的操作,因为摄像头模块的大小是32X16,所以渲染的图片的宽度必须是32的倍数,其高度必须是RGB格式所规定的字节。不过虽然听上去很复杂,但是实现起来却很简单。
下面这个实例演示的是,加载任意一个图像或PIL,让他扩展到RGB允许的尺寸,这将调用add_overlay()函数:
import picamera
from PIL import Image
from time import sleep
with picamera.PiCamera() as camera:
camera.resolution = (1280, 720)
camera.framerate = 24
camera.start_preview()
# 读取任意一张图片
img = Image.open('overlay.png')
# 创建一个新的RGB渲染器,并指定渲染器的格式
pad = Image.new('RGB', (
((img.size[0] + 31) // 32) * 32,
((img.size[1] + 15) // 16) * 16,
))
# 将原始图片加载到渲染器中
pad.paste(img, (0, 0))
# 在这里我们使用原始图片的尺寸来进行叠加
o = camera.add_overlay(pad.tostring(), size=img.size)
# 在默认情况下,图片将叠加在第0层上,下方是我们的摄像头图片层(第2层)
# 这里我们将图片设置为盘透明并覆盖在捕捉的图像上
o.alpha = 128
o.layer = 3
# 创建一个死循环,等待用户终止脚本
while True:
sleep(1)- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
我们可以不使用一个图片文件作为叠加源,我们可以直接从numpy中产生叠加图片数据。在下面的例子中,我们构建了一个numpy 以捕捉图片相同的分辨率覆盖在图片上,并在重心画一个白色的十字以标示出我们的覆盖物。
import time
import picamera
import numpy as np
# 创建一个numpy空间,指定分辨率为1280*720,并在画面中间画一个十字
a = np.zeros((720, 1280, 3), dtype=np.uint8)
a[360, :, :] = 0xff
a[:, 640, :] = 0xff
with picamera.PiCamera() as camera:
camera.resolution = (1280, 720)
camera.framerate = 24
camera.start_preview()
# 我们通过add_overlay直接将覆盖物叠加在第3层上,这里我们可以省略覆盖物的尺寸
# 默认为捕获图片的尺寸
o = camera.add_overlay(np.getbuffer(a), layer=3, alpha=64)
try:
# 等待用户终止脚本
while True:
time.sleep(1)
finally:
camera.remove_overlay(o)- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
我们可以调成layer参数以隐藏渲染器(layer默认为2),或者可以通过alpha参数设置渲染器的透明度和调整渲染器的大小,使渲染器不用拉伸显示在界面上。我们也可以通过叠加图片来构建简单的用户界面。
这功能支持1.8及以后版本。
4.16、在捕捉的图像上叠加文字
相机模块包含一个基本的注释工具,它最多可允许在图片上叠加255个ASCII字符(包括在图片或视频的捕捉中或捕捉后进行叠加)。想要实现这一功能,只需要将需要叠加的文字填在annotate_text参数上:
import picamera
import time
with picamera.PiCamera() as camera:
camera.resolution = (640, 480)
camera.framerate = 24
camera.start_preview()
camera.annotate_text = 'Hello world!'
time.sleep(2)
# 将图片输出到文件
camera.capture('foo.jpg')- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
我们也可以通过一点技巧来显示比较长的字符串:
import picamera
import time
import itertools
s = "This message would be far too long to display normally..."
with picamera.PiCamera() as camera:
camera.resolution = (640, 480)
camera.framerate = 24
camera.start_preview()
camera.annotate_text = ' ' * 31
for c in itertools.cycle(s):
camera.annotate_text = camera.annotate_text[1:31] + c
time.sleep(0.1)- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
当然,这个功能也可以用在显示或嵌入录像的时间戳(该实例还演示了在绘制的时间戳下利用annotate_background属性填充背景色):
import picamera
import datetime as dt
with picamera.PiCamera() as camera:
camera.resolution = (1280, 720)
camera.framerate = 24
camera.start_preview()
camera.annotate_background = picamera.Color('black')
camera.annotate_text = dt.datetime.now().strftime('%Y-%m-%d %H:%M:%S')
camera.start_recording('timestamped.h264')
start = dt.datetime.now()
while (dt.datetime.now() - start).seconds < 30:
camera.annotate_text = dt.datetime.now().strftime('%Y-%m-%d %H:%M:%S')
camera.wait_recording(0.2)
camera.stop_recording()- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
该功能支持1.7及以后版本。
4.17、控制摄像头的led指示灯
摄像头的led指示灯指示了该摄像头模块在开启中,但是在某种情况下,这可能会是一个障碍,比如你在拍摄野外动物的情况下,这个led灯可能会吓跑动物,而且在近距离拍摄的时候,可能会将led的灯光反射到摄像头上。
你可以利用一些简单的方式来解决,比如用胶带或者一些遮挡物来挡住led灯,也可以通过picamera来设置disable_camera_led属性关闭led指示灯。
但是这种操作需要有RPi.GPIO库的支持,以及提供运行该python脚本足够的权限(这意味着你将需要通过root身份来运行这段脚本)才可以控制Led灯的属性。
import picamera
with picamera.PiCamera() as camera:
# 将led指示灯设置为关闭
camera.led = False
