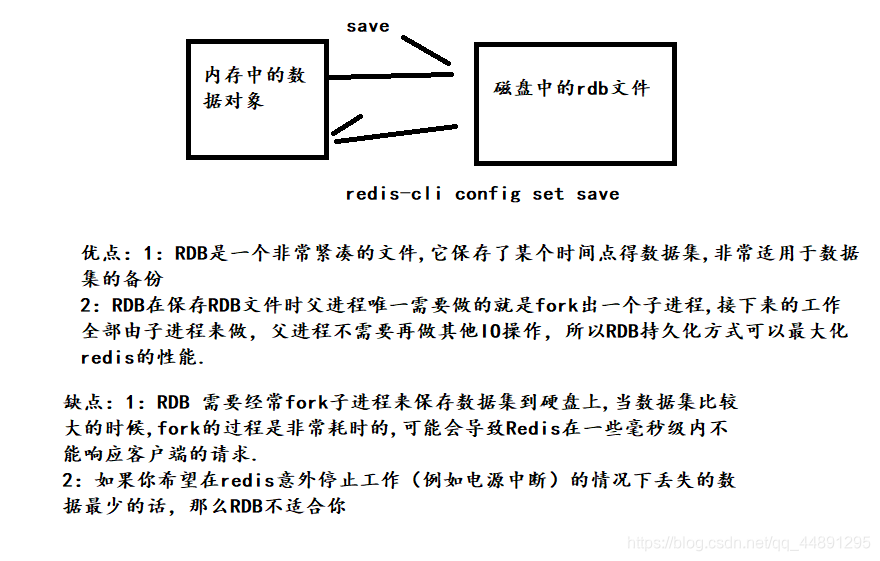
1:RDB介绍
- 在指定的时间间隔内将内存中的数据集快照写入磁盘也就是行话讲的Snapshot快照,它恢复时是将快照文件直接读到内存里
Redis会单独创建(fork) 一个子进程来进行持久化,会先将数据写入到一个临时文件中,待持久化过程都结束了,再用这个临时文件替换上次持久化好的文件。 整个过程中,主进程是不进行任何I0操作的,这就确保了极高的性能
如果需要进行大规模数据的恢复,且对于数据恢复的完整性不是非常敏感,那RDB方式要比AOF方式更加的高效。RDB的缺点是最后一次持久化后的数据可能丢失。
- Fork介绍
Fork的作用是复制一个与当前进程一样的进程。新进程的所有数据(变量、环境变量、程序计数器等)都数值都和原进程一致,但是是一个全新的进程,并作为原进程的子进程
2:持久化过程介绍
首先我们看一眼redis.conf文件中快照的配置位置中的save有关信息,如下是redis.conf配置文件的有关快照的部分截取信息

注释的主要意思是:如果给定的秒数和给定的对数据库的写操作数同时发生,则会保存数据库。在下面的例子中,行为将是保存:在900秒(15分钟)后,如果至少1个键被改变。在120秒(2分钟)后,如果至少5个键改变。.。。注意:我们可以通过注释掉所有“保存”行来完全禁用保存,也可以删除所有以前配置的保存点,通过添加一个保存指令与一个空字符串参数,就像下面的例子:保存save " "

举例:我们创建11个键,然后进行破坏(flushall),然后复制dump.rdb文件,然后分析这一个过程是否可以找到以前创建的键
老铁们啥都不说了,我对你们的感情都在图里
1:创建set数据类型以前,20.01分存在dump.rdb文件

2:创建11个键的数据,来观察dump.rdb文件是否发生变化?

3:dumb.rdb文件从20.01变成了20.03,说明发生了变化,大小也变了,说明给定的秒数(120)和给定的对数据库的写操作数(5)同时发生,则会保存数据库,覆盖了以前的dumb.rdb(20.01)文件

4:这时我们进行数据库备份,生成了dumpco.drb备份文件
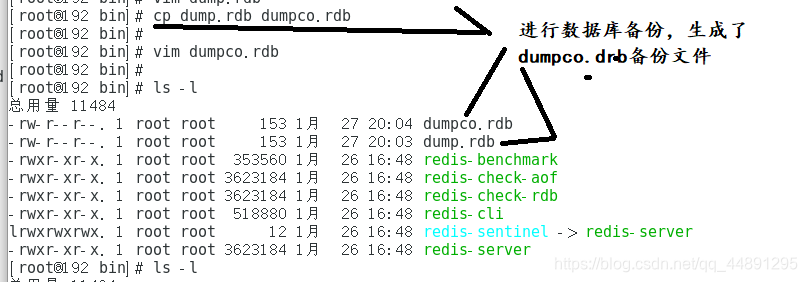
5:我们执行flushall操作,并关闭redis,观察是否dump.drb文件发生变化

6:dump.drb文件发生变化:理由时间从20.03更新到20.05,说明:flushall,shutdown都会斩断内存所有情况,形成dump.rdb文件(覆盖了以前的文件)

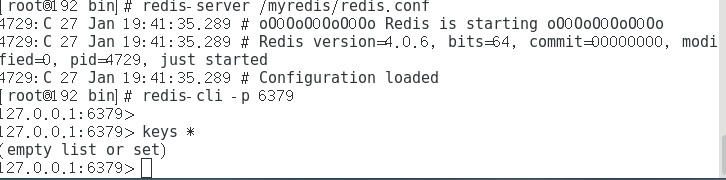
7:重新启动redis,观察是否还存在键?结果发现不存在键,理由:
flushall,shutdown斩断内存所有情况,形成dump.rdb文件(覆盖了20.03分的有存储数据的dump.rdb文件),此文件中已经为空了,已经被全清空了,所以不存在键
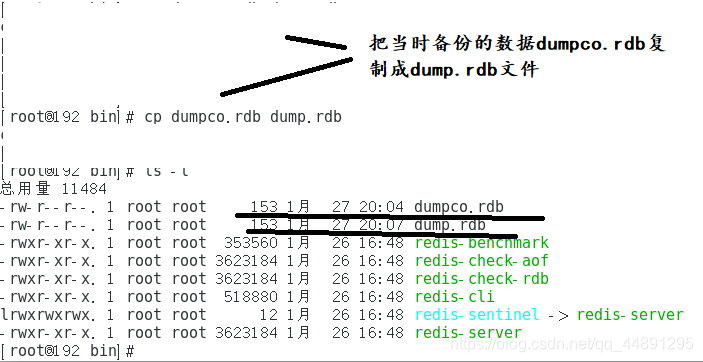
8:把当时备份的数据dumpco.rdb复制成dump.rdb文件,在重新打开redis,观察是否有键?结果:有
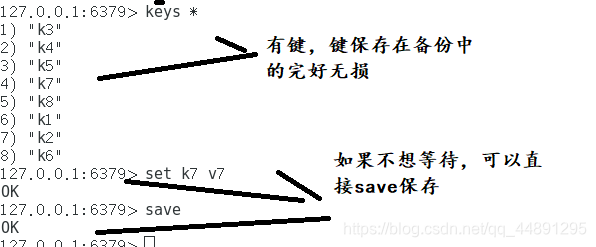
总结:
1:flushall,shutdown斩断内存所有情况,形成dump.rdb文件(覆盖以前文件)
2:redis会将数据写入到一个临时文件中,待持久化过程都结束了,再用这个临时文件替换上次持久化好的文件(这过程跟redis.conf的快照配置信息中的save有关)
3:优缺点
老铁们啥都不说了,我对你们的感情都在图里