整体架构
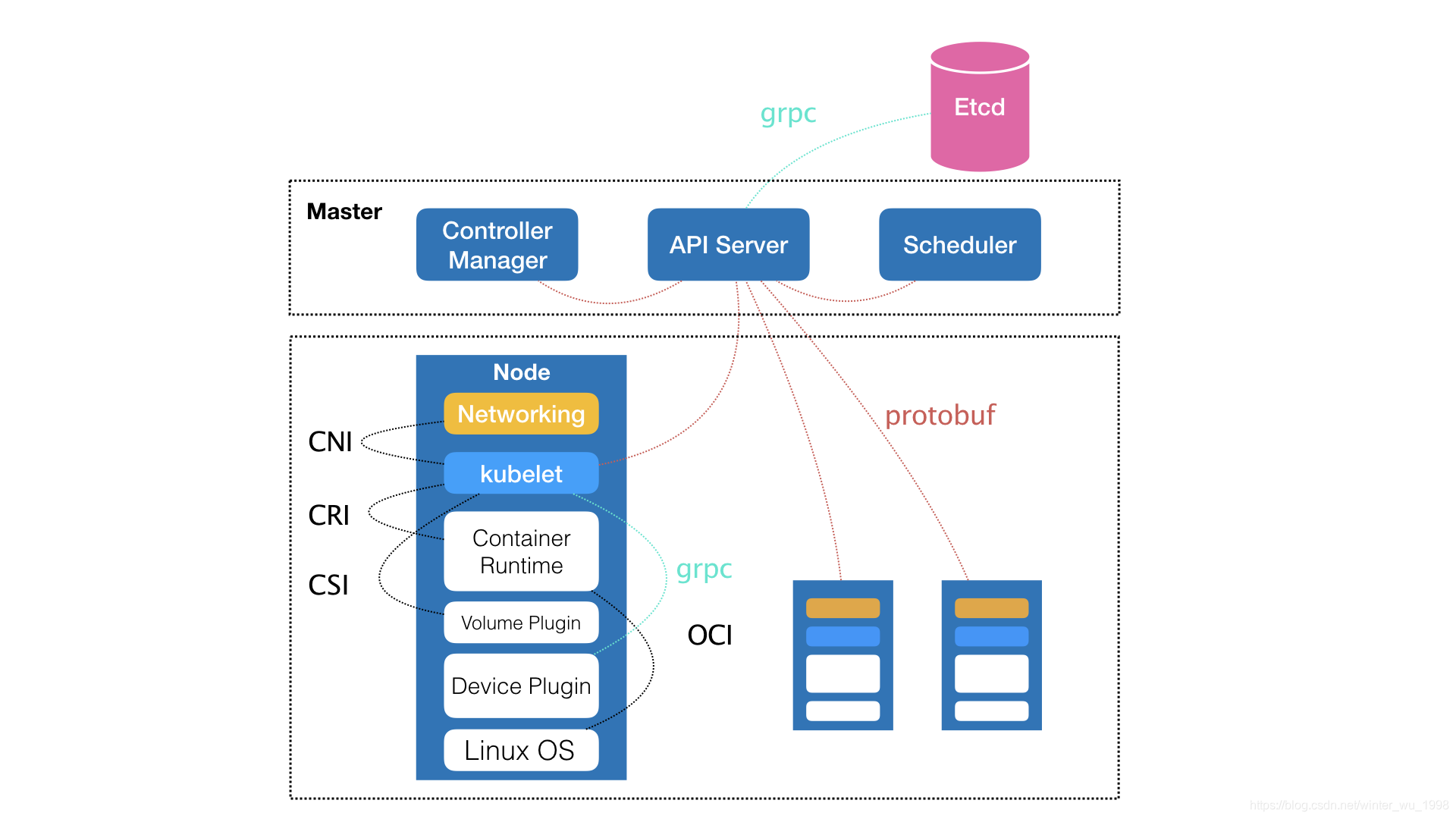
- k8s核心元件
- etcd 保存了整个集群的状态;
- apiserver 提供了资源操作的唯一入口,并提供认证、授权、访问控制、API注册和发现等机制;
- controller manager 负责维护集群的状态,比如故障检测、自动扩展、滚动更新等;
- scheduler 负责资源的调度,按照预定的调度策略将Pod调度到相应的机器上;
- kubelet 负责维护容器的生命周期,同时也负责Volume(CVI)和网络(CNI)的管理;
- Container runtime 负责镜像管理以及Pod和容器的真正运行(CRI);
- kube-proxy 负责为Service提供cluster内部的服务发现和负载均衡;
pod
- 在一个真正的操作系统里,进程并不是“孤苦伶仃”地独自运行的,而是以进程组的方式,“有原则地”组织在一起
- 例如 rsyslogd 的程序,它负责的是 Linux 操作系统里的日志处理。syslogd 的主程序 main,和它要用到的内核日志模块 imklog 等,同属于 1632 进程组。这些进程相互协作,共同完成 rsyslogd 程序的职责。
- 在思考是否要把服务放到一个pod中时,需要仔细考虑如果它们位于不同的机器上,是否能够正常工作
- 比如一个wordpress和一个mysql不应该放到同一个pod中
- wordpress是无状态的,可以通过扩展它来相应更多负载,而我们不希望此时也会同时扩展mysql
- 并且两个服务可以利用网络通信,不一定需要位于同一机器
- 比如一个wordpress和一个mysql不应该放到同一个pod中
- Pod内的容器共享当前Pod的文件系统和网络
- 这些容器之所以能够共享,是因为Pod中有一个Pause的根容器,其余的业务容器都是共享这个根容器的IP和Volume。所以这些容器之间都可以通过localhost进行通信
- 为什么要引入根容器这个概念?