# 这时拍照时指示灯不会亮起
camera.capture('foo.jpg')- 1
- 2
- 3
- 4
- 5
- 6
- 7
这里需要注意的是,当你第一次使用led属性来控制指示灯时,GPIO库将设置为BCM模式[GPIO.setmode(GPIO.BCM)]和禁止使用警示灯[GPIO.setwarnings(False)],所以这将使你无法控制板载led灯,如果想控制则需要手动开启。
5、picamera的高级使用
下面的这些实例包含了picamera的一些高级使用方式,可能需要有一些图像开发经验才能掌握。所以请随时提出改进或更多的实例。
5.1、无损格式图像采集(YUV格式)
如果你不想损失拍摄图像的细节(由于jpeg是有损压缩),那么你可以通过PNG来接收拍摄的图像(PNG为无损压缩格式),然而某些应用需要YUV(YUV是被欧洲电视系统所采用的一种颜色编码方法)这种数字压缩格式的图像,对于这点需求可以用‘yuv’格式来压缩这些数据:
import time
import picamera
with picamera.PiCamera() as camera:
camera.resolution = (100, 100)
camera.start_preview()
time.sleep(2)
camera.capture('image.data', 'yuv')- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
YUV具体是采用YUV420【还有YUY2、YUYV、YVYU、UYVY、AYUV、Y41P、Y411、Y211、IF09、IYUV、YV12、YVU9、YUV411等】的格式来压缩,这意味着,首先,数据的Y(亮度)值,这个值必须在全分辨率中都包含(用于计算分辨率中每一个像素的Y值),然后是U(色彩饱和度)值,亮度作用于色彩饱和度之上,最后是V(色度)值。每一个色彩与色度之上都包含四分之一的亮度。表格如下:
需要注意的是,输出到未编码格式时,摄像头需要图片的分辨率,水平分辨率上位32位的本书,垂直分辨率为16的倍数。例如,如果请求分辨率为100X100,那么实际捕获到的图像为分辨率128X112的像素数据。
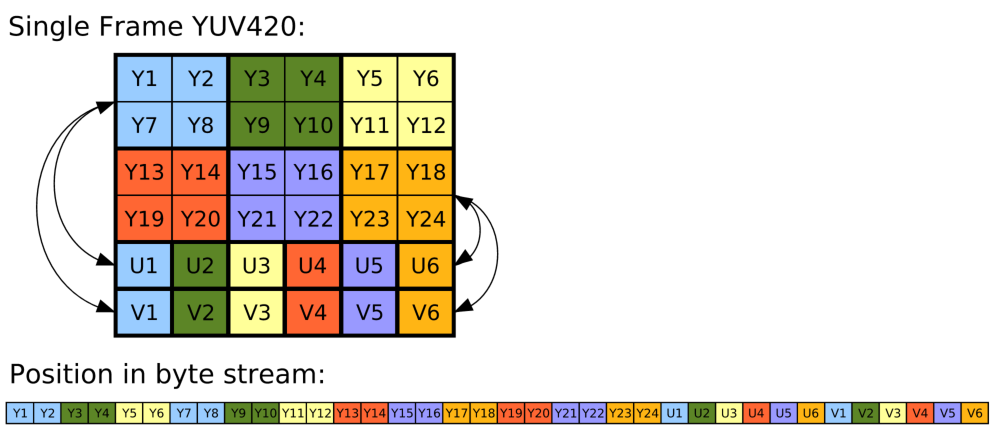
鉴于YUV420格式的每个像素都包含1.5个字节的数据(每个像素包含1个字节的Y值,每四个像素包含一个UV值),并考虑到分辨率,一个100x100的yuv图像的大小将是:
- 128.0 水平32的倍数
- 112.0 垂直16的倍数
- 1.5 1.5bytes的yuv数据(YUV比为4:2:0)
- =21504.0 bytes
前14336字节的数据为Y值,然后3584字节的数据(128x112/4)为U值,最后3584字节数据为V值。
下面这个实例演示了捕捉YUV图像数据,并将数据加载到numpy,然后将其转换为有效的RGB图像格式:
from __future__ import division
import time
import picamera
import numpy as np
width = 100
height = 100
stream = open('image.data', 'w+b')
# 捕获格式为YUV的图像
with picamera.PiCamera() as camera:
camera.resolution = (width, height)
camera.start_preview()
time.sleep(2)
camera.capture(stream, 'yuv')
# 像流指针指向开始
stream.seek(0)
# 计算实际图像的像素数
fwidth = (width + 31) // 32 * 32
fheight = (height + 15) // 16 * 16
# 然后从流中读出Y的值
Y = np.fromfile(stream, dtype=np.uint8, count=fwidth*fheight).\
reshape((fheight, fwidth))
# 最后将流中UV的值读出
U = np.fromfile(stream, dtype=np.uint8, count=(fwidth//2)*(fheight//2)).\
reshape((fheight//2, fwidth//2)).\
repeat(2, axis=0).repeat(2, axis=1)
V = np.fromfile(stream, dtype=np.uint8, count=(fwidth//2)*(fheight//2)).\
reshape((fheight//2, fwidth//2)).\
repeat(2, axis=0).repeat(2, axis=1)
# 将堆栈中的图像转换为实际的分辨率
YUV = np.dstack((Y, U, V))[:height, :width, :].astype(np.float)
YUV[:, :, 0] = YUV[:, :, 0] - 16 # Offset Y by 16
YUV[:, :, 1:] = YUV[:, :, 1:] - 128 # Offset UV by 128
# 将YUV转换成ITU-R BT.601版本(SDTV)的数据
# Y U V
M = np.array([[1.164, 0.000, 1.596], # R
[1.164, -0.392, -0.813], # G
[1.164, 2.017, 0.000]]) # B
# 最后输出RGB数据
RGB = YUV.dot(M.T).clip(0, 255).astype(np.uint8)- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
你可能注意到,在实例中我们创建文件使用了open方法,而不是io.open(),这是因为numpy的fromfile()只接受真实的文件对象。
现在这个实例已经封装在PiYUVArray类中,所以代码可以简化成:
import time
import picamera
import picamera.array
with picamera.PiCamera() as camera:
with picamera.array.PiYUVArray(camera) as stream:
camera.resolution = (100, 100)
camera.start_preview()
time.sleep(2)
camera.capture(stream, 'yuv')
# 显示YUV图像大小
print(stream.array.shape)
# 显示转换成RGB图像后文件的大小
print(stream.rgb_array.shape)- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
最后可以通过camera.capture(stream, 'rgb')来直接让摄像头输出rgb数据,来替代以上脚本。
注意,在版本1.0中的format格式“raw”现在已经变更为YUV,若使用最新的库,请将格式修改成最新版。
从1.5版以后加入了picamera.array模块
5.2、无损格式图像采集(RGB格式)
RGB格式与YUV格式现在争议比较大,不过都是相当有益的讨论。在picamera上输出RGB格式的数据非常简单,只需要跳动capture函数将捕获的图像格式设置为RGB即可。
import time
import picamera
with picamera.PiCamera() as camera:
camera.resolution = (100, 100)
