原文:https://yq.aliyun.com/articles/54413
前情概要
对于线上高并发、高吞吐的Java web服务来说,长时间的GC暂停(也叫 stop- the-world)会严重影响系统吞吐、稳定性和用户体验。下文是我们的一个真实线上web系统针对GC调优过程的一个总结。这个系统在调优前,经常会反映有超秒的GC暂停问题,这种GC问题可能会导致调用方(可能是上层服务调用方、负载均衡层或客户端)阻塞、超时、甚至雪崩的情况。我们在系统资源不变的情况下,经过多轮调优,大幅降低了GC的频率和暂停时间。
前期准备
1、统计应用数据(峰值TPS、平均TPS,每秒平均分配内存大小、每个请求的平均分配内存大小)
2、统计GC分配、回收内存的数据(MinorGC、FullGC停顿时长,平均多长时间触发一次GC,每次Eden->Old的平均晋升大小等)
3、搭建压力测试环境
4、模拟线上真实用户行为及相应压力(记录用户访问的accesslog作为压力测试源,使用的压力测试软件为http_load和httperf)
第一轮调优
1、 尝试使用JDK7的G1回收,在安装JDK7时失败,原因是操作系统版本必须是RedHat5.5+/CentOS5.5+ 暂时不准备升级操作系统,所以放弃JDK7 G1;
2、改为使用JDK6 Update26版本的G1回收。设置最大回收时间为40ms,通过12小时的观察,发现有大量超时,感觉G1在JDK6上还不够成熟,所以决定暂时放弃G1,改为ParallelGC;
3、使用ParallelGC后,压力测试发现每次MinorGC的耗时降低到40ms左右(以前是200ms以上),但每隔3小时就会有一次FullGC发生,每次FullGC耗时3~4秒;
4、由于FullGC造成的应用暂停在这个应用中是不能接受的。所以放弃ParallelGC,改为使用CMSGC。
第二轮调优
1、观察 gcutil 发现PermSpace接近100%,调大PermSize 和 MaxPermSize;
2、调整-Xms和-Xmx相等(如果Xms小于Xmx,则应用启动初期老生代相对较小,会导致CMS GC更加频繁);
3、尝试优化每次ParNew的时长(优化前每次在200ms以上):
增加“-XX:+PrintTenuringDistribution”参数观察gc.log,发现对象在SurvivorSpace中的age过多,会导致大量老对象在新生代无法晋升到老生代。而JVM在ParNewGC时分析这些老对象的引用关系是非常耗时的。观察MaxTenuringThresh-old 和 TargetSurvivorRatio 设置的过大,所以将 MaxTenuringThreshold 值调小为15即达到优化目的(优化后每次ParNew在20~40ms之间)。并且为了提高SurvivorSpace的利用率,将TargetSurvivorRatio设置为100(代表强制GC关闭动态调整MaxTenuringThreshold,这个参数设置为100会略为激进,增加了Survivor区使用率的同时,降低了Survivor区应对突发流量的承载能力,不同应用可以看情况调整)。
4、尝试优化ParNew之间的间隔时间(优化前3~4秒一次):观察gc.log发现每次ParNew后大约有不到780MB的存留对象,希望这些对象尽量活在SurvivorSpace里,并且同时又要保证ParNew的时间间隔,所以在Xmx和SurvivorRatio不变的情况下,将Xmn扩大到7800MB。(因为SurvivorRatio=8,所以整个EdenSpace需要780*10=7800MB)
5、再次观察优化后的GC情况(gcutil),发现由于大量对象都在EdenSpace消亡,所以OldGen的晋升比率极低(0.01%~0.02%),所以可以考虑增大CMSInitiatingOccupancyFraction以提高OldGen的利用率,降低CMS GC的触发频率(增大到80%)。
6、去掉CMSFullGCsBeforeCompaction(去掉后默认为0,表示每次FullGC后都会进行压缩碎片整理)。因为CMS GC导致的内存碎片必须清除,否则OldGen的利用率会降低。
第三轮调优
运营一段时间后,发现CMSGC超过一秒的情况非常多(图中箭头指向): 