- 因为如果没有根容器的话,当一个Pod中引入了多个容器的时候,我们应该用哪一个容器的状态来判断Pod的状态呢?所以才要引入与业务无关且不容易挂掉的Pause容器作为根容器,用根容器的状态来代表整个容器的状态
- Kubernetes 采用的是基于扁平地址空间的网络模型
- 集群中的每个 Pod 都有自己的 IP 地址,Pod 之间不需要配置 NAT 就能直接通信
- 同一个 Pod 中的容器共享 Pod 的 IP,能够通过 localhost 通信
Service
- 一旦Service被创建,K8S会为其分配一个集群内唯一的IP,叫做ClusterIP
- 在Service的整个生命周期中,ClusterIP不会发生变更
- 这样一来,就可以建立一个ClusterIP到服务名的DNS域名映射即可
- ClusterIP是一个虚拟的IP地址,无法被Ping,仅仅只限于在K8S的集群内使用
- Service对客户端,屏蔽了底层Pod的寻址的过程。并且由kube-proxy进程将对Service的请求转发到具体的Pod上,具体到哪一个,由具体的调度算法决定。这样以来,就实现了负载均衡
- 外网访问service需要声明NodePort或者loadbalancer
Deployment
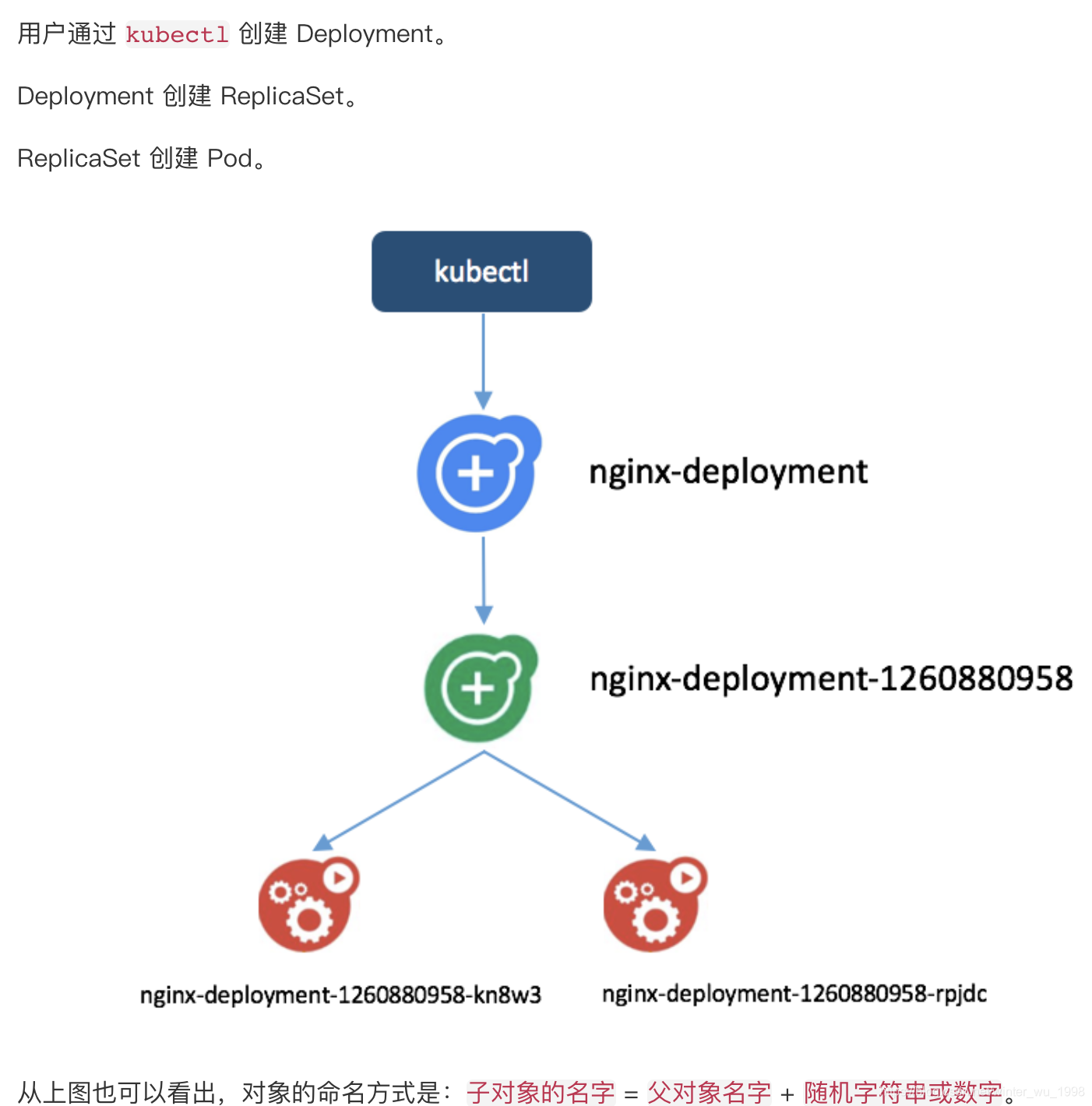
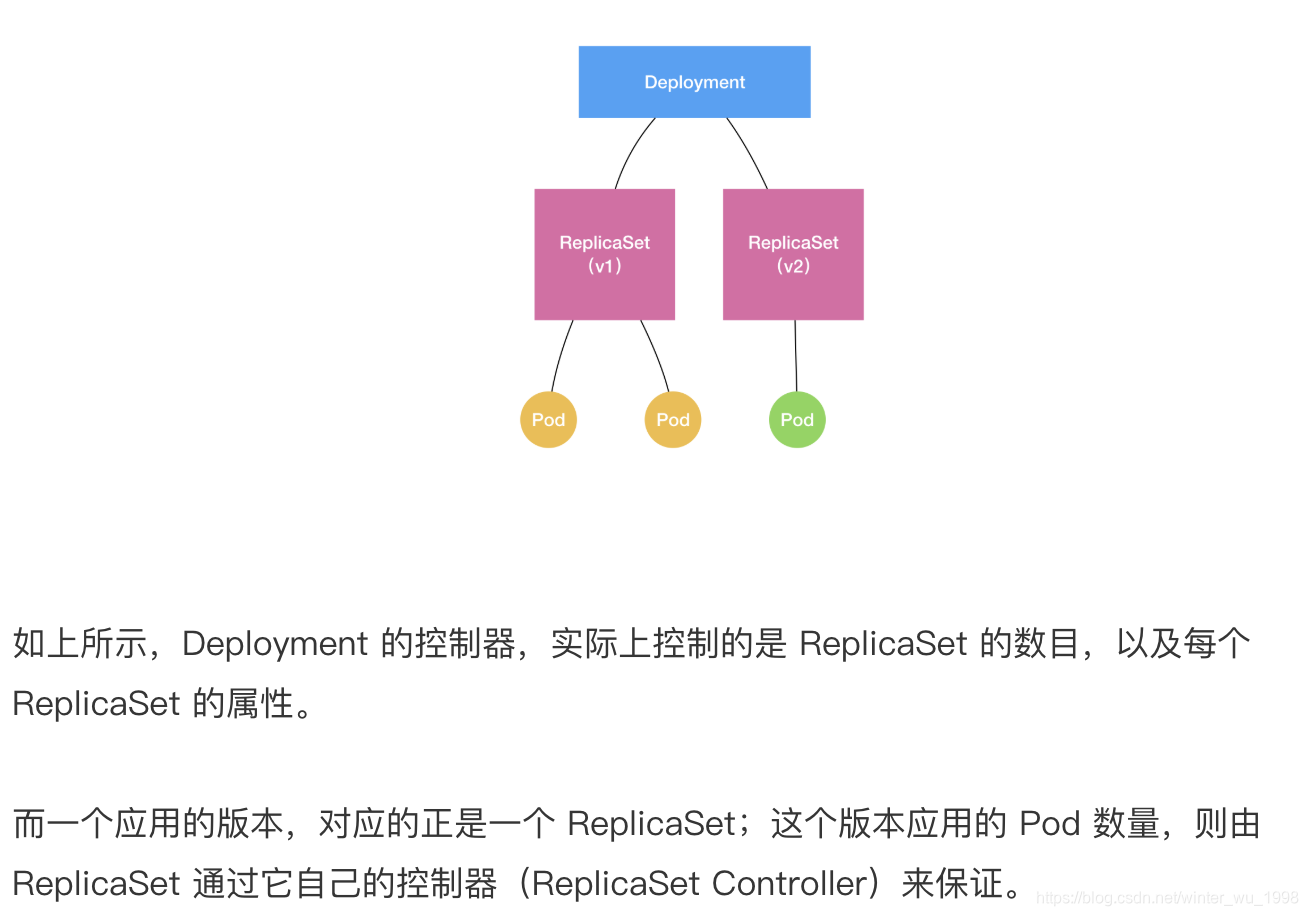
volume
- emptyDir
- 是host上的一个空目录
- 生存周期与pod一致
- 适合 Pod 中的容器需要临时共享存储空间的场景
- hostPath
- 挂载host上指定目录
- 生存周期与host一致