camera.start_preview()
time.sleep(2)
camera.capture('image.data', 'rgb')- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
计算RGB图像数据的大小与YUV相同,首先会调整分辨率(参考YUV分辨率调整),其次,每个像素块在RGB上是占用3bytes的数据(红绿蓝三色各占1byte的数据),因此捕获一个100x100的图像,产生的数据如下:
- 128.0 水平32的倍数
- 112.0 垂直16的倍数
- 3 每个像素块占3byte的数据
- =43008.0 bytes
由此可见,RGB的数据是由红绿蓝三色的数据结合产生,其顺序为,第一个字节为红色(0,1)第二个字节为绿色(0,0)最后一个是蓝色的字节。
然后若想将RGB数据转换成Numpy的话如下:
from __future__ import division
width = 100
height = 100
stream = open('image.data', 'w+b')
# 设置捕获类型为RGB
with picamera.PiCamera() as camera:
camera.resolution = (width, height)
camera.start_preview()
time.sleep(2)
camera.capture(stream, 'rgb')
# 将指针指向数据开始
stream.seek(0)
# 计算实际的图片大小
fwidth = (width + 31) // 32 * 32
fheight = (height + 15) // 16 * 16
# 将图像读取进numpy之中
image = np.fromfile(stream, dtype=np.uint8).\
reshape((fheight, fwidth, 3))[:height, :width, :]
# 如果你希望将图像的字节浮点数控制在0到1之间,添加如下代码
image = image.astype(np.float, copy=False)
image = image / 255.0- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
现在这个实例已经被封装到pirgbarray类中,所以可以简化成如下代码:
import time
import picamera
import picamera.array
with picamera.PiCamera() as camera:
with picamera.array.PiRGBArray(camera) as stream:
camera.resolution = (100, 100)
camera.start_preview()
time.sleep(2)
camera.capture(stream, 'rgb')
# 输出rgb图像的大小
print(stream.array.shape)- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
注意,在版本1.0中的format格式“raw”现在已经变更为RGB,若使用最新的库,请将格式修改成最新版。
从1.5版以后加入了picamera.array模块。
5.3、图像的快速捕捉及快速处理
树莓派的摄像头可以快速的捕捉一组图像序列,将之解码成jpeg格式(通过设置usb_video_port参数),但是使用这个功能需要注意几点:
- 当使用video-port来捕捉图像的时候,在某些情况下,所捕捉的图像大小及清晰度可能会不如正常捕获的图片(可以参考相机模式和视频模式的区别)
- 所捕捉的图像没办法嵌入EXIF信息。
- 所捕获的图像可能会非常不清晰,噪点很大。若希望能捕获更清晰的图片,可以使用比较慢的获取方式,或者采取更先进的降噪算法。
所有的捕捉方法都支持use_video_port选项,但方法不同所捕捉图像的能力也有所不同。所以虽然capturehe和capture_continuous方法都支持use_video_prot功能,但最好使用capture_continuous来实现快速捕捉图片这个功能(因为capture_continuous不会每次都初始化解码器)。作者在测试时,这个方法最高可以支持在30fps下获取分辨率为1024x768的图片。
通常情况下,capture_continuous方法特别适合与捕获固定帧数的图像,比如下面这个例子:
import time
import picamera
with picamera.PiCamera() as camera:
camera.resolution = (1024, 768)
camera.framerate = 30
camera.start_preview()
time.sleep(2)
camera.capture_sequence([
'image1.jpg',
'image2.jpg',
'image3.jpg',
'image4.jpg',
'image5.jpg',
])- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
我们可以细化一下这个例子,可以指定一个循环序列,这样我们就没必要去手动指定每一个文件名了:
import time
import picamera
frames = 60
with picamera.PiCamera() as camera:
camera.resolution = (1024, 768)
camera.framerate = 30
camera.start_preview()
# 摄像头预热
time.sleep(2)
start = time.time()
camera.capture_sequence([
'image%02d.jpg' % i
for i in range(frames)
], use_video_port=True)
finish = time.time()
print('Captured %d frames at %.2ffps' % (
frames,
frames / (finish - start)))- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
然而,这仍然无法满足我们在一定的条件下捕捉任意帧数的图片,为此我们需要生成一个方法,通过调用方法来获取文件名:
import time
import picamera
frames = 60
def filenames():
frame = 0
while frame < frames:
yield 'image%02d.jpg' % frame
frame += 1
with picamera.PiCamera() as camera:
camera.resolution = (1024, 768)
camera.framerate = 30
camera.start_preview()
# 摄像头预热
time.sleep(2)
start = time.time()
camera.capture_sequence(filenames(), use_video_port=True)
finish = time.time()
print('Captured %d frames at %.2ffps' % (
frames,
frames / (finish - start)))- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