GC日志:
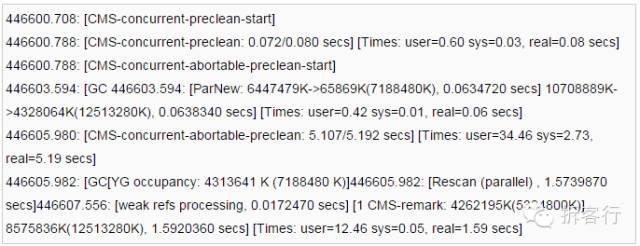
可以看出,在remark中的Rescan阶段耗费了1.57秒,并且这个过程是会导致应用暂停的。问题定位在了Rescan阶段。
发现在Rescan时新生代过大(4313641 K(7188480 K)),是导致Rescan慢的关键原因,如果能尽量保持新生代很小的时候就终止preclean阶段,就可以控制住在Rescan时新生代的大小。查看JVM参数发现-XX:CMSScheduleRemarkEdenPenetration的意思是当新生代存活对象占EdenSpace的比例超过多少时,终止preclean阶段并进入remark阶段。这个参数的默认值是50%,按照现在的配置,就是7800m*50%=3900m左右,所以更改此参数设置为: -XX:CMSScheduleRemarkEdenPenetration=1
进行压力测试,发现remark阶段的耗时确实降低了不少,说明优化有效。
第四轮调优
运行几天后观察GC日志(2011-09-05),发现每隔100000秒的CMSGC的峰值情况确实大大降低了,但是还是偶尔有超过1~2秒的CMSGC情况: 
GC日志:

发现concurrent-abortable-preclean阶段超过了-XX:CMSMaxAbortablePrecleanTime 设置的最大值10秒,所以强制终止了preclean阶段而进入remark阶段。而这段时间的两次ParNew之间的间隔了17秒之多。希望的是在preclean阶段产生一次MinorGC,所以将preclean的最大时长调整为30秒: -XX:CMSMaxAbortablePrecleanTime=30000
第五轮调优
运行一段时间后,发现居然出现了FullGC,大概在3~5天左右出现一次,以下是FullGC时的日志: 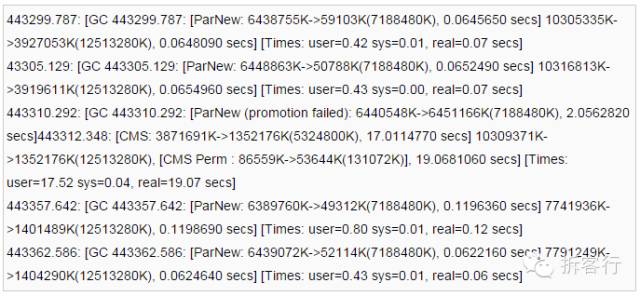
发现在443310秒有promotion failed出现(新生代晋升到老生代空间不足导致的FullGC),但是此时的OldGen可以算出还剩1.45G的空间(5324800K-3871691K=1453109K),而根据gcLogViewer的统计,每次MinorGC后平均新生代晋升到老生代的内存大小仅为58K。所以并不是OldGen空间不够,而是OldGen的连续空间不够造成的promotion failed。
换句话说,是由于OldGen在距离上次CMSGC后,又产生了大量内存碎片,当某个时间点在OldGen中的连续空间没有一块足够58K的话,就会导致的promotion failed。以下是Sun针对这个问题的说明:
引用
Sometimes we see these promotion failures even when thelogs show that there is enough free space in tenured generation. The reason is'fragmentation' - the free space available in tenured generation is notcontiguous, and promotions from young generation require a contiguous freeblock to be available in tenured generation. CMS collector is a non-compactingcollector, so can cause fragmentation of space for some type of applications.In his blog, Jon talks in detail on how to deal with this fragmentationproblem: 链接
或者参考我的另一篇blog:链接
考虑如果能够缩短CMSGC的周期,保证在出现promotion failed之前就进行CMSGC,就可以避免这个问题了。所以考虑将新生代空间缩小(相对来说就增加了老生代的空间),并且将CMSGC触发比率降低,同时保证Survivor空间不变。所以优化参数改动如下:
