文章目录
前言:
生产环境现场报过来一个现象:
16节点环境,一共5个mon,但凡起mon服务的节点,系统卡消耗寿命均在60%以上,所以os组以及测试部一口咬定是我们ceph mon引起的问题,通过查看mon数据库内容,数据库记录内容虽然多,但是要说mon能每秒2M的速度写数据库,感觉十分不合理。最后发现mon数据库频繁发生compaction,并且compaction的时候存在如下几种写盘场景:
1、rocksdb的memtable写系统卡之前,会先先写个log,防止意外发生掉电导致数据丢失。
2、memtable到leveldb0的写入过程
3、sst表文件每次compaction的时候会重新被写入(大头应该是这里、sst文件最大情况下可能好几G,这样每次compaction,重写一遍,后果可想而知了)
后面要了一下现场ceph日志,主要排查了一下mon compaction情况,发现如下两种情况:
1、生产环境有一个节点挂了,6小时后被发现,恢复了环境,这六个小时mon compaction次数为1002次
2、环境恢复后,八小时内,mon compaction次数为298次
从这里可以分析到,异常情况下mon数据库写入速度会加快,后面发现主要还是当ceph存在异常的时候,ceph 的健康检测机制会非常频繁的检测集群环境,而检测过程中还是内部通过调用命令来实现的,mon数据库又恰好会记录·每次执行的命令。这样导致异常情况下,数据库容易被触发compaction。
分析到这里,看来必须要调研一下rocksdb了。
介绍一下rocksdb的三种compaction机制
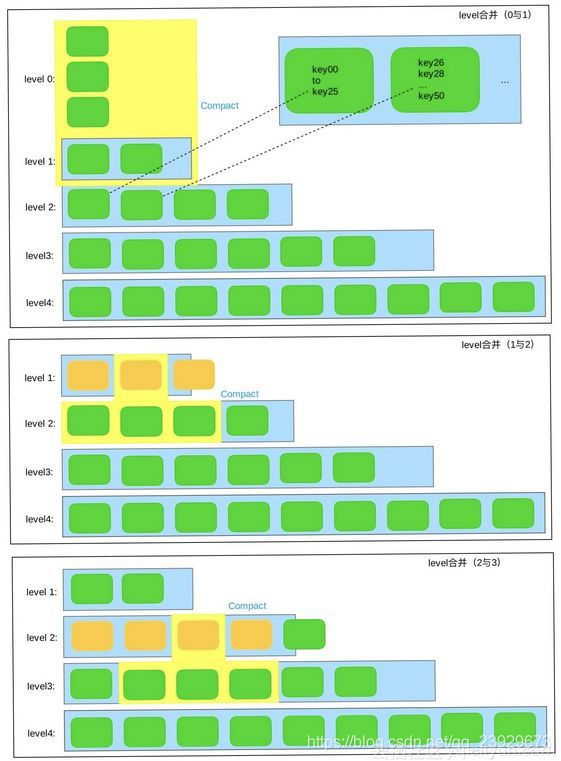
1、Leveled Compaction
策略
对于level0,触发条件是sst文件个数,通过参数level0_file_num_compaction_trigger控制,score通过sst文件数目与level0_file_num_compaction_trigger的比值得到。
Level1-levelN触发条件是sst文件的大小,通过参数max_bytes_for_level_base和max_bytes_for_level_multiplier来控制每一层最大的容量
优缺点
写放大高,读放大小,空间放大小
2、Universal compaction
策略
1.如果空间放大超过一定的比例,则所有sst进行一次compaction,所谓的full compaction,通过参数max_size_amplification_percent控制。
2.如果前size(R1)小于size(R2)在一定比例,默认1%,则与R1与R2一起进行compaction,如果(R1+R2)*(100+ratio)%100<R3,则将R3也加入到compaction任务中,依次顺序加入sst文件
3.如果第1和第2种情况都没有compaction,则强制选择前N个文件进行合并。
优缺点
写放大小,但是读放大高,空间放大高

FIFO compaction
策略
FIFO顾名思义就是先进先出,这种模式周期性地删除旧数据。在FIFO模式下,所有文件都在level0,当sst文件总大小超过阀值max_table_files_size,则删除最老的sst文件,这套机制非常适合于存储时序数据
rocksdb写数据库
策略
首先,任何的写入都会先写到 WAL,然后在写入 Memory Table(Memtable)。当然为了性能,也可以不写入 WAL,但这样就可能面临崩溃丢失数据的风险。Memory Table 通常是一个能支持并发写入的 skiplist,但 RocksDB 同样也支持多种不同的 skiplist,用户可以根据实际的业务场景进行选择。
当一个 Memtable 写满了之后,就会变成 immutable 的 Memtable,RocksDB 在后台会通过一个 flush 线程将这个 Memtable flush 到磁盘,生成一个 Sorted String Table(SST) 文件,放在 Level 0 层。当 Level 0 层的 SST 文件个数超过阈值之后,就会通过 Compaction 策略将其放到 Level 1 层,以此类推。

总结rocksdb配置参数

关于放大问题
读放大:
譬如用户要读取一个 page,但实际下面读取了 3 个 pages,读放大就是 3。
写放大:
WA = data writeen to disc / data written to database,譬如用户写入了 10 字节,但实际写到磁盘的有 100 字节,写放大就是 10。
空间放大:
SA = size of database files / size of databases used on disk,数据库可能是 100 MB,但实际占用了 200 MB 的空间,空间放大就是 2。
总结
经过上面对rocksdb的分析,发现每次compaction并没有达到系统默认的设置值。既然rocksdb自身没有触发compaction,那它频繁的compaction到底什么原因呢?转念一想,肯定是mon自身触发的。看来又得去研究研究ceph mon触发compaction机制了,见下一篇博文。(rocksdb水还是比较深的,了解到现在只是皮毛,后续继续更新)
参考文档
https://my.oschina.net/u/2000675/blog/1923390
https://www.jianshu.com/p/99cc0df8ed21
https://www.jianshu.com/p/0fdeed70b36a
https://www.jianshu.com/p/8fb8f2458253
https://www.jianshu.com/p/0d4bea498a91
https://blog.csdn.net/zerooffdate/article/details/89458362
https://blog.csdn.net/weixin_36145588/article/details/78539203
https://www.cnblogs.com/cchust/p/6007486.html