首先,因为树莓派的io读写速度优先,其次jpeg比H.264的效率更低(也就说图像字节,若使用h264解码来获取图片,则图片的清晰度会大大提高),所以树莓派无法支持在更高频率(比30fps更高)或更高分辨率(800x600)下快速抓取图片。
如果你打算逐帧来处理图片的话,最好是通过拍摄的视频来解码抓取视频中帧组成图片,而不是通过快速抓取的jpeg来分析图片,或者你也可以通过网络将视频或图片传输到另外的设备上来处理,然而,若你不需要快速的完成图像的处理的话,那么你尽可省去上面说的两个步骤。我们可以通过生成一个新的函数,然后通过并行线程来处理我们的图像刘,这样处理的速度和解码都大大的加快了。
import io
import time
import threading
import picamera
# 创建一个图像处理序列
done = False
lock = threading.Lock()
pool = []
class ImageProcessor(threading.Thread):
def __init__(self):
super(ImageProcessor, self).__init__()
self.stream = io.BytesIO()
self.event = threading.Event()
self.terminated = False
self.start()
def run(self):
# 这是一个单独运行的线程
global done
while not self.terminated:
# Wait for an image to be written to the stream
if self.event.wait(1):
try:
self.stream.seek(0)
# 这里去执行图片的处理过程
#done=True
finally:
# Reset the stream and event
self.stream.seek(0)
self.stream.truncate()
self.event.clear()
# 将处理完的图片加载到序列中。
with lock:
pool.append(self)
def streams():
while not done:
with lock:
if pool:
processor = pool.pop()
else:
processor = None
if processor:
yield processor.stream
processor.event.set()
else:
# 当pool序列为空是,我们等待0.1秒
time.sleep(0.1)
with picamera.PiCamera() as camera:
pool = [ImageProcessor() for i in range(4)]
camera.resolution = (640, 480)
camera.framerate = 30
camera.start_preview()
time.sleep(2)
camera.capture_sequence(streams(), use_video_port=True)
# 处理完成,释放所有处理序列
while pool:
with lock:
processor = pool.pop()
processor.terminated = True
processor.join()- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
- 56
- 57
- 58
- 59
- 60
- 61
- 62
- 63
- 64
- 65
5.4、图像的快速捕捉及转换成数据流
下面这个例子是5.5的实例的扩展,我们可以通过摄像头快速捕捉一组图像,并将之转换为网络数据流。服务器的脚本不变,客户端脚本会通过 capture_continuous()方法设置use_video_port来快速获取图片:
import io
import socket
import struct
import time
import picamera
client_socket = socket.socket()
client_socket.connect(('my_server', 8000))
connection = client_socket.makefile('wb')
try:
with picamera.PiCamera() as camera:
camera.resolution = (640, 480)
camera.framerate = 30
time.sleep(2)
start = time.time()
stream = io.BytesIO()
# 将模式设置为video-port
for foo in camera.capture_continuous(stream, 'jpeg',
use_video_port=True):
connection.write(struct.pack('<L', stream.tell()))
connection.flush()
stream.seek(0)
connection.write(stream.read())
if time.time() - start > 30:
break
stream.seek(0)
stream.truncate()
connection.write(struct.pack('<L', 0))
finally:
connection.close()
client_socket.close()- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
使用这个实例,我们将以10fps的速度获取一组640x480的图片。但是上面的脚本有些缺陷,这个例子里,是先捕捉图像然后再进行传输(虽然我们尽可能的不缓冲图片直接传输),这样导致了一些延迟,为了更加高效的同时处理图像的捕捉和传输,可以尝试下面这个示例:
import io
import socket
import struct
import time
import threading
import picamera
client_socket = socket.socket()
client_socket.connect(('spider', 8000))
connection = client_socket.makefile('wb')
try:
connection_lock = threading.Lock()
pool_lock = threading.Lock()
pool = []
class ImageStreamer(threading.Thread):
def __init__(self):
super(ImageStreamer, self).__init__()
self.stream = io.BytesIO()
self.event = threading.Event()
self.terminated = False
self.start()
def run(self):
# 这是个独立运行的线程
while not self.terminated:
# 等待图像被写入流
if self.event.wait(1):
try:
with connection_lock:
connection.write(struct.pack('<L', self.stream.tell()))
connection.flush()
self.stream.seek(0)
connection.write(self.stream.read())
finally:
self.stream.seek(0)
self.stream.truncate()
self.event.clear()
with pool_lock:
pool.append(self)