引用
<span style="color:#f8f8f2"><code class="language-none">-Xmn7800m -> -Xmn7020m
-XX:SurvivorRatio=8 –> -XX:SurvivorRatio=7
-XX:CMSInitiatingOccupancyFraction=80 ->
-XX:CMSInitiatingOccupancyFractio=70 </code></span>第六轮调优
上面的调优保持系统稳定运行了很长时间后,突然有一台机器出现大量FullGC,观察gc.log发现是由于持久带满造成的:
![]()
应对的方法为加大持久带,并让持久带也使用CMSGC方式回收:
引用
修改:
<span style="color:#f8f8f2"><code class="language-none">-XX:PermSize=64m -> -XX:PermSize=200m
-XX:MaxPermSize=128m -> -XX:MaxPermSize=200m </code></span>增加:
<span style="color:#f8f8f2"><code class="language-none">-XX:+CMSClassUnloadingEnabled</code></span>
另外,对于持久带满的观测方法,可以参考Rednaxelafx给我的回答: 链接
总结
精细化的GC调优是需要耐心和时间的,往往一轮调优要经过GC数据集、分析、调整参数、压力测试、灰度发布、最终上线这几步,上线一段时间后,通过监控发现有新的GC问题,可能又会需要再一轮的调优。而且系统版本的迭代、对象生命周期的变化、线上流量和服务依赖的变化,都可能会对GC频率和时间有影响。所以对于线上的重点项目,建议每次大版本上线前都能建立一个GC监控、收集和调优的意识,最大程度上规避GC对系统带来的风险。
优化后整体参数
<span style="color:#f8f8f2"><code class="language-none"><jvm-arg>-Xmx13000m</jvm-arg>
<jvm-arg>-Xms13000m</jvm-arg>
<jvm-arg>-Xmn7020m</jvm-arg>
<jvm-arg>-Xss256k</jvm-arg>
<jvm-arg>-XX:PermSize=200m</jvm-arg>
<jvm-arg>-XX:MaxPermSize=200m</jvm-arg>
<jvm-arg>-XX:ParallelGCThreads=20</jvm-arg>
<jvm-arg>-XX:+UseConcMarkSweepGC</jvm-arg>
<jvm-arg>-XX:+UseParNewGC</jvm-arg>
<jvm-arg>-XX:SurvivorRatio=7</jvm-arg>
<jvm-arg>-XX:TargetSurvivorRatio=100</jvm-arg>
<jvm-arg>-XX:MaxTenuringThreshold=15</jvm-arg>
<jvm-arg>-XX:CMSInitiatingOccupancyFraction=70</jvm-arg>
<jvm-arg>-XX:SoftRefLRUPolicyMSPerMB=0</jvm-arg>
<jvm-arg>-XX:+UseCMSCompactAtFullCollection</jvm-arg>
<jvm-arg>-XX:CMSMaxAbortablePrecleanTime=30000</jvm-arg>
<jvm-arg>-XX:CMSScheduleRemarkEdenPenetration=1</jvm-arg>
<jvm-arg>-XX:+CMSClassUnloadingEnabled</jvm-arg>
<jvm-arg>-server</jvm-arg>
<jvm-arg>-XX:+PrintGCDetails</jvm-arg>
<jvm-arg>-XX:+PrintGCDateStamps</jvm-arg>
<jvm-arg>-Xloggc:./log/gc.log</jvm-arg> </code></span>