count = 0
start = time.time()
finish = time.time()
def streams():
global count, finish
while finish - start < 30:
with pool_lock:
if pool:
streamer = pool.pop()
else:
streamer = None
if streamer:
yield streamer.stream
streamer.event.set()
count += 1
else:
# 当缓存pool长度为0时,等待0.1秒
time.sleep(0.1)
finish = time.time()
with picamera.PiCamera() as camera:
pool = [ImageStreamer() for i in range(4)]
camera.resolution = (640, 480)
camera.framerate = 30
time.sleep(2)
start = time.time()
camera.capture_sequence(streams(), 'jpeg', use_video_port=True)
# 关闭流
while pool:
streamer = pool.pop()
streamer.terminated = True
streamer.join()
# 写入一个长度为0的数据包,告知服务器停止
with connection_lock:
connection.write(struct.pack('<L', 0))
finally:
connection.close()
client_socket.close()
print('Sent %d images in %d seconds at %.2ffps' % (
count, finish-start, count / (finish-start)))- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
- 56
- 57
- 58
- 59
- 60
- 61
- 62
- 63
- 64
- 65
- 66
- 67
- 68
- 69
- 70
- 71
- 72
- 73
- 74
- 75
- 76
- 77
- 78
- 79
- 80
- 81
- 82
- 83
- 84
- 85
- 86
使用相同的固件,这个脚本最高能够达到15fps的速度来获取数据流,如果使用更新的固件脚本或许能够有更快的速度。
5.5、拍摄录像同时拍摄图像
树莓派的摄像头支持在录制视频的时候,同时拍摄静态图片。但是如果在拍摄模式中尝试获取静态图像,则有可能造成视频的丢帧现象。这是因为在拍摄视频式由于中途为了拍摄静态图像需要改变模式,从而停止了获取录像而造成丢帧。
然而,如果使用use_video_prot参数从拍摄的视频中直接捕获图像的话,则拍摄的视频将不会丢帧,下面这个例子演示了在拍摄视频的同时获取静态图像:
import picamera
with picamera.PiCamera() as camera:
camera.resolution = (800, 600)
camera.start_preview()
camera.start_recording('foo.h264')
camera.wait_recording(10)
camera.capture('foo.jpg', use_video_port=True)
camera.wait_recording(10)
camera.stop_recording()- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
上面这段代码演示了,录制20秒的视频,从10秒处捕获一个静态的图像,使用了快速捕捉的参数,所以不会造成视频的丢帧,但若使用非jpeg模式或者使用更高分辨率的话,还是会引起一些丢帧的现象。
5.6、同时录制多种分辨率的视频
树莓派的摄像头支持同时使用多个视频分配器在不同的分辨率进行录制,这个需求可以支持在低分辨率下进行分析,而高分辨率同时进行存储或观看。
下面这个实例演示了利用start_recording()方法的splitter_port参数,开始两个同步线程同时录制图像,每一个图像录制使用不同的分辨率:
import picamera
with picamera.PiCamera() as camera:
camera.resolution = (1024, 768)
camera.framerate = 30
camera.start_recording('highres.h264')
camera.start_recording('lowres.h264', splitter_port=2, resize=(320, 240))
camera.wait_recording(30)
camera.stop_recording(splitter_port=2)
camera.stop_recording()- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
树莓派最多支持4个视频分配器(端口编号分为0,1,2,3),普通视频录制默认使用了1号端口分配器,而拍摄静态图像则默认使用0号分配器(use_video_port也是使用0号),同一个视频分配器不能同时进行视频的录制和静态图像的捕获,所以你应该尽量避免占用0号分配器,除非你永远不打算在拍摄视频的同时捕获静态图像。
这个功能支持1.3及以后的版本。
5.7、记录运动矢量诗句
树莓派的摄像头能够输出对运动矢量数据的预估值,可以在录制h264视频的同时将运动矢量数据计算出来并输出到文件,输出运动矢量数据可以使用start_recording方法设置motion_output参数来输出一个矢量数据文件。
import picamera
with picamera.PiCamera() as camera:
camera.resolution = (640, 480)
camera.framerate = 30
camera.start_recording('motion.h264', motion_output='motion.data')
camera.wait_recording(10)
camera.stop_recording()- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
运动数据包含在一个宏块数据,(一段MPEG视频宏表示所包含一块16x16的像素区域)并包括一个额外的数据列。因此,如果在640x480分辨率以上就会产生运动数据,数据长度为41列(640/16+1),30行(480/16)。
单个运动数据的大小为4字节,包括1字节的x矢量,1字节的y向量,和2字节的SAD(Sum of Absolute Differences绝对差值)。因此在上面这个例子中,每一帧数据将产生4920字节的运动数据(41*30*4),假设该视频包含300帧,则运动该数据总大小为1476000字节。
下面这个示例演示了加载运动数据,并将其转换为三维numpy阵列,第一维表示帧,后两维表示数据的行列。将数据机构化以后,可以比较简单的分析运动数的x,y和SAD值:
from __future__ import division
import numpy as np
width = 640
height = 480
cols = (width + 15) // 16
cols += 1 # 这里增加一个额外的列
rows = (height + 15) // 16
motion_data = np.fromfile(
'motion.data', dtype=[
('x', 'i1'),
('y', 'i1'),
('sad', 'u2'),
])
frames = motion_data.shape[0] // (cols * rows)
motion_data = motion_data.reshape((frames, rows, cols))
# 得到数据的第一帧
motion_data[0]
# 获取数据第5帧的x矢量值
motion_data[4]['x']
# 获取数据第10帧的sad值
motion_data[9]['sad']- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
得到数据的值以后,可以通过毕达哥拉斯定理来计算运动幅度。而SAD值可用于确定视频中的初始基准帧。
以下代码演示了使用从上面那个例子中得到的运动数据,然后使用PIL分析每一帧的图像,生成出一组PNG图像。
from __future__ import division
import numpy as np
from PIL import Image
width = 640
height = 480
cols = (width + 15) // 16
cols += 1
rows = (height + 15) // 16
m = np.fromfile(
'motion.data', dtype=[
('x', 'i1'),
('y', 'i1'),
('sad', 'u2'),
])
frames = m.shape[0] // (cols * rows)
m = m.reshape((frames, rows, cols))
for frame in range(frames):
data = np.sqrt(
np.square(m[frame]['x'].astype(np.float)) +
np.square(m[frame]['y'].astype(np.float))
).clip(0, 255).astype(np.uint8)
img = Image.fromarray(data)
filename = 'frame%03d.png' % frame
print('Writing %s' % filename)
img.save(filename)- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
我们可以利用picamera.array模块中的PiMotionArray类来简化上面的这个例子:
import numpy as np
import picamera
import picamera.array
from PIL import Image
with picamera.PiCamera() as camera:
with picamera.array.PiMotionArray(camera) as stream:
camera.resolution = (640, 480)
camera.framerate = 30
camera.start_recording('/dev/null', format='h264', motion_output=stream)
camera.wait_recording(10)
camera.stop_recording()
for frame in range(stream.array.shape[0]):
data = np.sqrt(
np.square(stream.array[frame]['x'].astype(np.float)) +
np.square(stream.array[frame]['y'].astype(np.float))
).clip(0, 255).astype(np.uint8)
img = Image.fromarray(data)
filename = 'frame%03d.png' % frame
print('Writing %s' % filename)
img.save(filename)- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
最后,使用下面这个例子,可以利用生成的png图像生成一个ffmpeg的动画。(从树莓派上生成这组数据将会话费大量的时间,所以若你希望能够加快分析速度,则需要将数据移植到更快的机器上来进行分析)
avconv -r 30 -i frame%03d.png -filter:v scale=640:480 -c:v libx264 motion.mp4- 1
这个功能支持1.5及以后的版本。
5.8、分割loop视频流
下面这个例子是简历在录制loop视频流的同时也在捕捉图像的安全应用上。和以前一样,用PiCameraCircularIO来让录制的视频流一直保持是最新的几秒视频。在录像的同时,通过分配器端口同时捕捉运动检测算法的程序(也就是说检测视频中有是否有运动的物体切入)。
一旦检测到有运动的物体,则将最后10秒钟的视频写入磁盘,然后录像通过运动检测算法,分割出运动部分的录像。然后循环检测运这里写代码片动,直到不再检测到运动:
import io
import random
import picamera
from PIL import Image
prior_image = None
def detect_motion(camera):
global prior_image
stream = io.BytesIO()
camera.capture(stream, format='jpeg', use_video_port=True)
stream.seek(0)
if prior_image is None:
prior_image = Image.open(stream)
return False
else:
current_image = Image.open(stream)
# 从current_image到prior_image来检测两张图片是否有运动的物体切入
# 这一部分作为练习留给读者(哈哈哈)
result = random.randint(0, 10) == 0
# 若没有检测到运动,则更新prior_image为当前秒图像
prior_image = current_image
return result
def write_video(stream):
# 同时指定一个文件为loop循环视频缓冲区,在锁定的时候我们不会写入
with io.open('before.h264', 'wb') as output:
for frame in stream.frames:
if frame.frame_type == picamera.PiVideoFrameType.sps_header:
stream.seek(frame.position)
break
while True:
buf = stream.read1()
if not buf:
break
output.write(buf)
# 指针指向头则完成loop流的擦除
stream.seek(0)
stream.truncate()
with picamera.PiCamera() as camera:
camera.resolution = (1280, 720)
stream = picamera.PiCameraCircularIO(camera, seconds=10)
camera.start_recording(stream, format='h264')
try:
while True:
camera.wait_recording(1)
if detect_motion(camera):
print('Motion detected!')
# 如果我们检测到运动的物体时锁定当前录像,并将loop流分割到after.h264文件中。
camera.split_recording('after.h264')
# 录制10秒的运动数据
write_video(stream)
# 等待运动消失时,将loop流在移回before.h264中进行录制
while detect_motion(camera):
camera.wait_recording(1)
print('Motion stopped!')
camera.split_recording(stream)
finally:
camera.stop_recording()- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
- 56
- 57
- 58
- 59
- 60
此实例还说明read1()方法用于写入录像数据是一个比较优化的方法
需要注意的是,read1()方法在读写的时候不会返回读写字节的数量。
这个功能支持1.0及以后的版本。
5.9、自定义输出
在picamera的库中,能够接受接受输出到一个文件,或输出到一个IO流中,所以简历自定义输出是非常容易的,而且在某种情况下也非常有用。比如说我们可以构造一个自定义的简单对象,只要对象包含一个write方法,并且方法接受一个简单参数,和一个flush(没有参数)方法都可以被picamera方法所调用,使之成为一个输出方法。
在自定义输出类中,write方法为自定义的输出流方法,它至少会被调用一次被用来接收picamera所抛出的每一帧动画,而无需自建一个编码器。但是需要记住的是,write中不能包含太复杂的业务逻辑,因为该方法的处理必须要迅速且有效(这个方法必须快速处理并在下一帧捕捉之前返回)。
下面这个例子定义了一个非常简单的自定义输出类,并在flush时打印输出的字节:
from __future__ import print_function
import picamera
class MyOutput(object):
def __init__(self):
self.size = 0
def write(self, s):
self.size += len(s)
def flush(self):
print('%d bytes would have been written' % self.size)
with picamera.PiCamera() as camera:
camera.resolution = (640, 480)
camera.framerate = 60
camera.start_recording(MyOutput(), format='h264')
camera.wait_recording(10)
camera.stop_recording()- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
下面这个例子演示了如何通过自定义输出类,来构造一个简单的运动检测程序。我们将捕捉的运动矢量数据作为输出对象。然后将其加载到numpy的数据阵列中进行分析。并打印到控制台来判断是否有运动的物体。由于我们并不需要实际输出到文件,所以在本实例中使用了/dev/null/作为保存的路径:
rom __future__ import division
import picamera
import numpy as np
motion_dtype = np.dtype([
('x', 'i1'),
('y', 'i1'),
('sad', 'u2'),
])
class MyMotionDetector(object):
def __init__(self, camera):
width, height = camera.resolution
self.cols = (width + 15) // 16
self.cols += 1 # 加入一个额外的列
self.rows = (height + 15) // 16
def write(self, s):
# 将运动数据加载到numpy阵列中
data = np.fromstring(s, dtype=motion_dtype)
# 计算每个向量的数据
data = data.reshape((self.rows, self.cols))
data = np.sqrt(
np.square(data['x'].astype(np.float)) +
np.square(data['y'].astype(np.float))
).clip(0, 255).astype(np.uint8)
# 如果运动幅度超过10向量或幅度更大,且总体大于60次,则证明我们捕捉到了运动中的物体。
if (data > 60).sum() > 10:
print('Motion detected!')
# 返回字节数
return len(s)
with picamera.PiCamera() as camera:
camera.resolution = (640, 480)
camera.framerate = 30
camera.start_recording(
# 抛弃掉视频数据,但保证我们的格式为h264
'/dev/null', format='h264',
# Record motion data to our custom output object
motion_output=MyMotionDetector(camera)
)
camera.wait_recording(30)
camera.stop_recording()- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
然后我们也可以利用picamera.array中的PiMotionAnalysis类来简化上面的代码:
import picamera
import picamera.array
import numpy as np
class MyMotionDetector(picamera.array.PiMotionAnalysis):
def analyse(self, a):
a = np.sqrt(
np.square(a['x'].astype(np.float)) +
np.square(a['y'].astype(np.float))
).clip(0, 255).astype(np.uint8)
# 如果运动幅度超过10向量或幅度更大,且总体大于60次,则证明我们捕捉到了运动中的物体。
# than 60, then say we've detected motion
if (a > 60).sum() > 10:
print('Motion detected!')
with picamera.PiCamera() as camera:
camera.resolution = (640, 480)
camera.framerate = 30
camera.start_recording(
'/dev/null', format='h264',
motion_output=MyMotionDetector(camera)
)
camera.wait_recording(30)
camera.stop_recording()- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
这个功能支持1.5及以后的版本。
5.10、自定义解码器
picamera支持开发者重写或者扩展图像或视频的解码器类,这样在视频的采集解码中可以直接运行您的代码进行解码。
但不同于自定义输出,自定义解码器是相当复杂的,在大多数情况下,我们还是建议使用默认的解码器,因为自定义解码器几乎没有什么好处,可能唯一的好处就是能更改自定义输出时无法更改的缓冲区head(说实话我也没怎么搞懂。。。)。
import picamera
import picamera.mmal as mmal
# 重写PiVideoEncoder类
class MyEncoder(picamera.PiCookedVideoEncoder):
def start(self, output, motion_output=None):
self.parent.i_frames = 0
self.parent.p_frames = 0
super(MyEncoder, self).start(output, motion_output)
def _callback_write(self, buf):
# Only count when buffer indicates it's the end of a frame, and
# it's not an SPS/PPS header (..._CONFIG)
if (
(buf[0].flags & mmal.MMAL_BUFFER_HEADER_FLAG_FRAME_END) and
not (buf[0].flags & mmal.MMAL_BUFFER_HEADER_FLAG_CONFIG)
):
if buf[0].flags & mmal.MMAL_BUFFER_HEADER_FLAG_KEYFRAME:
self.parent.i_frames += 1
else:
self.parent.p_frames += 1
# Remember to return the result of the parent method!
return super(MyEncoder, self)._callback_write(buf)
# Override PiCamera to use our custom encoder for video recording
class MyCamera(picamera.PiCamera):
def __init__(self):
super(MyCamera, self).__init__()
self.i_frames = 0
self.p_frames = 0
def _get_video_encoder(
self, camera_port, output_port, format, resize, **options):
return MyEncoder(
self, camera_port, output_port, format, resize, **options)
with MyCamera() as camera:
camera.start_recording('foo.h264')
camera.wait_recording(10)
camera.stop_recording()
print('Recording contains %d I-frames and %d P-frames' % (
camera.i_frames, camera.p_frames))- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
5.11、Raw Bayer 数据捕获
以下文档对我来说太复杂,暂时没搞定怎么翻译。。
5.12、摄像头闪光灯的调用
一些树莓派的摄像头模块支持在拍摄时调用LED闪光灯进行场景补光。对于LED灯可以自行配置GPRO的引脚。
树莓派摄像头有两个可操作的led灯
- 一个用于驱动LED闪光灯
- 一个用于标识隐私拍摄的led红灯,在拍照时标识该摄像头被启用。
这些引脚可以通过videoCore设备列表进行查看,首选在使用led灯之前需要安装设备支持的库:
$ sudo apt-get install device-tree-compiler
$ wget http://www.raspberrypi.org/documentation/configuration/images/dt-blob.dts- 1
- 2
树莓派支持的设备与树莓派的版本有关,若想支持摄像头,可以参照下面的表格对应自己的树莓派版本进行修改。
| 树莓派类型 | 目录 |
|---|---|
| Raspberry Pi Model B revision 1 | /videocore/pins_rev1 |
| Raspberry Pi Model A | /videocore/pins_rev2 |
| Raspberry Pi Model B revision 2 | /videocore/pins_rev2 |
| Raspberry Pi Model A+ | /videocore/pins_bplus |
| Raspberry Pi Model B+ | /videocore/pins_bplus |
| Raspberry Pi 2 Model B | /videocore/pins_bplus |
根据不同的树莓派类型,你会发现需要修改pin_config和pin_defines,根据pin_config部分,你需要配置led闪光灯的GPIO针脚,然后在pin_defines关联这些针脚与FLASH_0_ENABLE和FLASH_0_INDICATOR进行关联,来控制摄像头的开启与关闭。
例如,我们配置GPIO17作为闪光灯的针脚。那么我们在树莓派2B+对应的配置文件/videocore/pins_bplus中需要添加如下部分。
pin@p17 { function = "output"; termination = "pull_down"; };- 1
GPIO针脚的定义根据树莓派博通芯片针脚定义进行安装,并在/videocore/pins_rev2/pin_defines中定义出GPIO17为闪光灯pin:
pin-define@FLASH_0_ENABLE {
type = "internal";
number = <17>;
};- 1
- 2
- 3
- 4
然后我们需要更新设备,并将我们的配置文件编译成二进制数据写入固件中,参考以下命令行:
dtc -I dts -O dtb dt-blob.dts -o dt-blob.bin- 1
命令行参数解释如下:
- dtc - 执行编译命令
- -I dts -通过输入文件来编译设备列表
- -O dtb -输出二进制文件格式
- dt-blob.dts -将之设定为默认设备列表文件
- -o dt-blob.bin -输出的文件
执行完以后命令行会输出一下内容:
DTC: dts->dtb on file "dt-blob.dts"- 1
但是,如果使用的是NOOBS安装包来安装树莓派的话,需要进行分区恢复,代码如下:
$ sudo mkdir /mnt/recovery
$ sudo mount /dev/mmcblk0p1 /mnt/recovery
$ sudo cp dt-blob.bin /mnt/recovery
$ sudo umount /mnt/recovery
$ sudo rmdir /mnt/recovery- 1
- 2
- 3
- 4
- 5
需要注意的是,设备列表的放置位置和文件名都是固定的,不能自定义也不能写错,二进制文件必须被命名为 dt-blob.bin(全部小写),并必须将其放在boot分区的根目录下。
以上就设置完闪光灯的一系列要求,然后就可以在picamera中开启闪光灯参数了。
import picamera
with picamera.PiCamera() as camera:
camera.flash_mode = 'on'
camera.capture('foo.jpg')- 1
- 2
- 3
- 4
- 5
你也可以不是用GPIO闪光灯,而使用模块自带的led闪光灯。这不需要任何的硬件改动,虽然禁止了pin_define下设置led灯的驱动(
相机的LED脚已被定义为使用下拉终止),但你需要设置CAMERA_0_LED和CAMERA_0_LED的参数来手动启动led灯。
pin_define@CAMERA_0_LED {
type = "internal";
number = <5>;
};
pin_define@FLASH_0_ENABLE {
type = "absent";
};- 1
- 2
- 3
- 4
- 5
- 6
- 7
修改成
pin_define@CAMERA_0_LED {
type = "absent";
};
pin_define@FLASH_0_ENABLE {
type = "internal";
number = <5>;
};(转自:https://blog.csdn.net/talkxin/article/details/50511508)